数据整理
学习目标
- 掌握melt函数整理数据的方法
- 掌握stack、unstack的用法
- 掌握wide_to_long函数的用法
1. melt整理数据
1.1 宽数据集变为长数据集
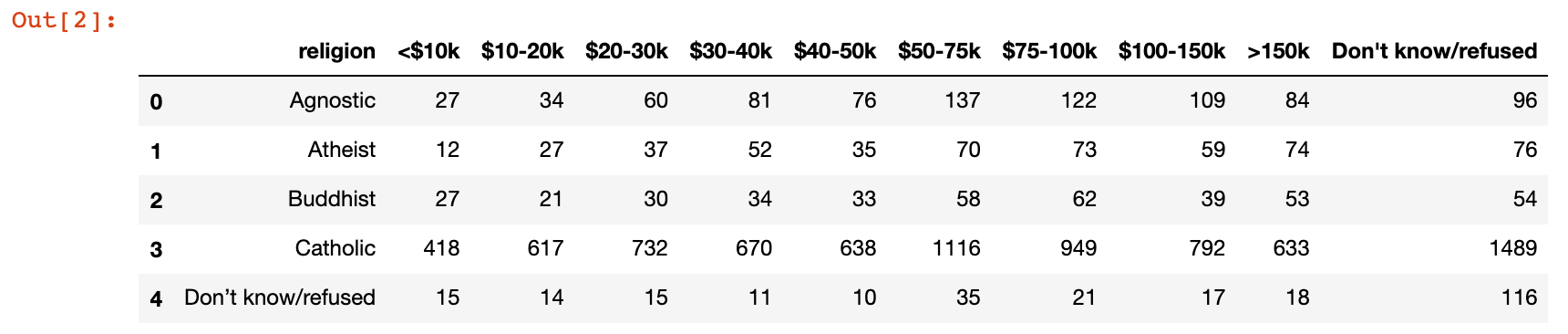
1)加载美国收入与宗教信仰数据 pew.csv
pew = pd.read_csv('./data/pew.csv')
pew.head()
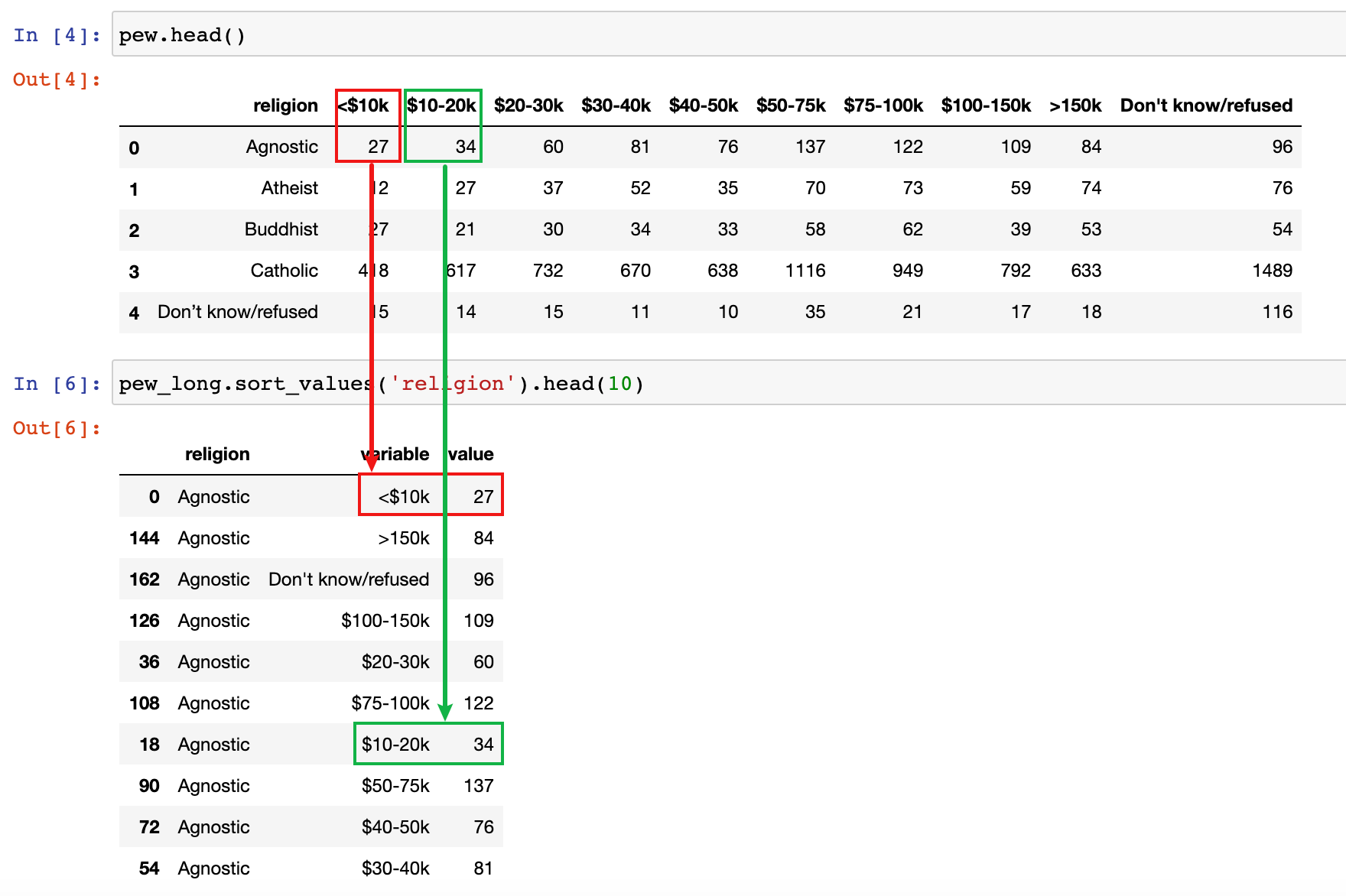
2)先执行下面的代码,将输出的结果和上面的输出结果进行对比
pew_long = pd.melt(pew, id_vars=['religion'])
pew_long
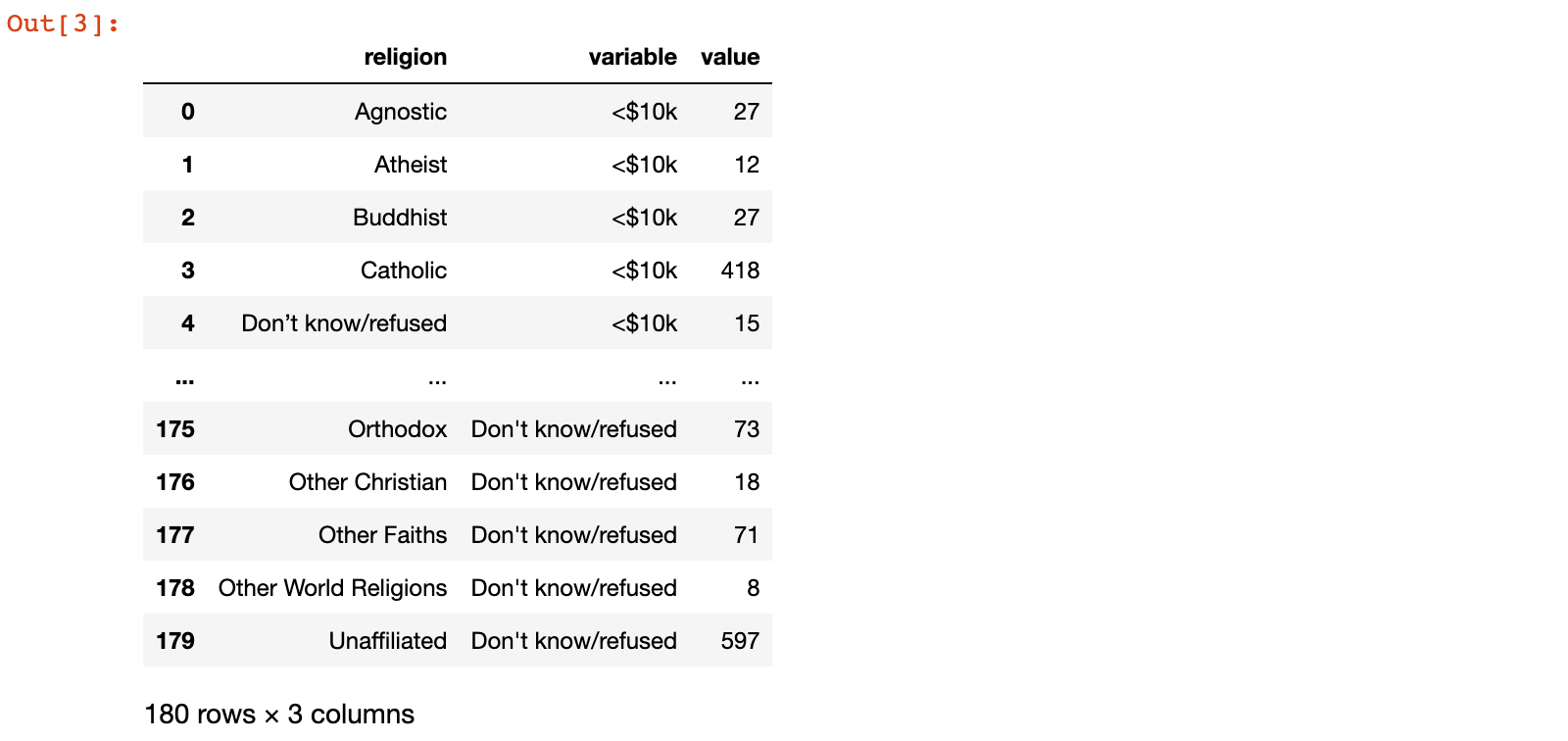
结果说明:
1)我们发现,基于religion列,把原来的df拉长了,我们称原来的df为宽数据集,拉长之后的df称之为长数据集
- 对于展示数据而言,下图中
pew返回的这种"宽"数据没有任何问题,如第一行数据,展示了Agnostic(不可知论(者))所有的收入分布情况 - 从数据分析的角度,有时候我们需要把数据由"宽"数据,转换成"长"数据,就如同下图中
pew_long返回的数据 - 在pandas中我们就可以使用
df.melt()函数,通过各种参数,来达成宽数据集转换为长数据集的效果
1.2 melt 函数的参数
melt 是溶解/分解的意思, 即拆分数据;melt即是类函数也是实例函数,也就是说既可以用pd.melt(), 也可使用dataframe.melt()
| 参数 | 类型 | 说明 |
|---|---|---|
| frame | dataframe | 必要参数,被 melt 的数据集名称在 pd.melt() 中使用,比如上例中pd.melt(pew, id_vars='religion')的pew |
| id_vars | tuple/list/ndarray | 可选项,不需要被转换的列名,在转换后作为标识符列(不是索引列),比如上例pd.melt(pew, id_vars='religion') |
| value_vars | tuple/list/ndarray | 可选项,需要被转换的现有列,如果未指明value_vars,除id_vars指定的其他列都将被转换 |
| var_name | string | 自定义设置variable列的列名 |
| value_name | string | 自定义设置value列的列名 |
1)比如,可以更改 melt 之后的数据的列名
pew_long = pd.melt(pew, id_vars=['religion'], var_name='income', value_name='count')
pew_long.head()

1.3 练习
需求:
加载 data/billboard.csv,将歌曲周排行数据集拆分成2个数据集:
- 数据集1:保存歌曲的基本信息
- 数据集2:保存歌曲的每周排行信息
- 要求两个数据集以一个
id列,在逻辑上互相关联
1.3.1 加载并观察数据集
1)加载数据
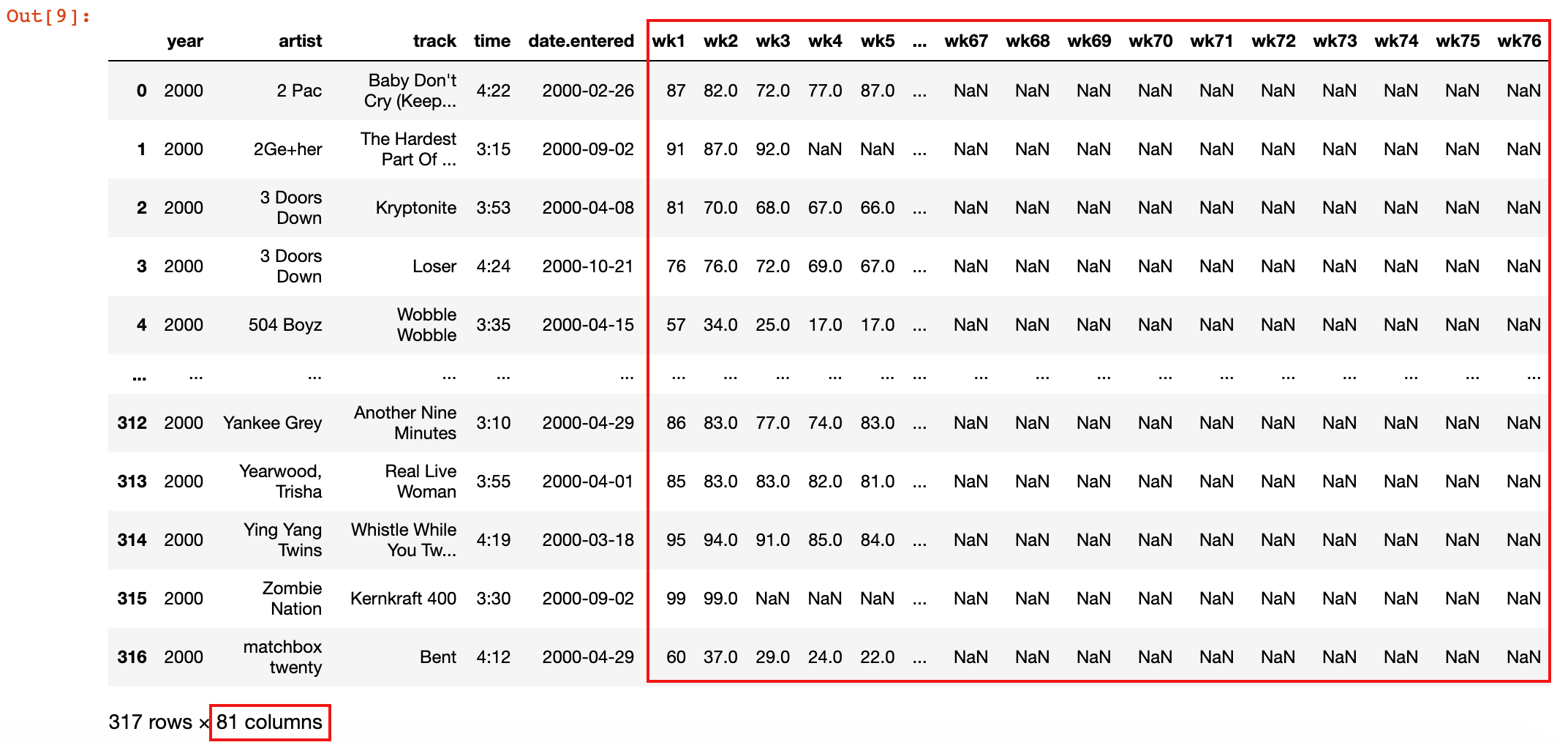
bill_board = pd.read_csv('./data/billboard.csv')
bill_board.head()
2)经观察思考,最终结果如下图
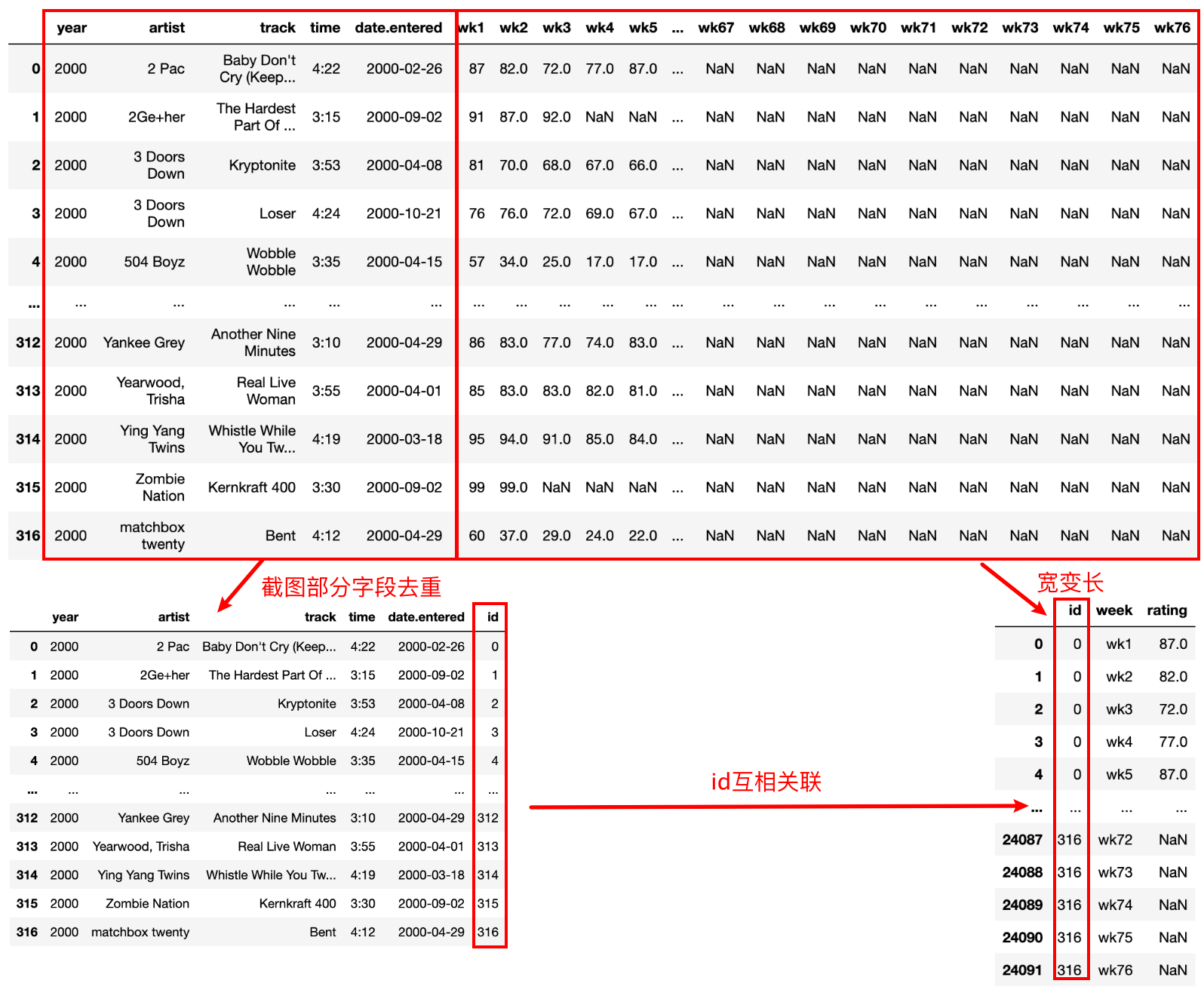
3)实现思路如下:
- 变换为长数据集
- 提取歌曲信息表并添加歌曲id列
- 长数据集添加歌曲id
- 提取每周评分数据表
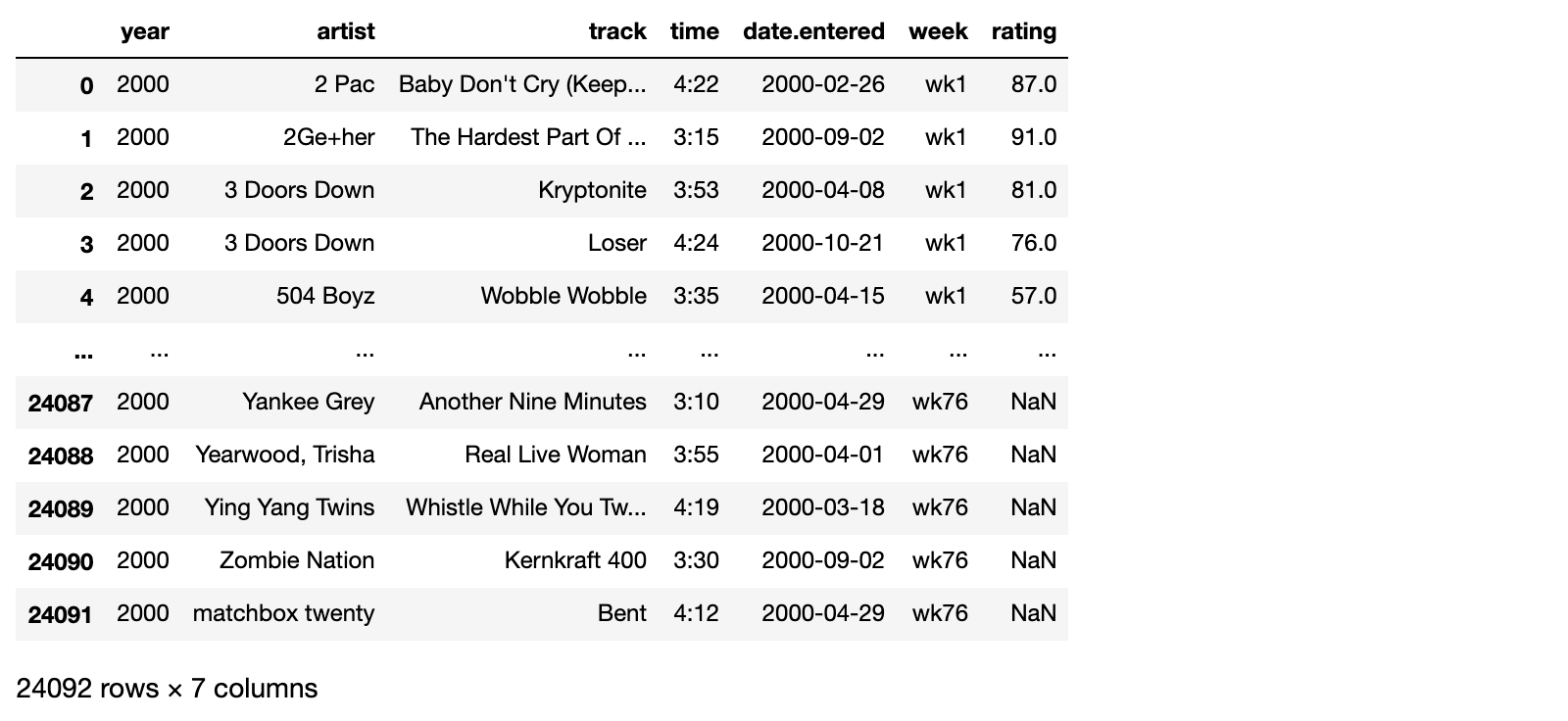
1.3.2 变换为长数据集
1)对上面数据的周评分进行处理,转换成长数据
billboard_long = pd.melt(billboard,
id_vars=['year', 'artist', 'track', 'time', 'date.entered'],
var_name='week',
value_name='rating')
billboard_long
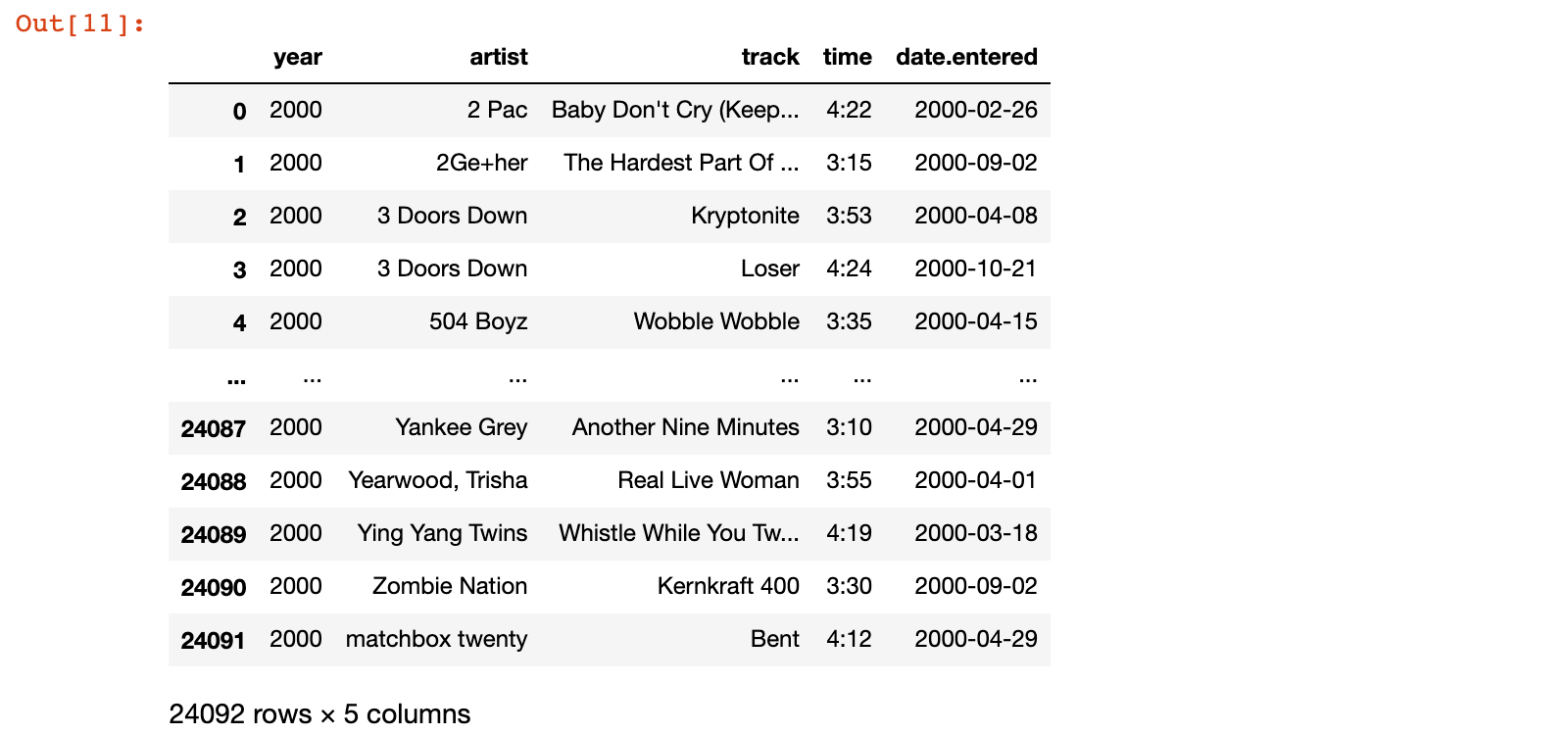
1.3.3 提取歌曲信息表并添加歌曲id列
1)取出指定的列,生成歌曲信息表
billboard_songs = billboard_long[['year', 'artist', 'track', 'time', 'date.entered']]
billboard_songs
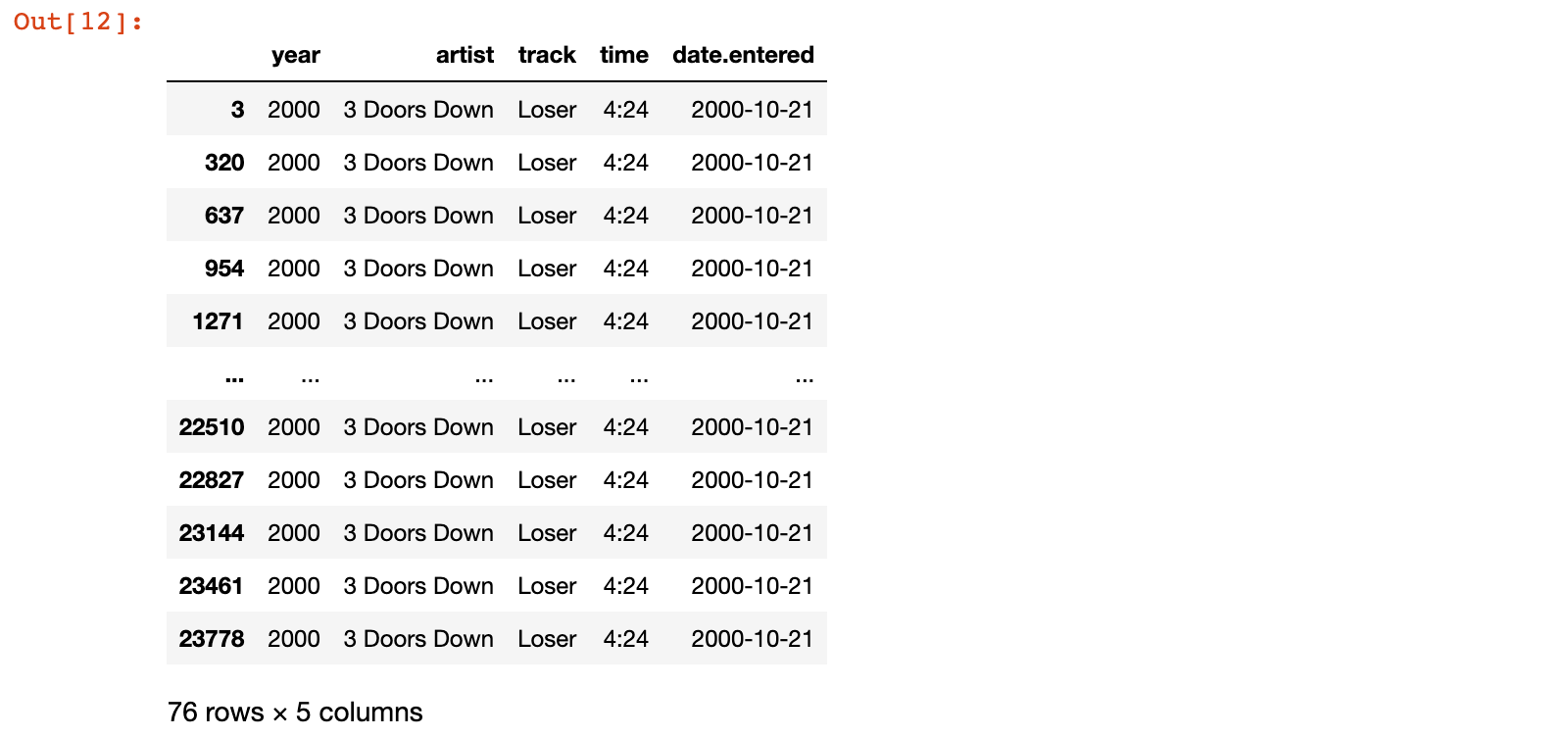
2)此时,当我们查询任意一首歌曲信息时,会发现数据的存储有冗余的情况
# 以歌曲名字Loser为例,发现歌曲信息表中有很多重复的数据
billboard_songs[billboard_songs.track=='Loser']
3)对歌曲信息表进行去重
billboard_songs = billboard_songs.drop_duplicates()
billboard_songs
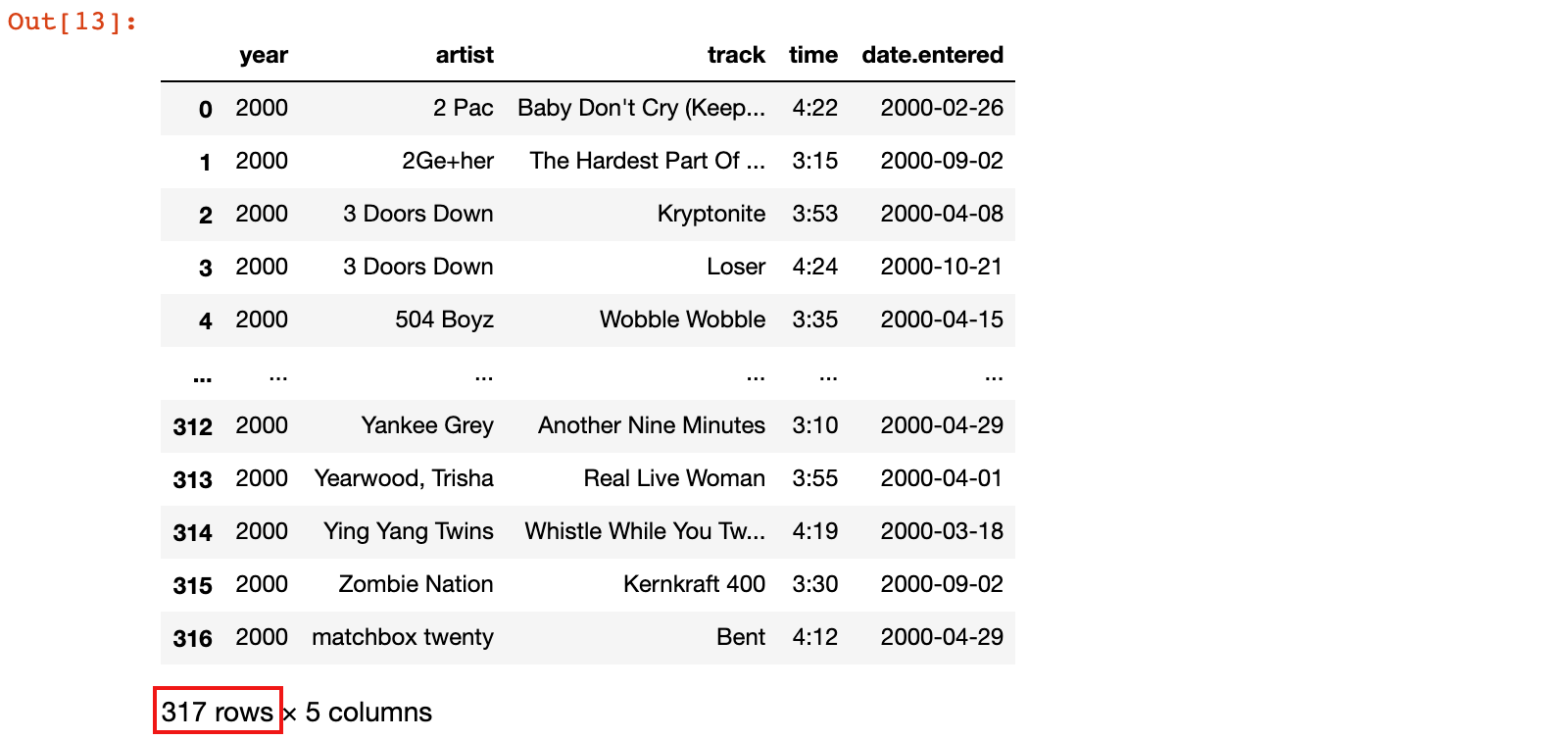
4)歌曲信息表添加id列
billboard_songs['id'] = range(len(billboard_songs))
billboard_songs
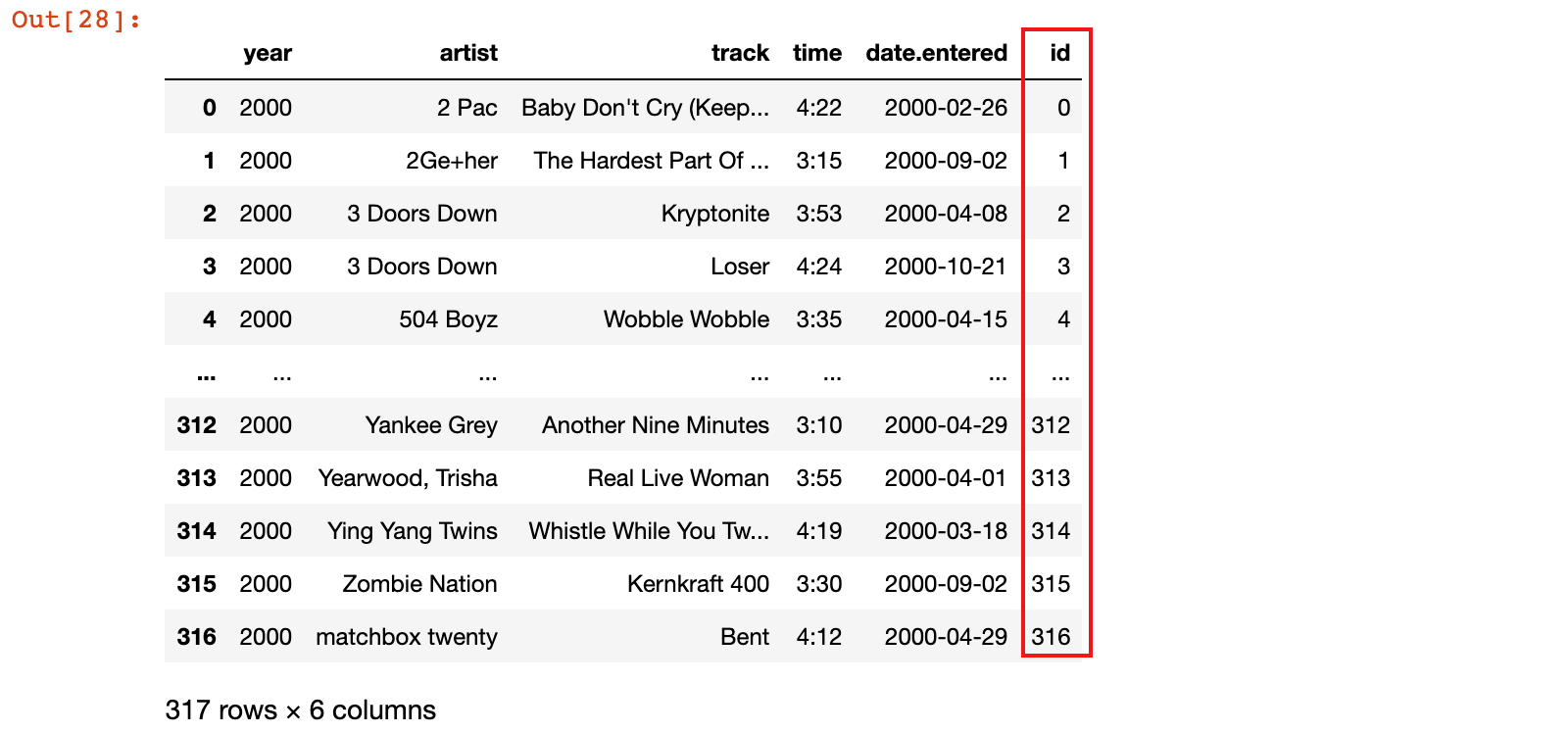
1.3.4 长数据集添加歌曲id
1)将歌曲信息表中的歌曲id关联到原始的长数据集中
# 原长数据集与歌曲信息表进行merge合并,基于指定的的字段,这样就歌曲id放到了长数据集中
new_billboard_long = billboard_long.merge(billboard_songs,
on=['year', 'artist', 'track', 'time', 'date.entered'])
new_billboard_long
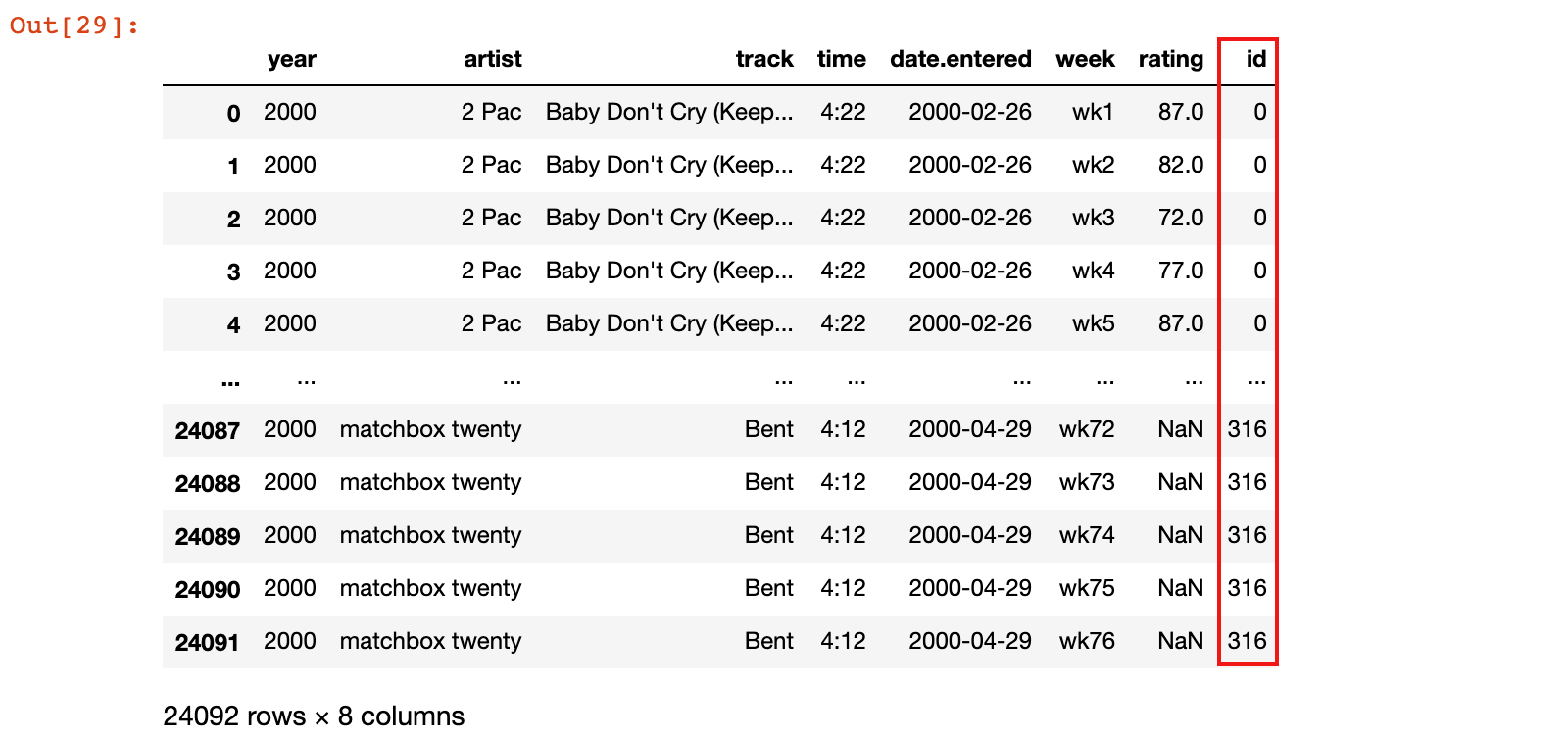
1.3.5 提取每周评分数据表
1)从有歌曲id的长数据集中,提取每周评分数据表
billboard_ratings = new_billboard_long[['id', 'week', 'rating']]
billboard_ratings

1.3.6 拆分数据集的作用
此时我们就完成了拆分数据集的需求,两个分开的数据集包含了两类数据:歌曲信息、周评分信息;随时可以基于歌曲id合并为完整的长数据集
billboard_songs.merge(billboard_ratings, on=['id'])

好处:拆分后的 2 个数据集在内存占用上,也比长数据集要少的多
print(billboard_songs.info(memory_usage='deep'))
print('='*10)
print(billboard_ratings.info(memory_usage='deep'))
print('='*10)
print(billboard.info(memory_usage='deep'))
print('='*10)
print(billboard_long.info(memory_usage='deep'))
# 输出结果如下
...
memory usage: 101.1 KB
...
memory usage: 2.0 MB
...
memory usage: 273.5 KB
...
memory usage: 7.9 MB
至此,我们完成这个练习:
2. stack 整理数据
2.1 stack 和 unstack 简介
pandas进行数据重排时,经常用到 stack 和 unstack 两个函数。stack 的意思是堆叠、堆积,unstack 即"不要堆叠"
常见的数据的层次化结构有两种,一种是表格,一种是"花括号",即下面这样的两种形式:
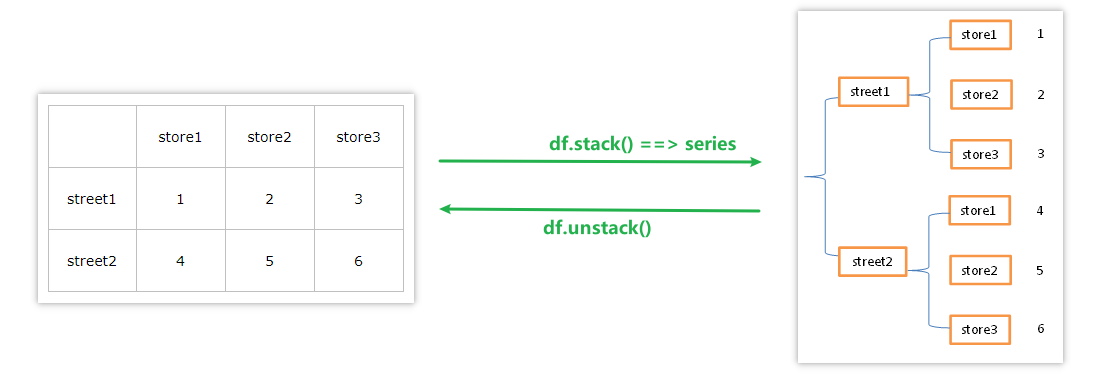
stack函数会将数据从表格结构 变成 花括号结构(返回的是series类型),即将其列索引变成行索引,反之,unstack函数将数据从 花括号结构变成 表格结构,即要将其中一层的行索引变成列索引。
2.2 stack 功能演示
1)加载 state_fruit.csv 数据集
state_fruit = pd.read_csv('./data/state_fruit.csv', index_col=0)
state_fruit

2)使用 stack 函数整理数据,查看效果:
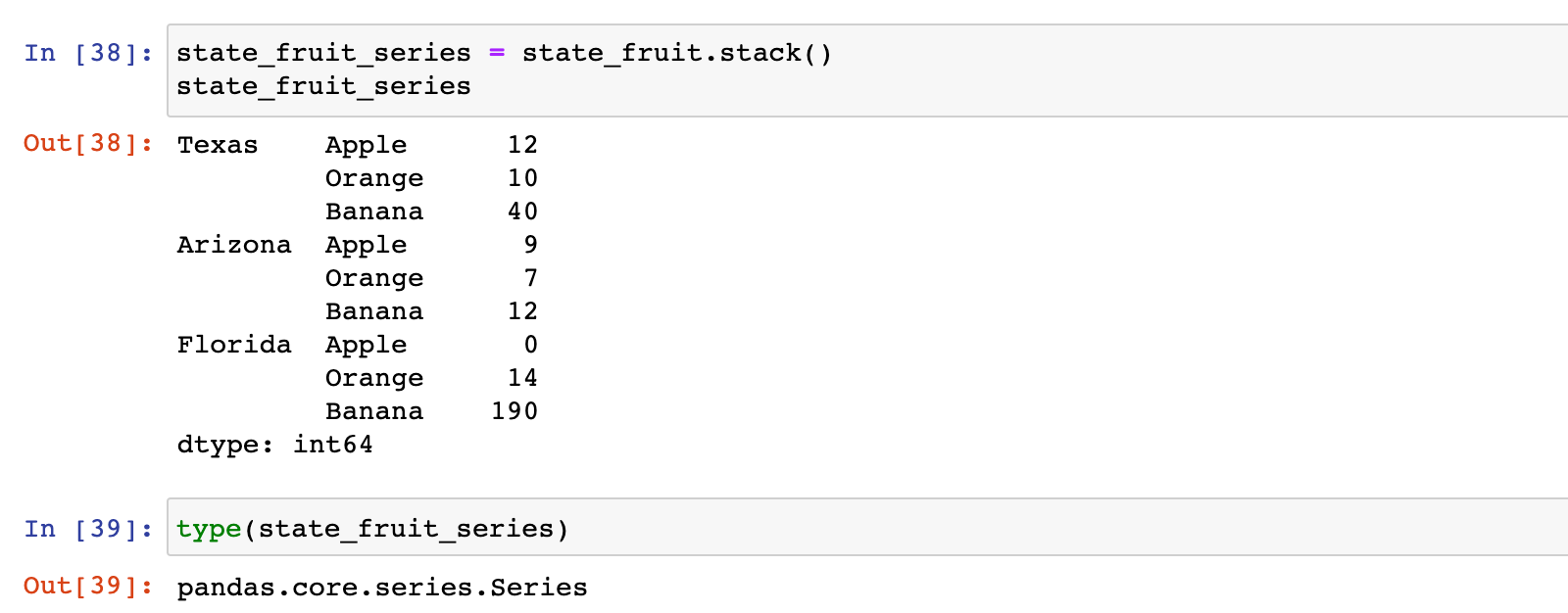
state_fruit_series = state_fruit.stack()
state_fruit_series
3)此时可以使用 reset_index(),将结果变为 DataFrame
state_fruit_tidy = state_fruit_series.reset_index()
state_fruit_tidy

4)给 columns 重新命名
state_fruit_tidy.columns = ['state', 'fruit', 'weight']
state_fruit_tidy

5)也可以使用 rename_axis 给不同的行标签索引层级命名
state_fruit.stack().rename_axis(['state', 'fruit'])

6)再次使用 reset_index
# 分别执行
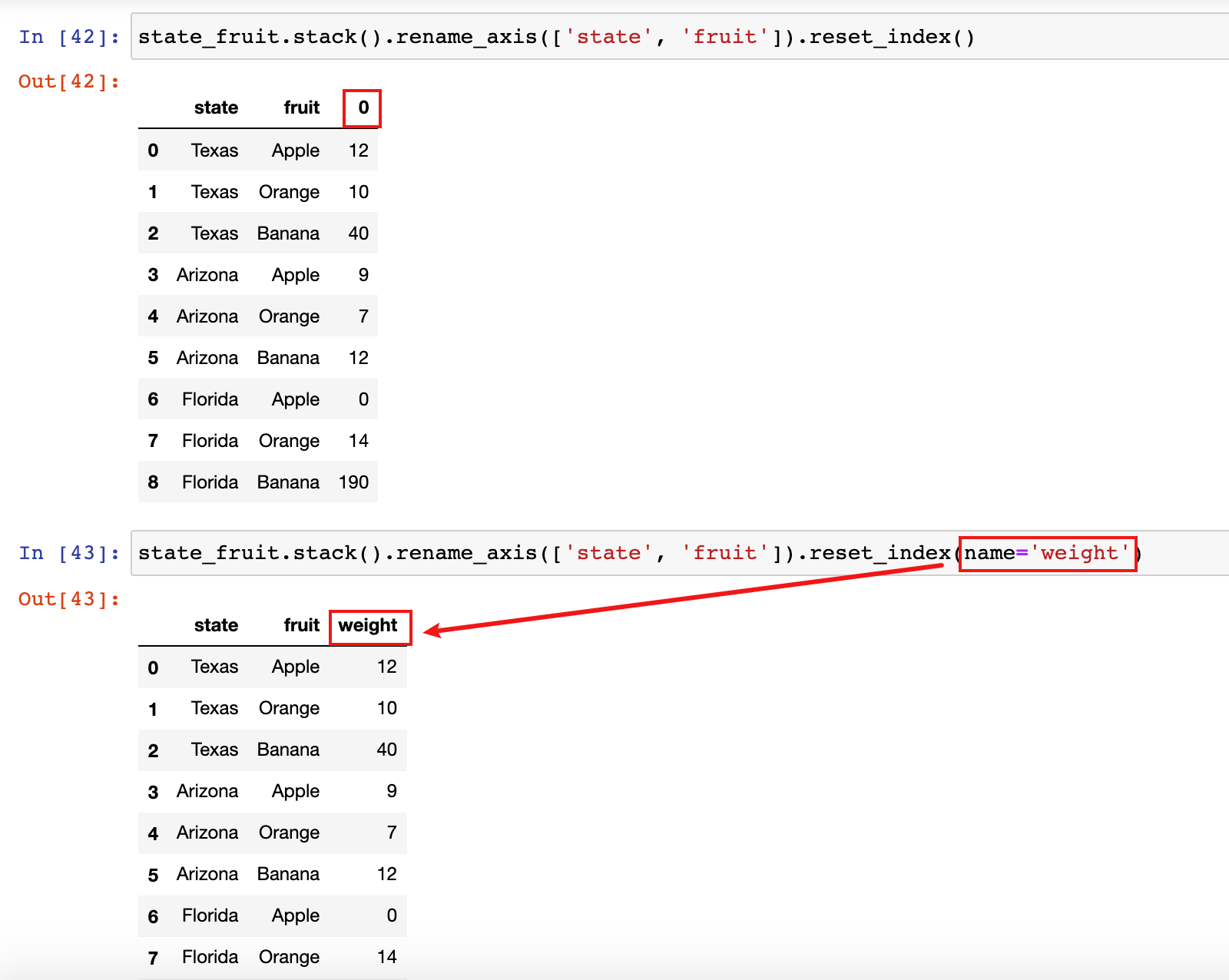
state_fruit.stack().rename_axis(['state', 'fruit']).reset_index()
state_fruit.stack().rename_axis(['state', 'fruit']).reset_index(name='weight')
2.3 unstack 功能演示
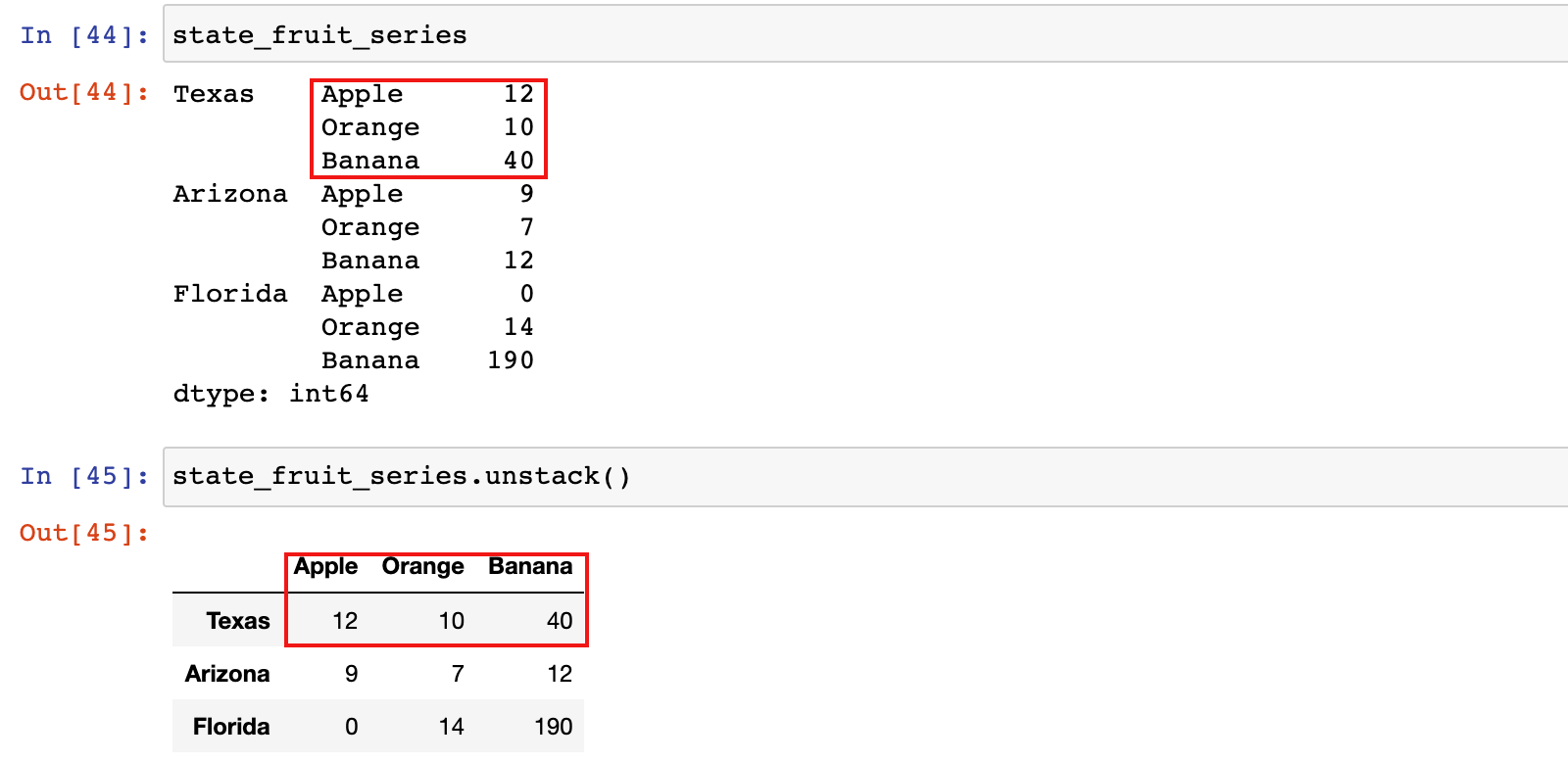
1)使用 unstack 函数
state_fruit_series.unstack()
3. wide_to_long 整理数据
wide_to_long函数的作用是将列名起始部分相同的列进行拆解,使宽数据变换为长数据
需求:
- 加载
data/movie.csv数据,统计每部电影的每个主演的被点赞数,返回新的df - 新df 的列名为
movie_title、actor_num、actor、actor_facebook_likes:分别代表电影名称、演员编号、演员姓名、该演员被点赞数
3.1 初步整理数据
1)加载 movie.csv 数据
movies = pd.read_csv('./data/movie.csv')
movies.head()
2)去除无关字段
movie_actors = movies[['movie_title', 'actor_1_name', 'actor_2_name', 'actor_3_name',
'actor_1_facebook_likes', 'actor_2_facebook_likes', 'actor_3_facebook_likes']]
movie_actors.head()
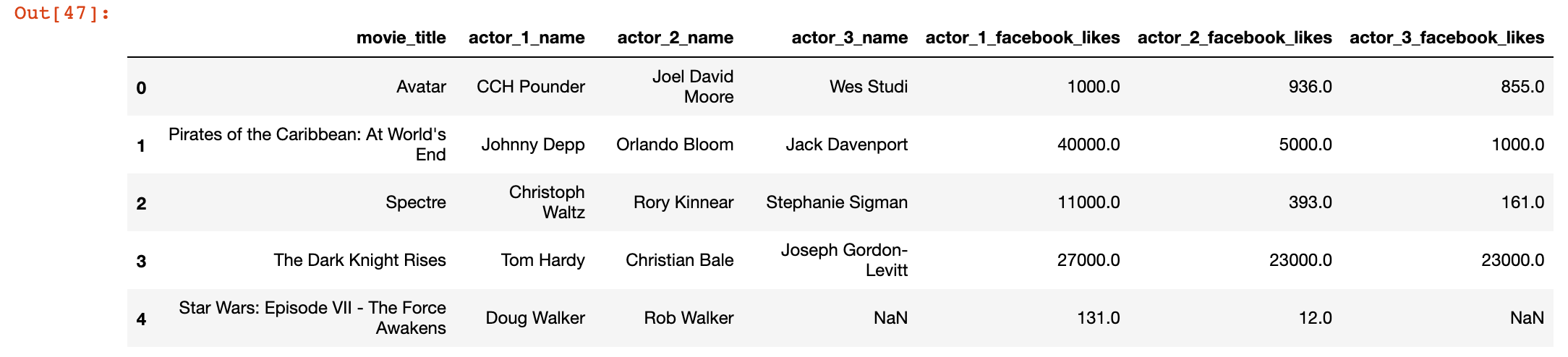
3)整理 columns 列名
movie_actors.columns = ['movie_title', 'actor_name_1', 'actor_name_2', 'actor_name_3',
'actor_facebook_likes_1', 'actor_facebook_likes_2', 'actor_facebook_likes_3']
movie_actors.head()

3.2 wide_to_long函数的具体使用
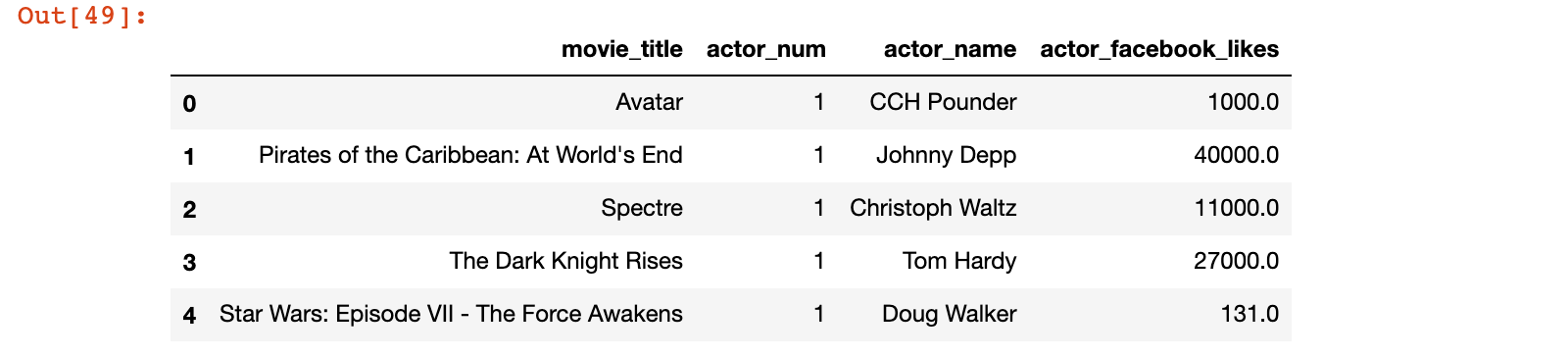
1)先执行下面的代码,观看输出结果:
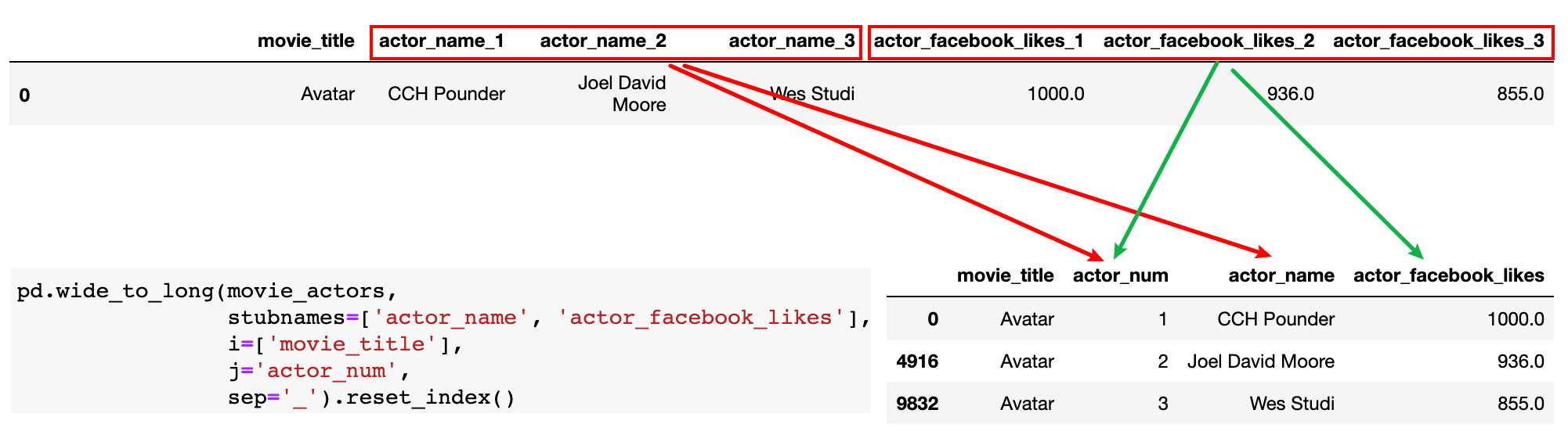
movie_actors_tidy = pd.wide_to_long(movie_actors,
stubnames=['actor_name', 'actor_facebook_likes'],
i=['movie_title'],
j='actor_num',
sep='_').reset_index()
movie_actors_tidy.head()
movie_actors_tidy[movie_actors_tidy.movie_title=='Avatar']
总结
- melt、stack、wide_to_long函数均可以实现将宽数据整理成长数据
- melt:指定数据列,将指定列变成长数据
- stack:返回一个具有多层级索引的数据,配合reset_index可以实现宽数据变成长数据
- wide_to_long:处理列名带数字后缀的宽数据
- stack/unstack, melt/pivot_table 互为逆向操作