案例2:优衣库销售数据分析
学习目标
- 掌握描述性数据分析流程
- 能够使用pandas、seaborn进行数据分析和可视化
1. 案例介绍
案例背景:
- 数据集中包含了不同城市优衣库门店的销售记录
- 通过对销售数据的分析,为运营提供一些有益信息
分析需求:
- 不同产品的销售情况,顾客喜欢的购买方式
- 销售额和成本之间的关系
- 购买时间偏好
数据集说明:
本案例使用 uniqlo.csv 数据集,其数据字段如下:
| 字段 | 说明 |
|---|---|
store_id |
门店随机id |
city |
城市 |
channel |
销售渠道:网购自提、门店购买 |
gender_group |
客户性别:男、女 |
age_group |
客户年龄段 |
wkd_ind |
购买发生的时间:周末、周间 |
product |
产品类别 |
customer |
客户数量 |
revenue |
销售金额 |
order |
订单数量 |
quant |
购买产品的数量 |
unit_cost |
成本(制作+运营) |
2. 加载数据
1)加载 uniqlo.csv 数据,并查看数据的基本情况
import pandas as pd
uniqlo = pd.read_csv('./data/uniqlo.csv')
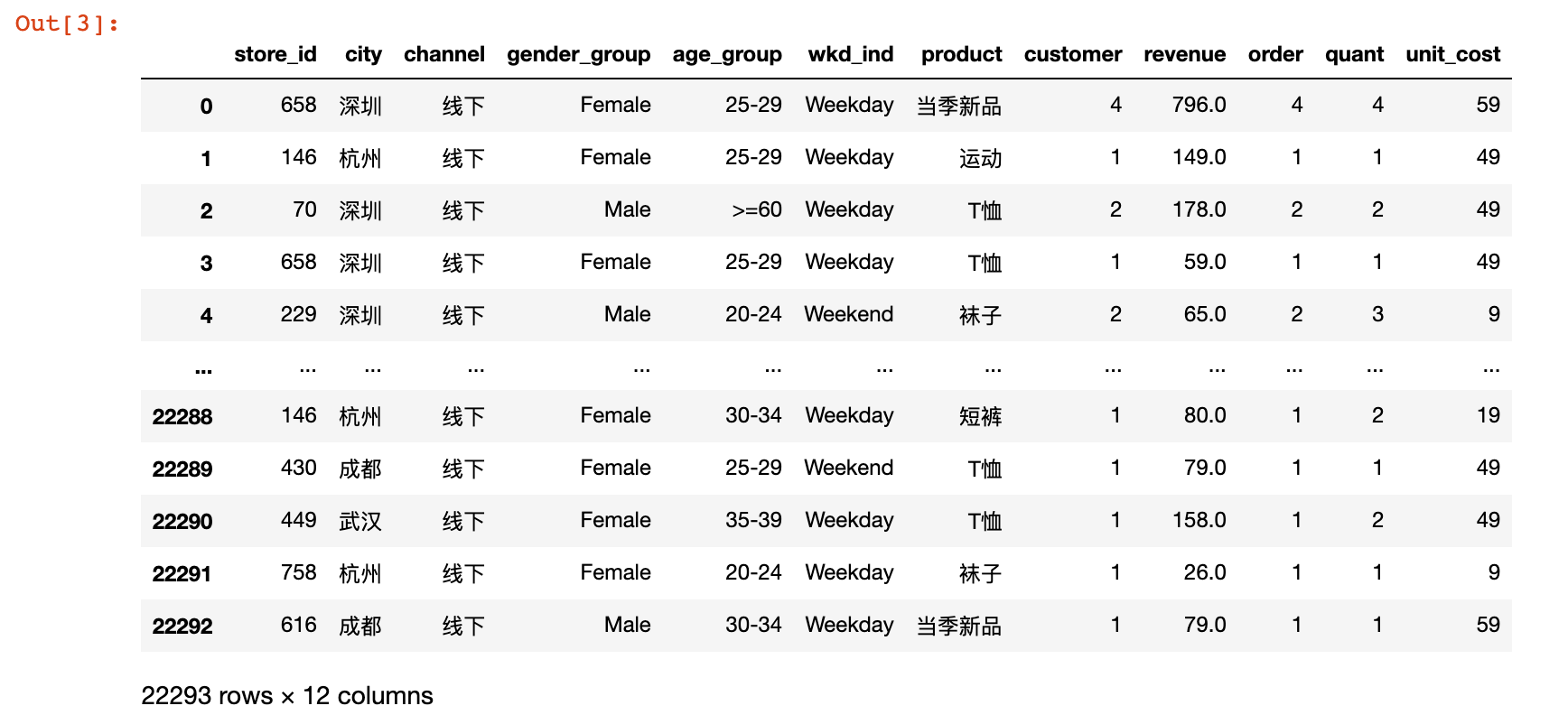
uniqlo
# 查看数据的字段信息
uniqlo.info()
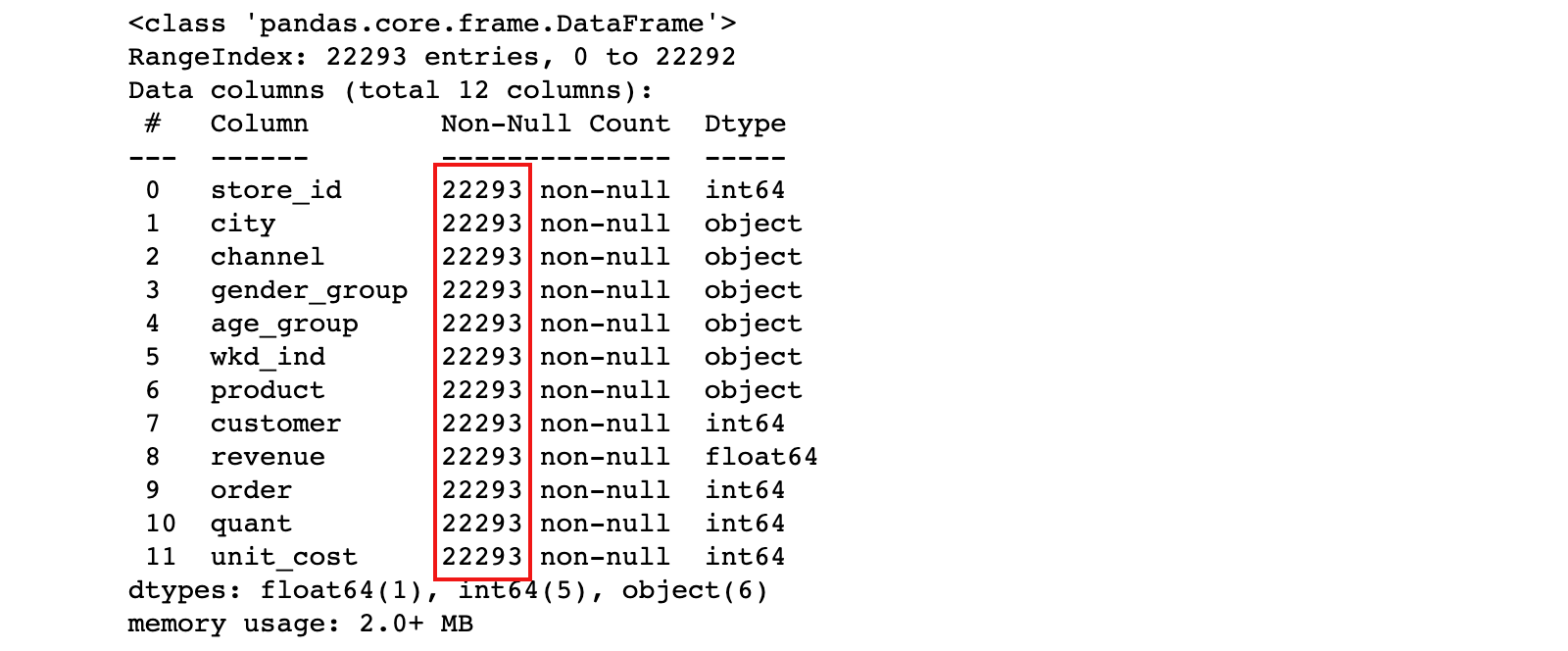
结果说明:从上面结果中看出,数据没有缺失
# 查看数据字段的统计信息
uniqlo.describe()
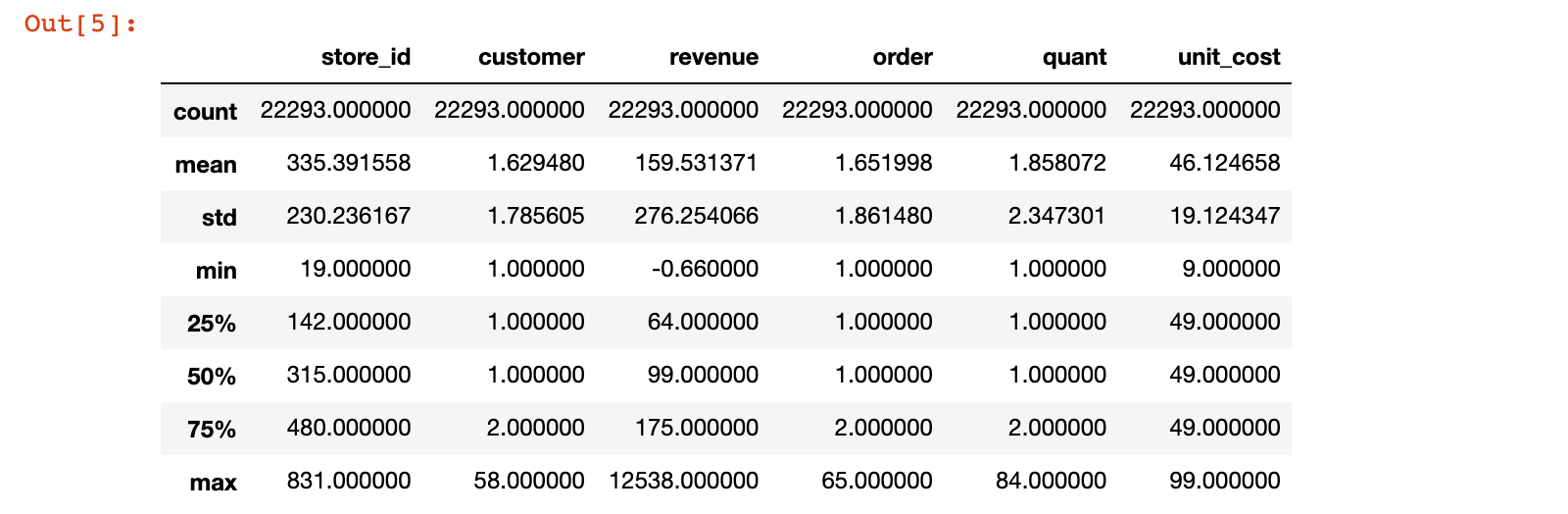
结果说明:从结果中看出,revenue 销售金额,有异常值,-0.66 / 12538,可以进一步查看
# 查看销售金额小于1的数据信息
uniqlo[uniqlo.revenue<1]
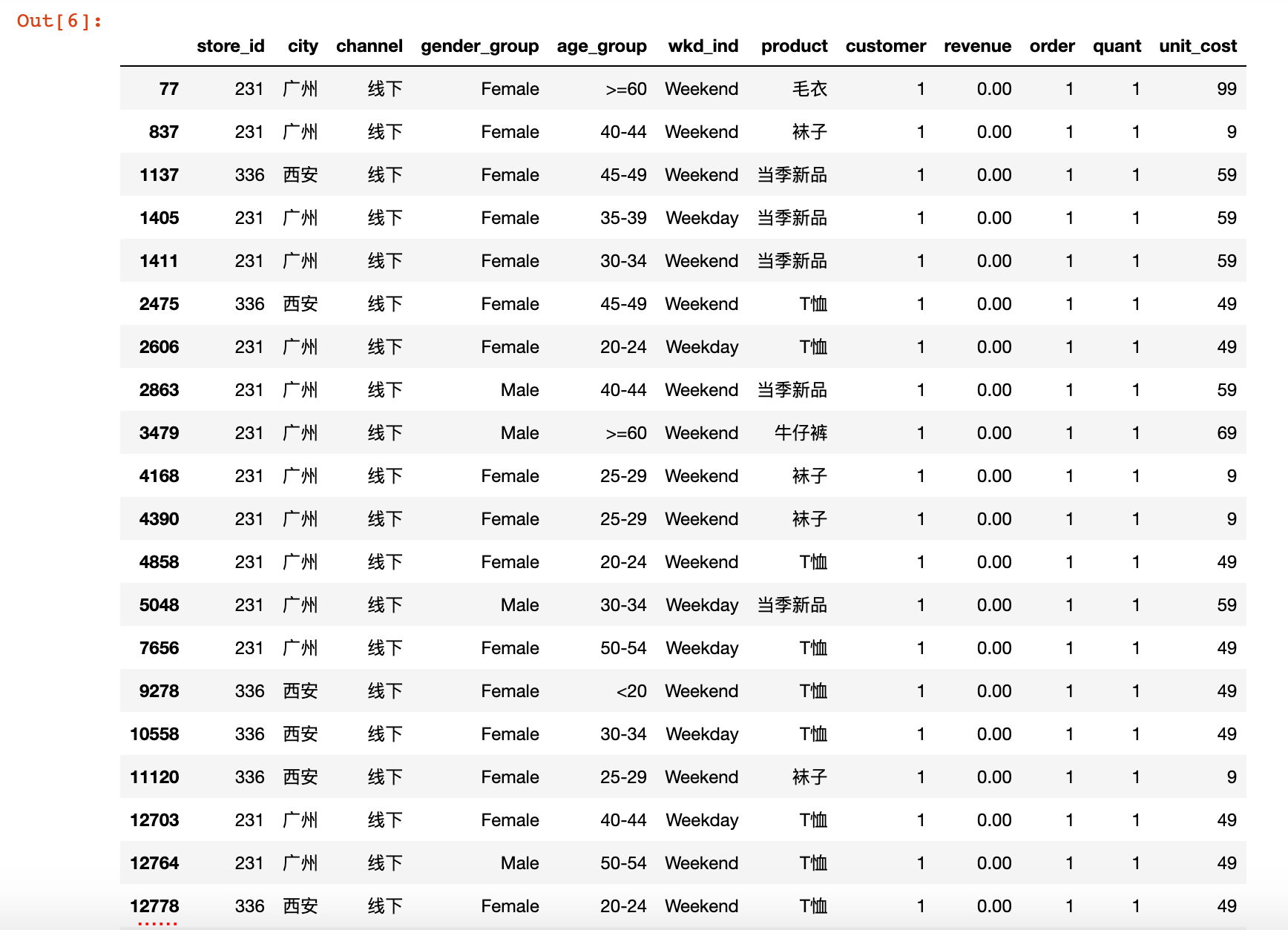
结果说明:进一步查看之后发现,一部分订单收入为0,可能为赠品,收入小于0的订单只有一个,实际工作中可以跟业务方核对数据
# 查看销售金额大于5000的数据信息
uniqlo[uniqlo.revenue>5000]
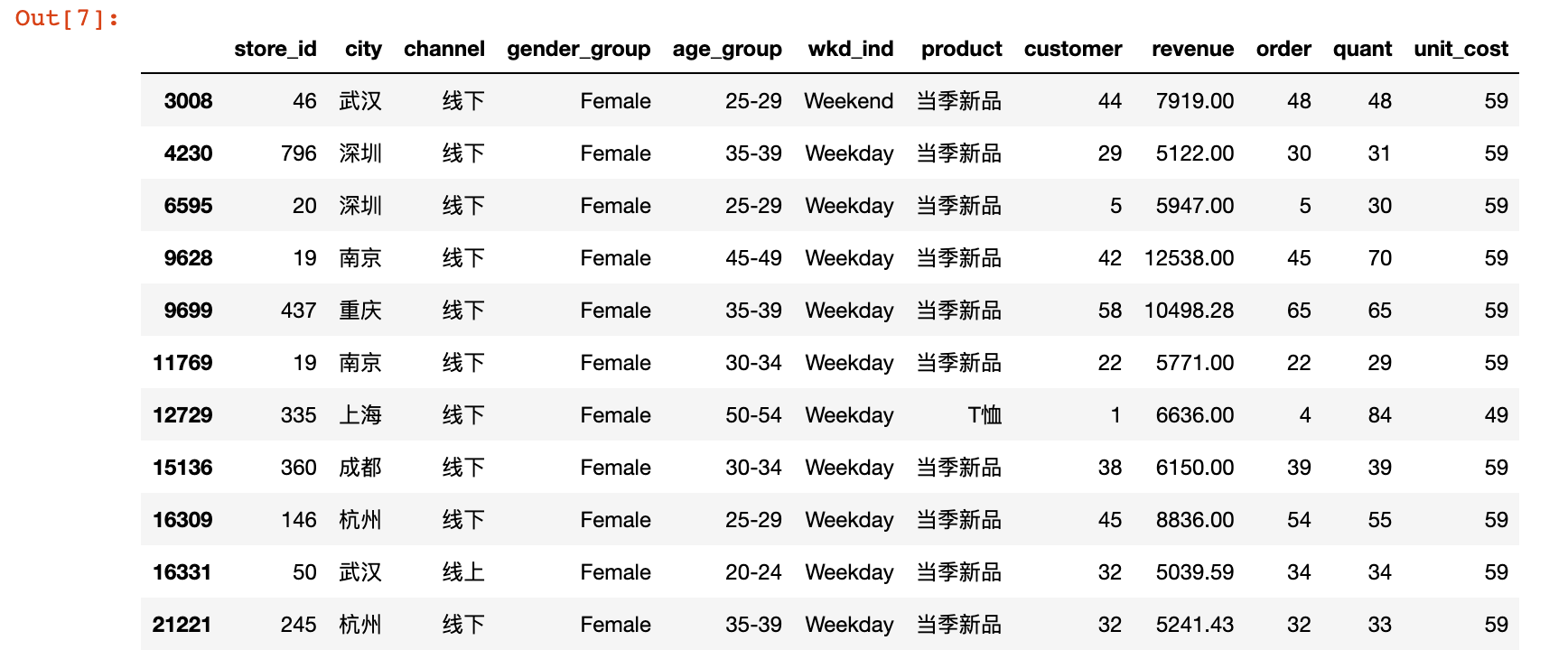
结果说明:查看后发现均为消费多件导致金额较高,数据没有问题
3. 业务解读
3.1 不同产品的销售情况
1)统计不同种类产品的订单情况
# 统计不同种类产品的订单情况
uniqlo.groupby('product')['order'].sum().sort_values(ascending=False)

结果说明:可以看出,T恤销售记录条数最多,其次是当季新品,袜子...
2)统计不同种类产品的销量
# 统计不同种类产品的销量
uniqlo.groupby('product')['quant'].sum().sort_values(ascending=False)

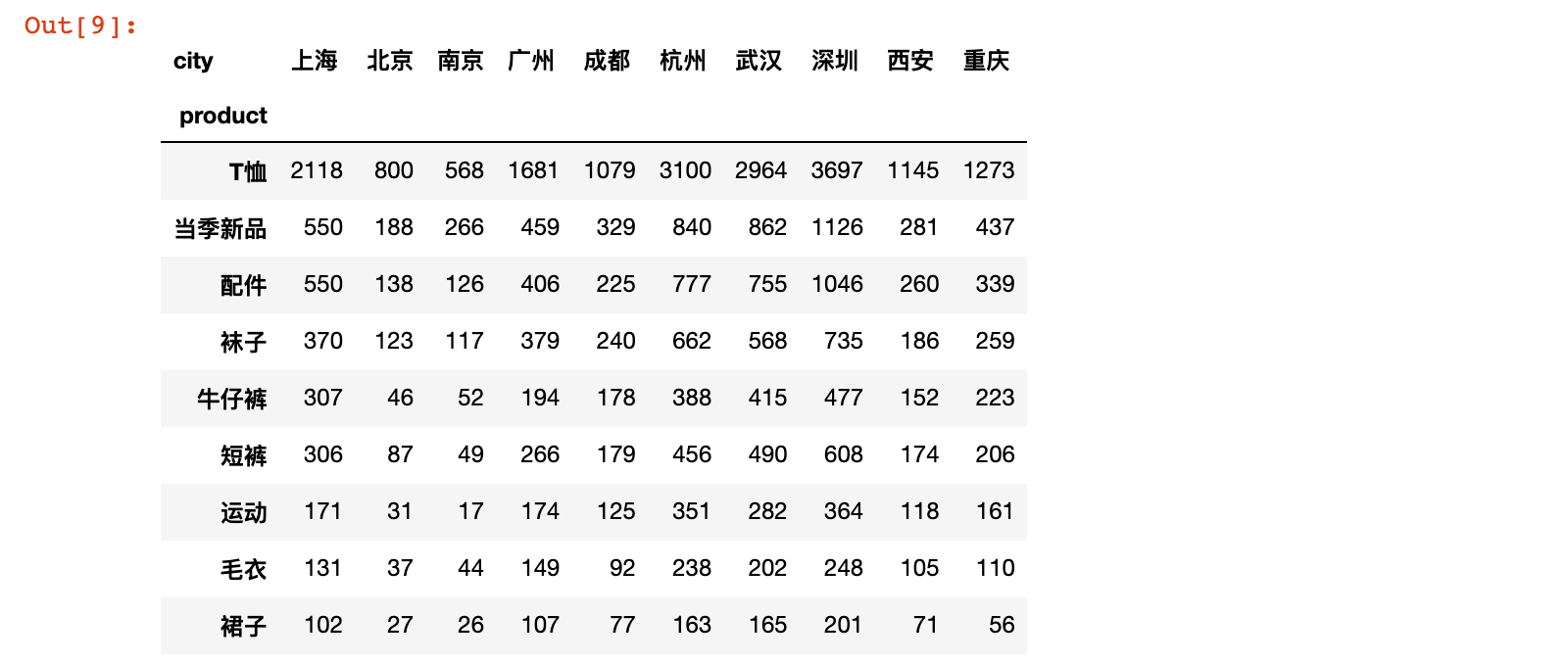
# 进一步拆解,按城市拆解销量
uniqlo.pivot_table(values='quant',
index='product',
columns='city',
aggfunc='sum').sort_values('上海', ascending=False)
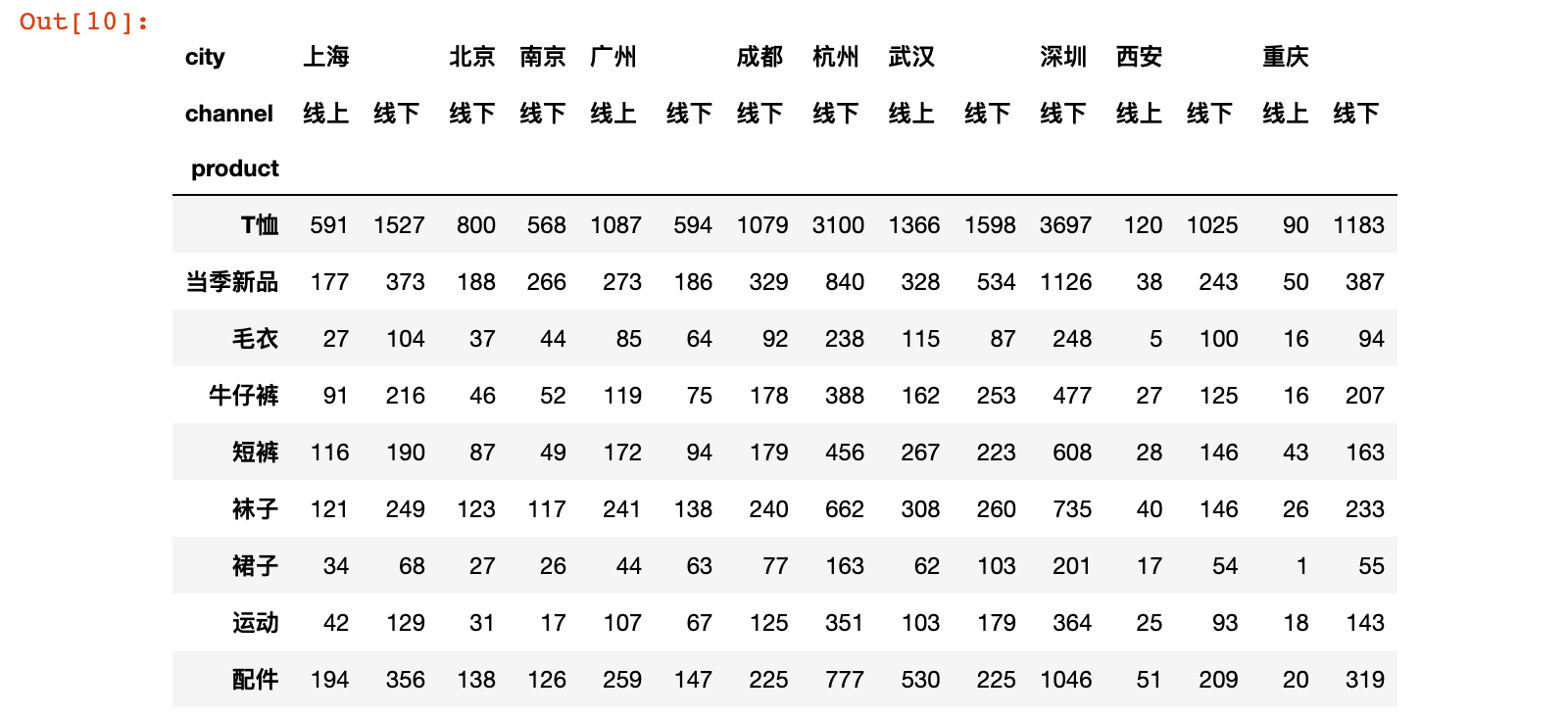
# 对城市拆解后,再进一步按线上线下拆解
uniqlo.pivot_table(values='quant',
index='product',
columns=['city', 'channel'],
aggfunc='sum')
3.2 用户习惯使用哪种方式进行消费
1)统计使用不同消费方式的订单数量
# 统计使用不同消费方式的订单数量
uniqlo.groupby('channel').order.sum()

结果说明:从数据中看出,线下消费记录更多,线上较少
# 进一步按城市拆解
uniqlo.pivot_table(index='city', columns='channel',
values='order', aggfunc='sum').sort_values('线上', ascending=False)
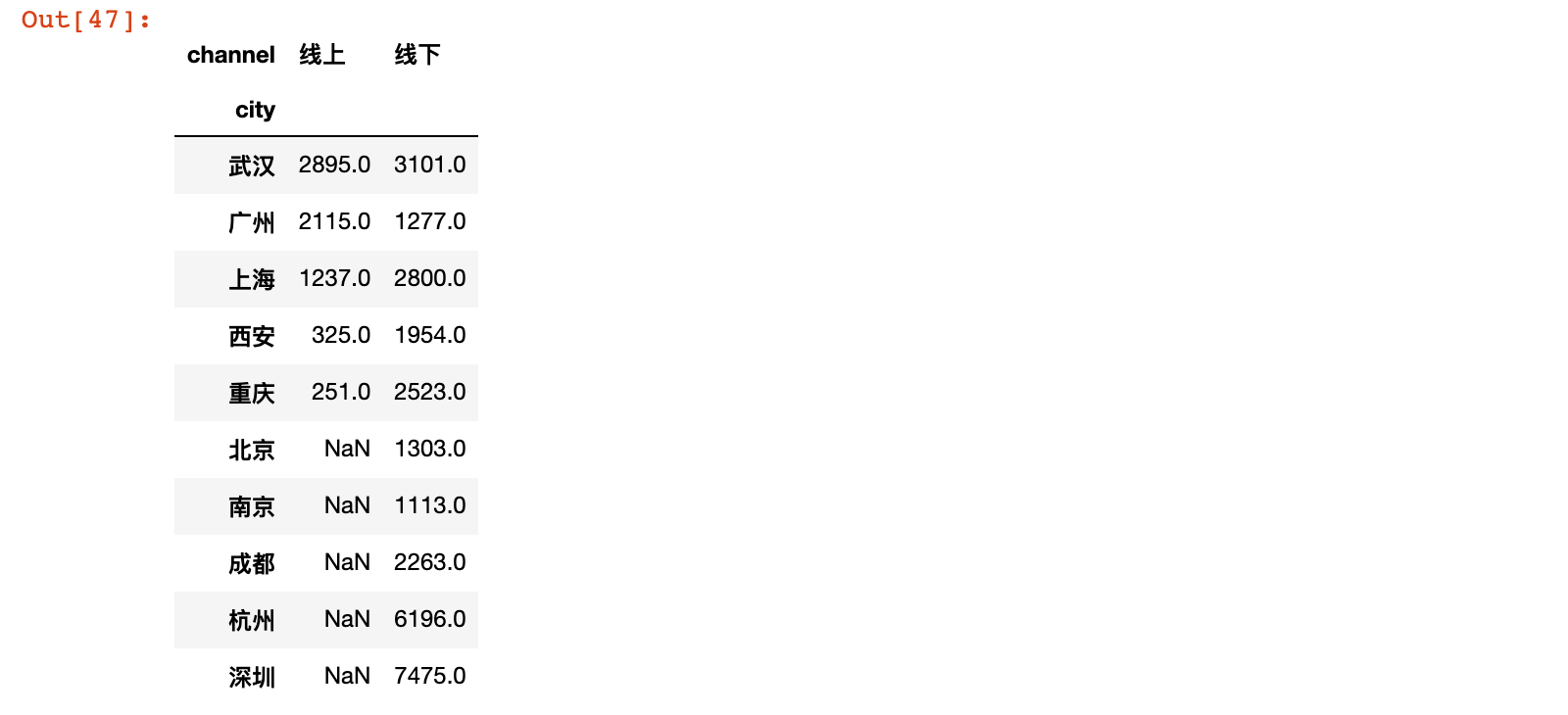
结果说明:数据中发现,并不是所有的城市都有线下,有些城市线上订单数大于线下订单数,比如广州
# 进一步计算线上线下销售额
uniqlo.pivot_table(values='quant', index='city',
columns='channel', aggfunc='sum')
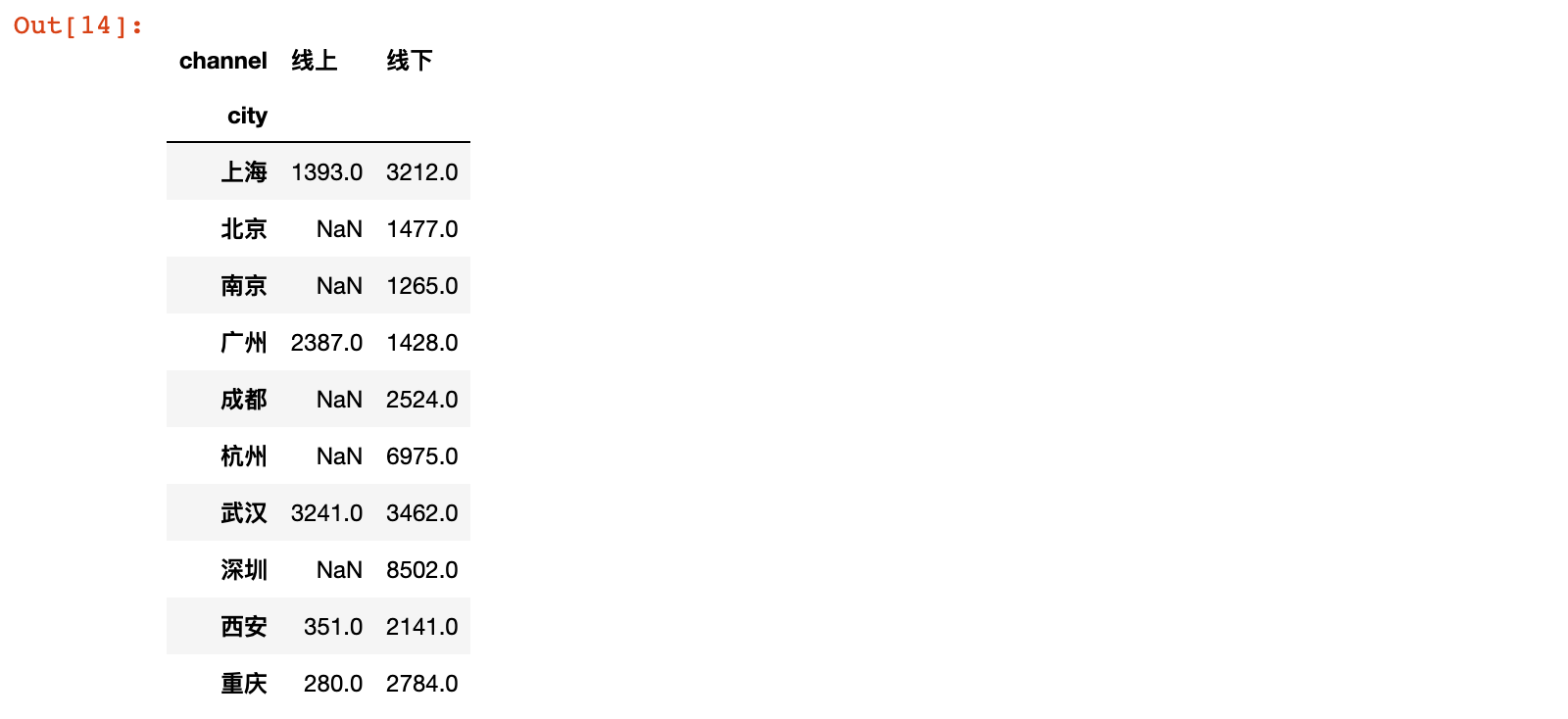
结果说明:从结果中得出广州销售额线上>线下,武汉线上线下比较接近,北京、南京、成都、杭州、深圳没有线上
3.3 用户消费习惯(周间还是周末)
1)统计用户周间、周末消费的整体情况
# 统计用户周间、周末消费的整体情况
uniqlo.wkd_ind.value_counts()

结果说明:整体情况上看,周间数据条目数量>周末数量,但周间有5天,所以整体看周末日均销售情况好于周间
2)通过数据透视表,查看不同城市周间、周末销量情况
wkd_sales = uniqlo.pivot_table(values='quant', index='wkd_ind',
columns='city', aggfunc='sum')
wkd_sales

# 添加字段:计算每天的销售额
wkd_sales.loc['weekday_avg', :] = wkd_sales.loc['Weekday', :] / 5
wkd_sales.loc['weekend_avg', :] = wkd_sales.loc['Weekend', :] / 2
wkd_sales
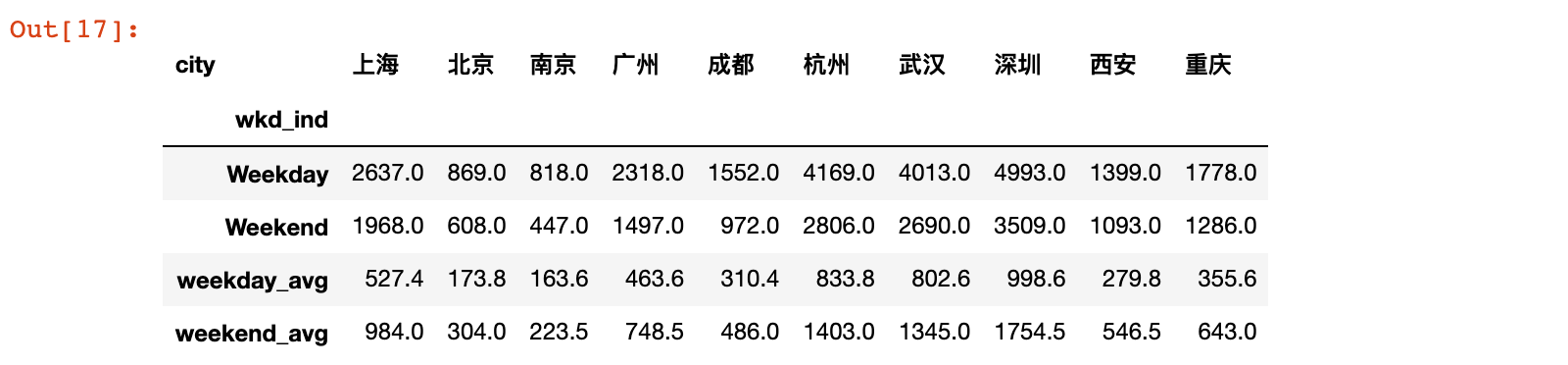
结果说明:可以看出每个城市周间周末平均消费订单数量的情况
3.4 销售额和成本之间的关系
1)销售额 revenue 和 unit_cost 成本之间的关系,先直接计算皮尔逊相关系数
# 计算销售额和成本之间的相关系数
uniqlo[['revenue', 'unit_cost']].corr()

结果说明:从结果中查看发现,貌似没有关系
# 进一步查看 unit_cost
uniqlo.unit_cost.value_counts()
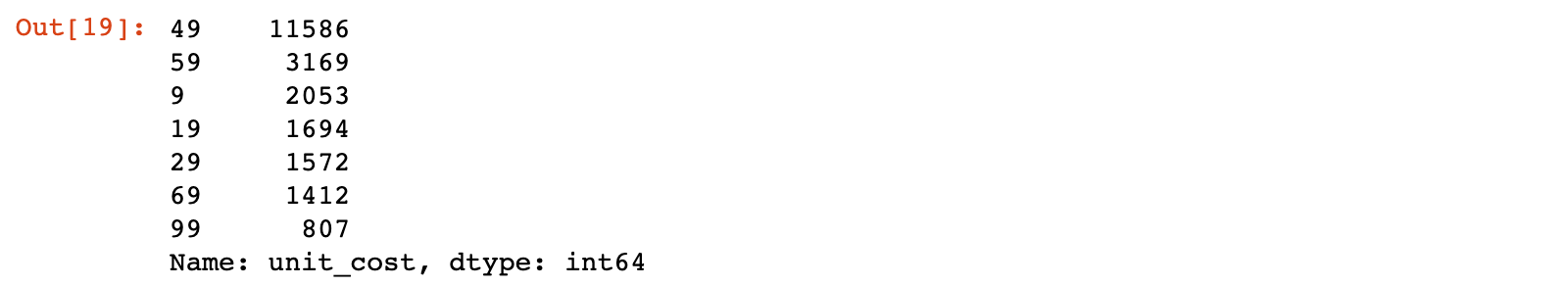
结果说明:查看发现 unit_cost 为单位商品的成本,但是 revenue 不一定是一件物品的收入,需要处理数据
# 筛选出销售额大于 1 的数据
uniqlo2 = uniqlo[uniqlo.revenue > 1]
uniqlo2.head()
# 添加单件收入列,并计算单件收入和单位成本计算相似度
uniqlo2['rev_per_goods'] = uniqlo2['revenue'] / uniqlo2['quant']
uniqlo2[['rev_per_goods','unit_cost']].corr()

结果说明:从结果中看出,单件收入和单位成本之间相关性还是比较强的
# 绘制热力图
sns.heatmap(uniqlo2[['rev_per_goods', 'unit_cost']].corr())

总结
- 数据分析的过程中,多维度拆解是很重要的分析思路,在分析产品销售情况的时候,案例中分别按城市,按线上线下进行拆解,实际上还可以从更多的维度进行拆解,比如年龄、性别等均可以拆解,拆解之后可以获得更多信息
- 使用seaborn进行可视化代码比较简洁,还自带了简单的统计功能,比如countplot
- 透视表(pivot_table)和分组聚合(groupby aggragation)功能类似,都可以从不同角度来观察数据