数据透视表
学习目标
- 掌握 pandas 透视表(pivot_table)的使用方法
- 完成零售会员数据分析案例
1. pandas 透视表概述
数据透视表(Pivot Table)是一种交互式的表,可以进行某些计算,如求和与计数等。所进行的计算与数据跟数据透视表中的排列有关。
之所以称为数据透视表,是因为可以动态地改变它们的版面布置,以便按照不同方式分析数据,也可以重新安排行号、列标和页字段。每一次改变版面布置时,数据透视表会立即按照新的布置重新计算数据。另外,如果原始数据发生更改,则可以更新数据透视表。
在使用 Excel 做数据分析时,透视表是很常用的功能,pandas 也提供了透视表功能,对应的 API 为 pivot_table
pandas pivot_table 函数介绍:
| 方法 | 说明 |
|---|---|
pd.pivot_table(df, ...) |
进行透视表操作 |
df.pivot_table(...) |
进行透视表操作 |
pivot_table 最重要的四个参数 values、index、columns、aggfunc,下面通过案例介绍 pivot_tabe 的使用
2. 零售会员数据分析案例
2.1 案例业务介绍
业务背景介绍:
1)某女鞋连锁零售企业,当前业务以线下门店为主,线上销售为辅
2)通过对会员的注册数据以及消费数据的分析,监控会员运营情况,为后续会员运营提供决策依据
3)会员等级说明
- 白银:注册(0)
- 黄金:下单(1~3888)
- 铂金: 3888~6888
- 钻石:6888以上
数据分析要达成的目标:
1)描述性数据分析
2)使用业务数据,分析出会员运营的基本情况
案例中用到的数据:
1)会员信息查询.xlsx
2)会员消费报表.xlsx
3)门店信息表.xlsx
4)全国销售订单数量表.xlsx
分析会员运营的基本情况:
1)从量的角度分析会员运营情况
- 整体会员运营情况(存量,增量)
- 不同渠道(线上,线下)的会员运营情况
- 线下业务,拆解到不同的地区、门店会员运营情况
2)从质的角度分析会员运营情况
- 会销比
- 连带率
- 复购率
2.2 会员存量、增量分析
每月存量、增量是最基本的指标,通过会员数量考察会员运营情况
1)用到的数据:会员信息查询.xlsx,加载 会员信息查询.xlsx 数据
member_df = pd.read_excel('./data/会员信息查询.xlsx')
member_df.info()
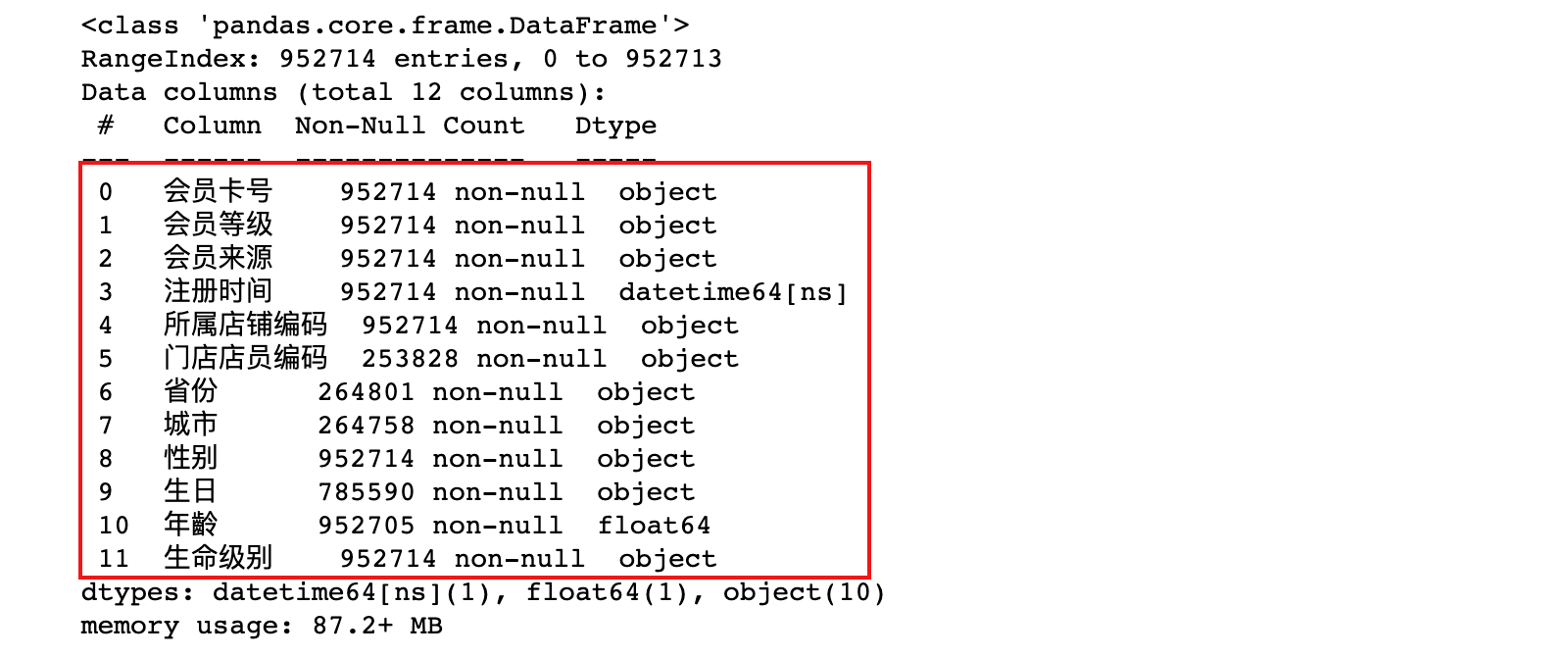
# 会员信息查询
member_df.head()
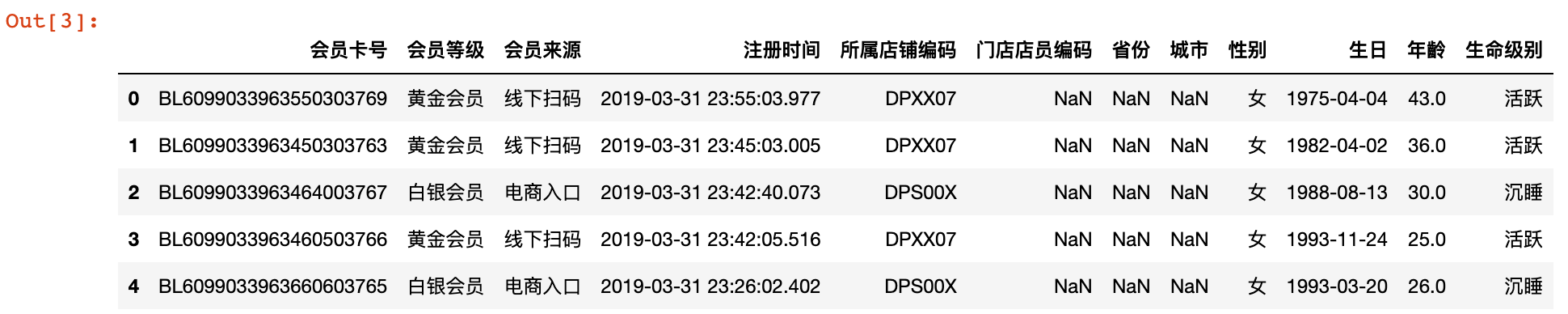
2)需要按月统计注册的会员数量,注册时间原始数据需要处理成年-月的形式
from datetime import datetime
member_df.loc[:, '注册年月'] = member_df['注册时间'].apply(lambda x: datetime.strftime(x, '%Y-%m'))
member_df.head()

3)按注册年月统计会员增量
分组聚合实现:
month_count = member_df.groupby('注册年月')[['会员卡号']].count()
month_count.head()

# 修改列标签
month_count.columns = ['月增量']
month_count.head()

透视表实现:
- index:行索引,传入原始数据的列名
- columns:列索引,传入原始数据的列名
- values: 要做聚合操作的列名
- aggfunc:聚合函数
month_count = member_df.pivot_table(index='注册年月', values='会员卡号', aggfunc='count')
month_count.head()

# 修改列标签
month_count.columns = ['月增量']
month_count.head()

4)在月增量数据的基础上统计月存量
# 通过 cumsum 对月增量做累积求和
month_count.loc[:, '存量'] = month_count['月增量'].cumsum()
month_count
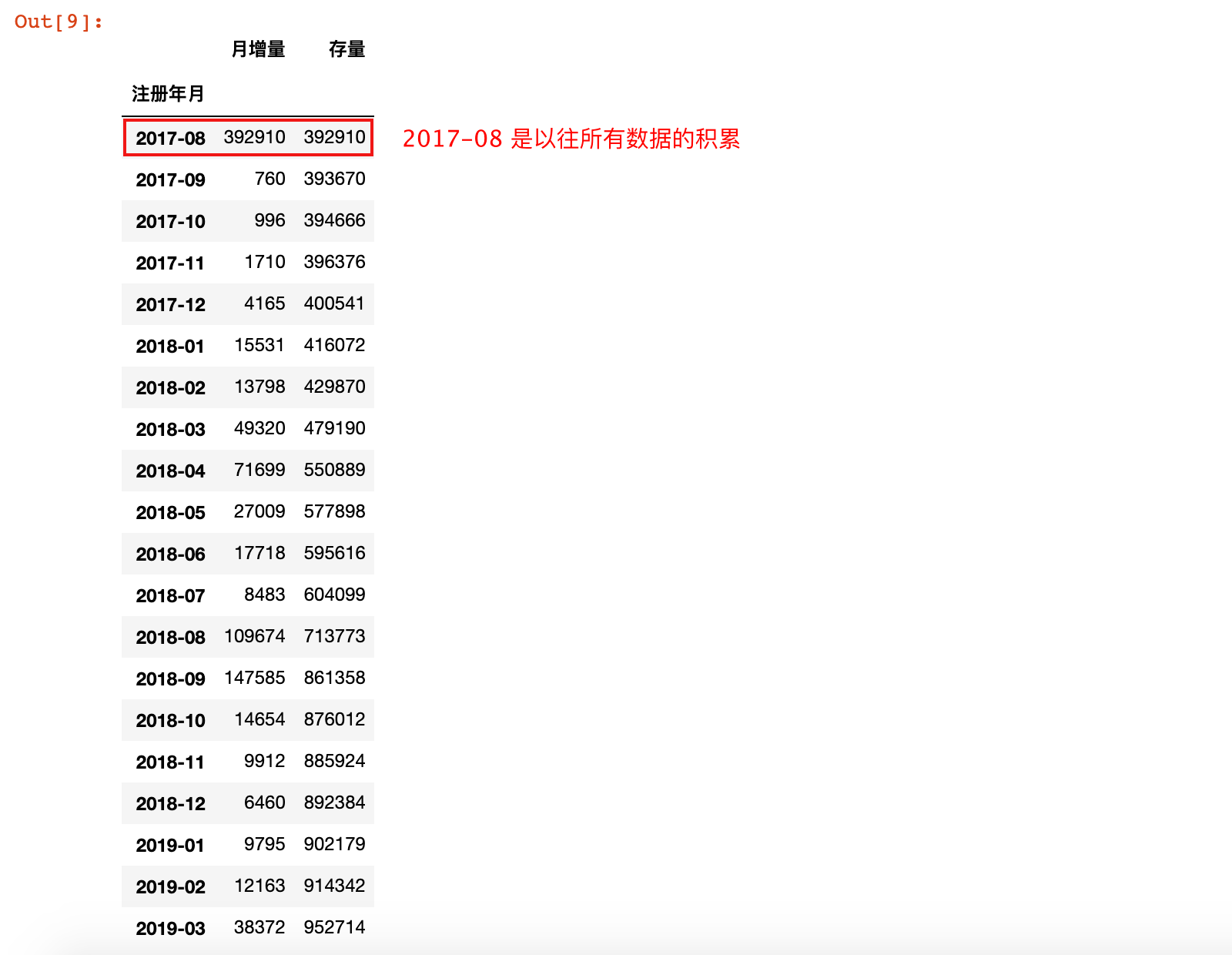
5)从结果中剔除 2017-08 月份的数据
month_count = month_count[1:]
month_count.head()

6)对上面的统计结果进行可视化
%matplotlib inline
import matplotlib.pyplot as plt
# Mac 操作系统设置字体
plt.rcParams['font.sans-serif'] = 'Arial Unicode MS'
# Win 操作系统设置字体
# plt.rcParams['font.sans-serif'] = 'SimHei'
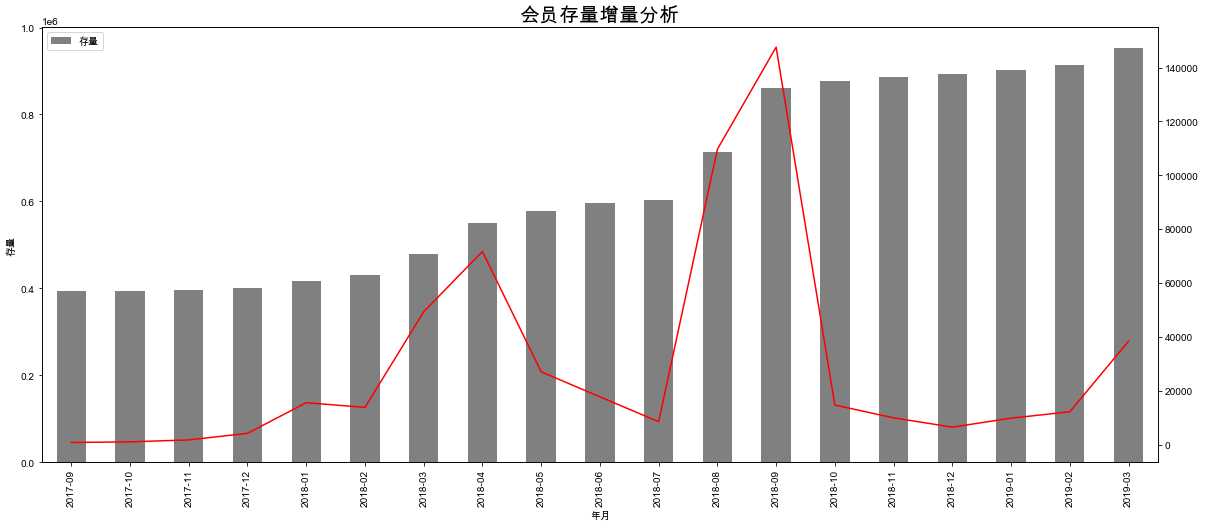
month_count['月增量'].plot(figsize=(20, 8), color='red', secondary_y=True)
month_count['存量'].plot.bar(figsize=(20, 8), color='gray', xlabel='年月', ylabel='存量', legend=True)
plt.title('会员存量增量分析', fontsize=20)
2.3 增量等级分布
会员增量存量不能真实反映会员运营的质量,需要对会员的增量存量数据做进一步拆解
从哪些维度来拆解?
1)从指标构成来拆解
- 会员 = 白银会员+黄金会员+铂金会员+钻石会员
2)从业务流程来拆解
- 当前案例,业务分线上、线下,又可以进一步拆解:按大区,按门店
会员等级分布分析的目的和要分析的指标:
1)会员按照等级拆解分为
- 白银: 注册(0)
- 黄金: 下单(1~3888)
- 铂金: 3888~6888
- 钻石: 6888以上
2)由于会员等级跟消费金额挂钩,所以会员等级分布分析可以说明会员的质量
具体实现:
1)按照注册年月和会员等级,统计会员增量
分组聚合实现:
month_degree_count = member_df.groupby(['注册年月', '会员等级'])[['会员卡号']].count()
month_degree_count
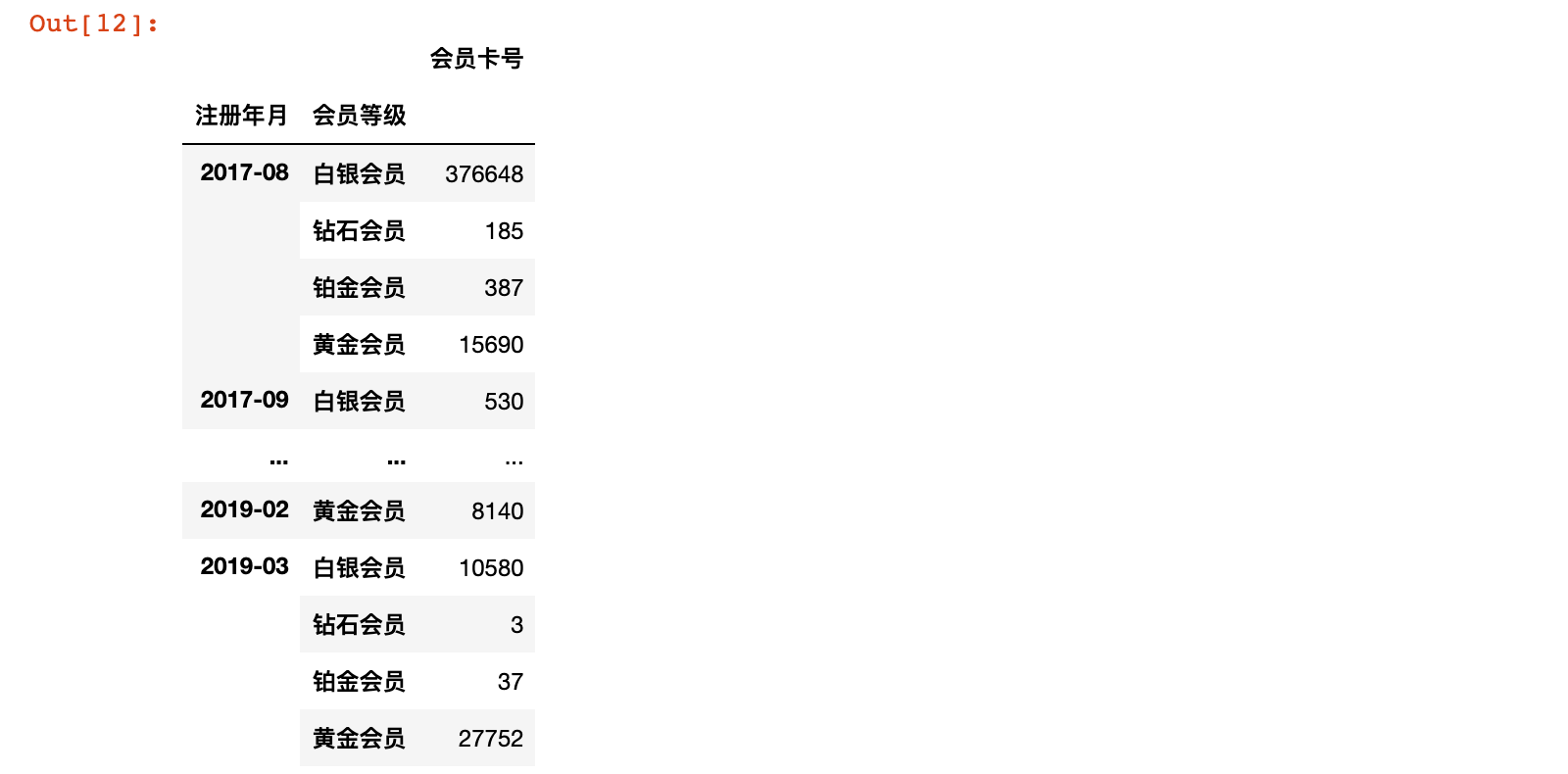
# 进行 unstack 操作
month_degree_count.unstack()
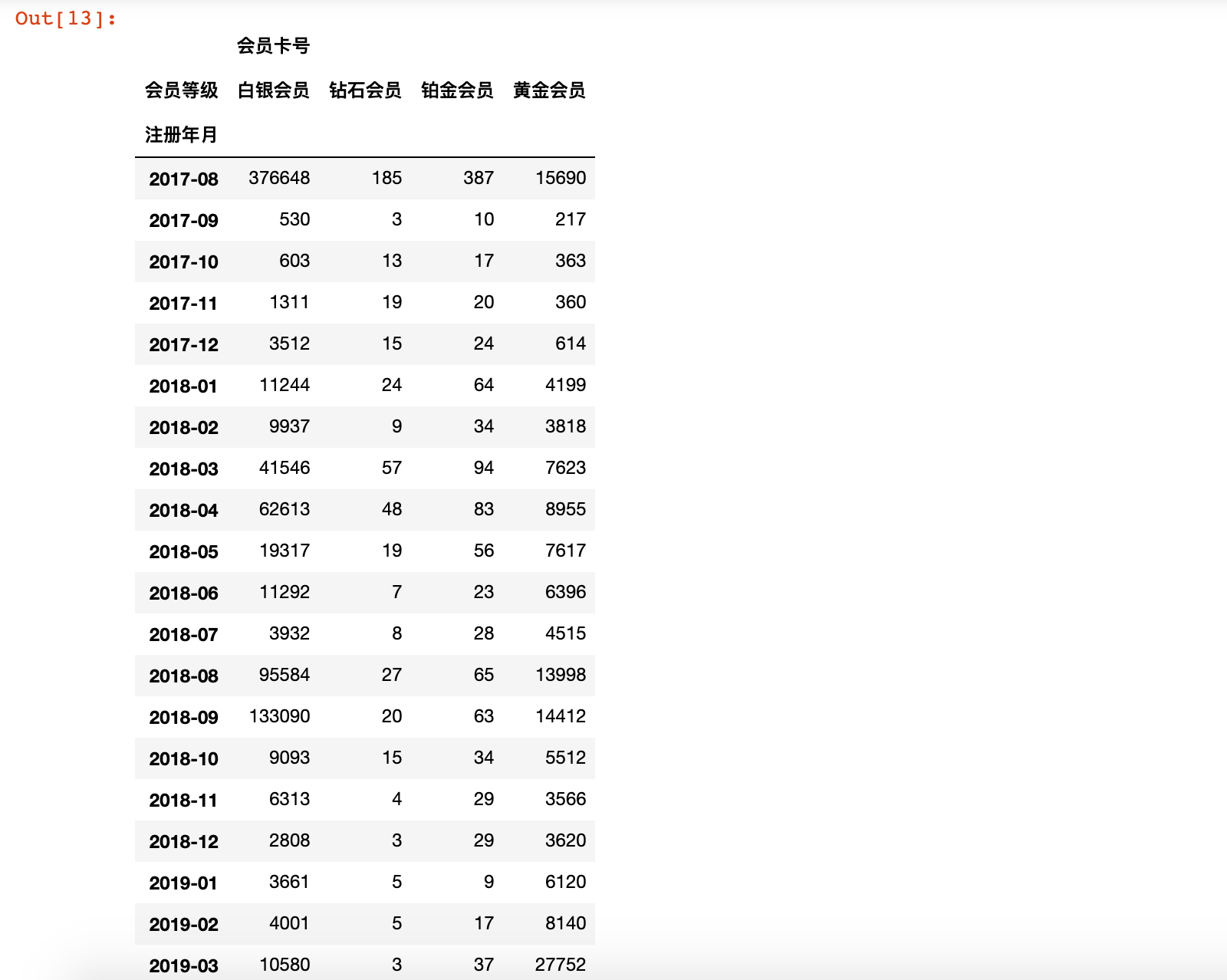
透视表实现:
month_degree_count = member_df.pivot_table(index='注册年月',
columns='会员等级',
values='会员卡号',
aggfunc='count')
month_degree_count
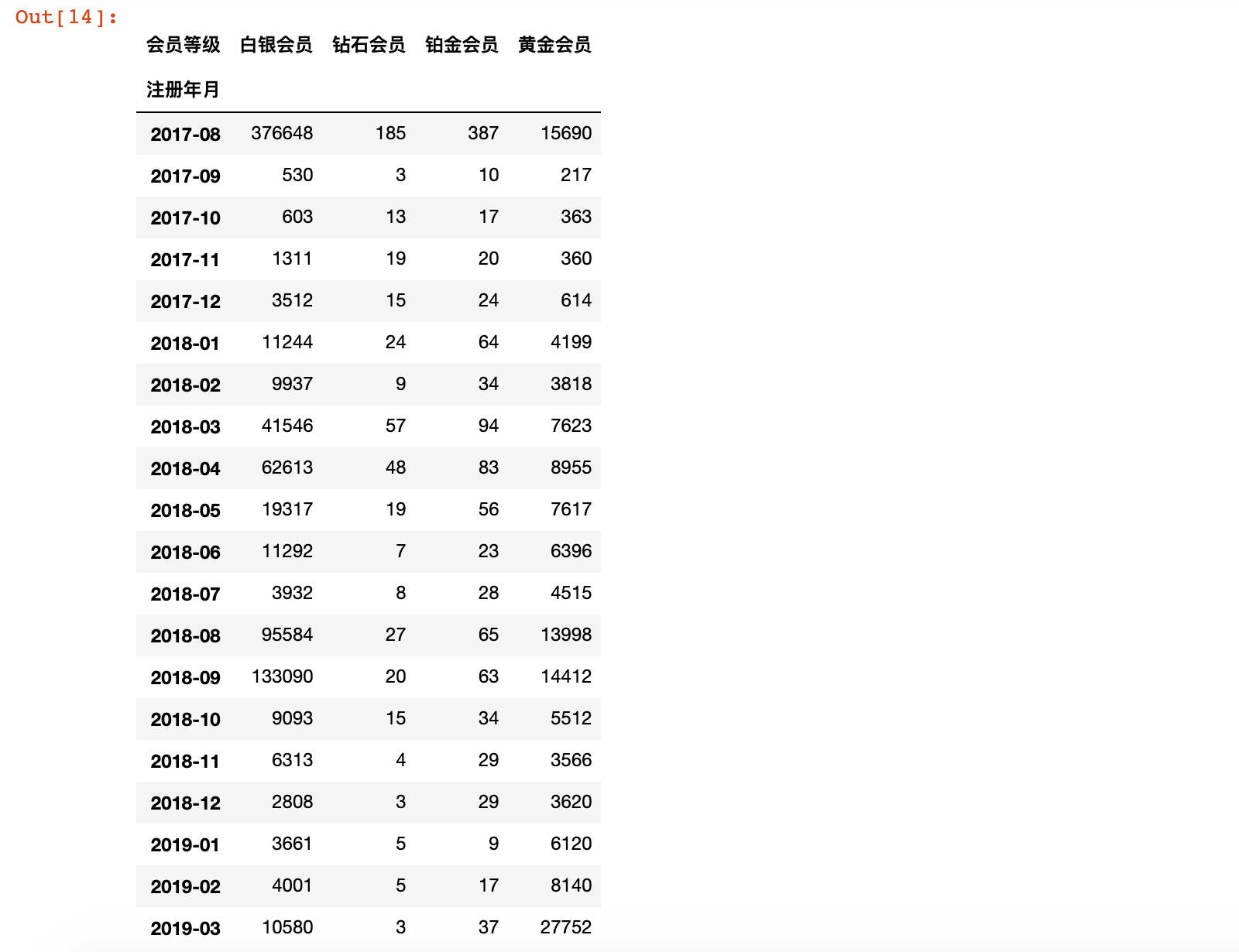
2)从结果中剔除 2017-08 月份的数据
month_degree_count = month_degree_count[1:]
month_degree_count.head()
3)对上面的统计结果进行可视化
# pandas绘图
fig, ax1 = plt.subplots(figsize=(20, 8), dpi=100)
ax2 = ax1.twinx()
month_degree_count[['白银会员', '黄金会员']].plot.bar(ax=ax1, rot=0, grid=True, xlabel='年月', ylabel='白银黄金')
month_degree_count[['铂金会员', '钻石会员']].plot(ax=ax2, color=['red', 'gray'], ylabel='铂金钻石')
ax2.legend(loc='upper left')
plt.title('会员增量等级分布')
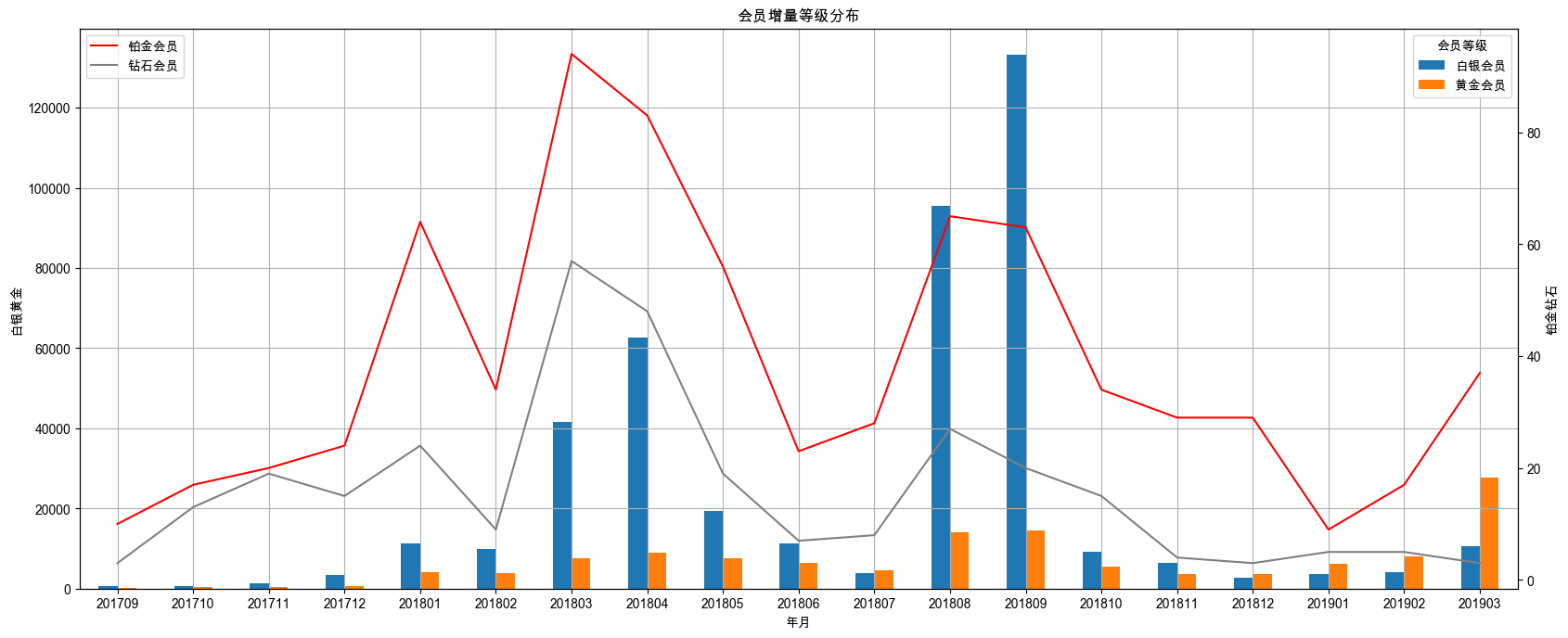
2.4 增量等级占比分析
增量等级占比分析,查看增量会员的消费情况
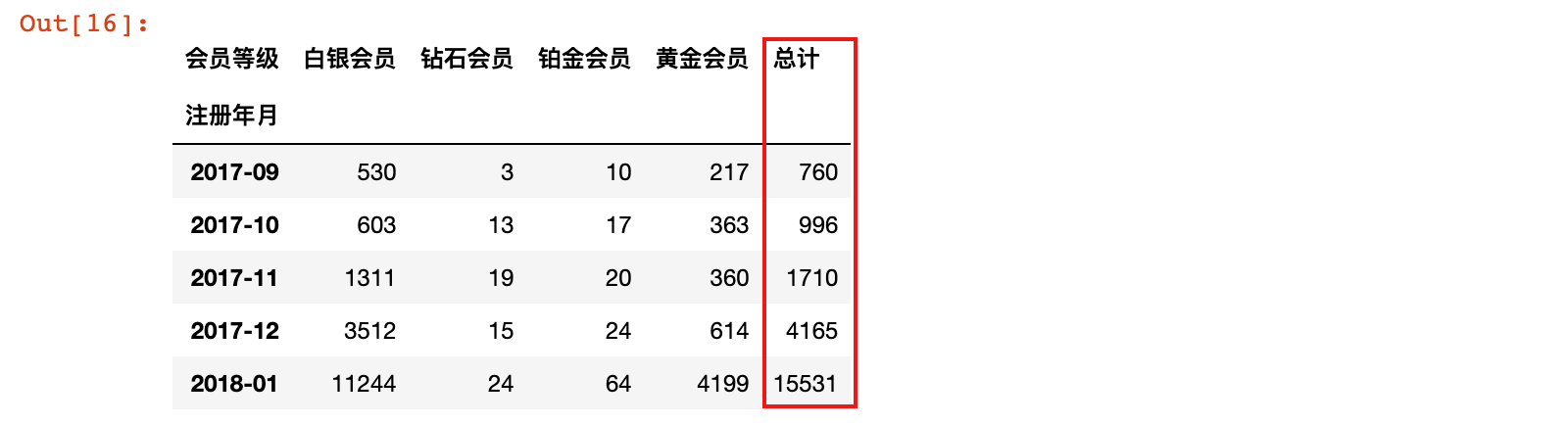
1)计算每月新增会员总量
month_degree_count = month_degree_count.copy()
month_degree_count.loc[:, '总计'] = month_degree_count.sum(axis=1)
month_degree_count.head()
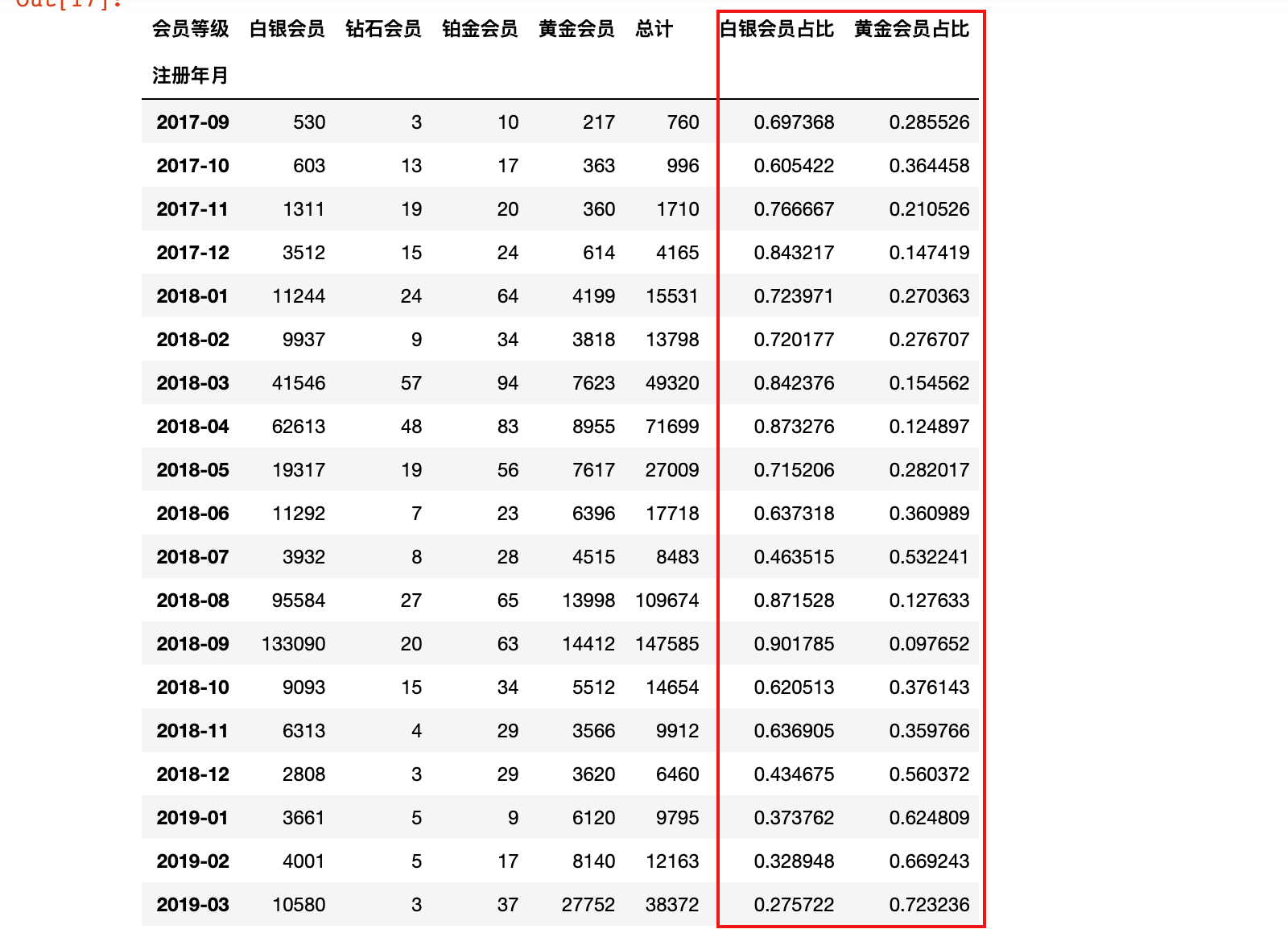
2)计算白银和黄金会员等级占比,铂金钻石会员数量太少暂不计算
month_degree_count.loc[:, '白银会员占比'] = month_degree_count['白银会员']/month_degree_count['总计']
month_degree_count.loc[:, '黄金会员占比'] = month_degree_count['黄金会员']/month_degree_count['总计']
month_degree_count
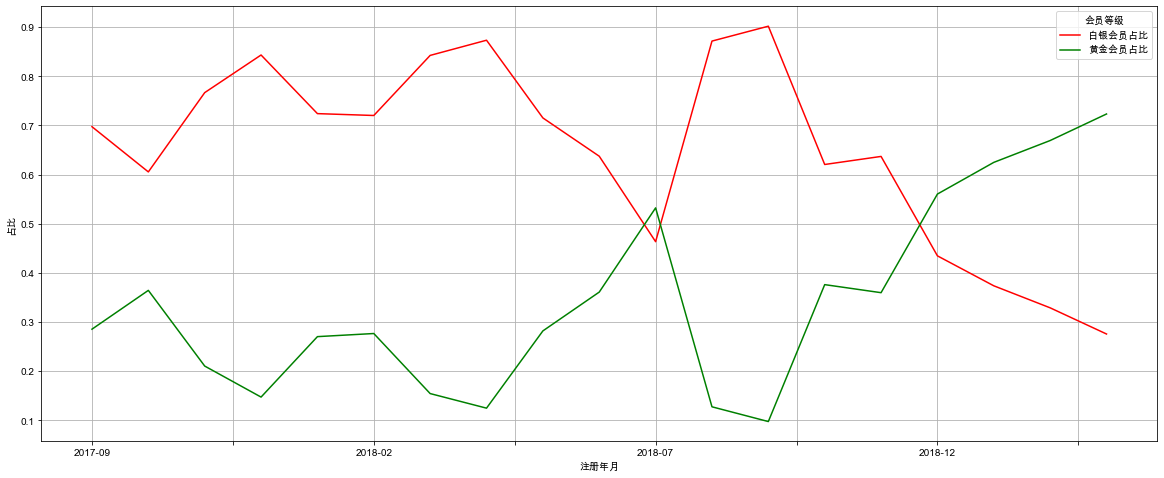
3)对上面的统计结果进行可视化
# pandas绘图
month_degree_count[['白银会员占比', '黄金会员占比']].plot(figsize=(20, 8), color=['r', 'g'], ylabel='占比', grid=True)
2.5 会员整体等级分布
计算各个等级会员占整体的百分比
思路:按照会员等级分组,计算每组的会员数量,用每组会员数量/全部会员数量
1)按照会员等级分组,计算每组的会员数量
分组聚合实现:
ratio = member_df.groupby('会员等级')[['会员卡号']].count()
ratio

透视表实现:
ratio = member_df.pivot_table(index='会员等级', values='会员卡号', aggfunc='count')
ratio

# 修改列标签
ratio.columns = ['会员数']
ratio

2)计算各个等级会员占比
ratio.loc[:, '占比'] = ratio['会员数']/ratio['会员数'].sum()
ratio

3)对上面的统计结果进行可视化
# pandas 绘图
ratio.loc[['白银会员', '钻石会员', '黄金会员', '铂金会员'], '占比'].plot.pie(figsize=(20, 8), autopct='%.1f%%', fontsize=16)

2.6 线上线下增量分析
从业务角度,将会员数据拆分成线上和线下,比较每月线上线下会员的运营情况
1)按照注册年月和会员来源统计会员增量
分组聚合实现:
from_data = member_df.groupby(['注册年月', '会员来源'])[['会员卡号']].count()
from_data.head(6)

# unstack 操作
from_data = from_data.unstack()
from_data.head()

透视表实现:
from_data = member_df.pivot_table(index='注册年月',
columns=['会员来源'],
values='会员卡号',
aggfunc='count')
from_data.head()

2)从结果中剔除 2017-08 月份的数据
from_data = from_data[1:]
from_data.head()

3)对上面的统计结果进行可视化
# pandas 绘图
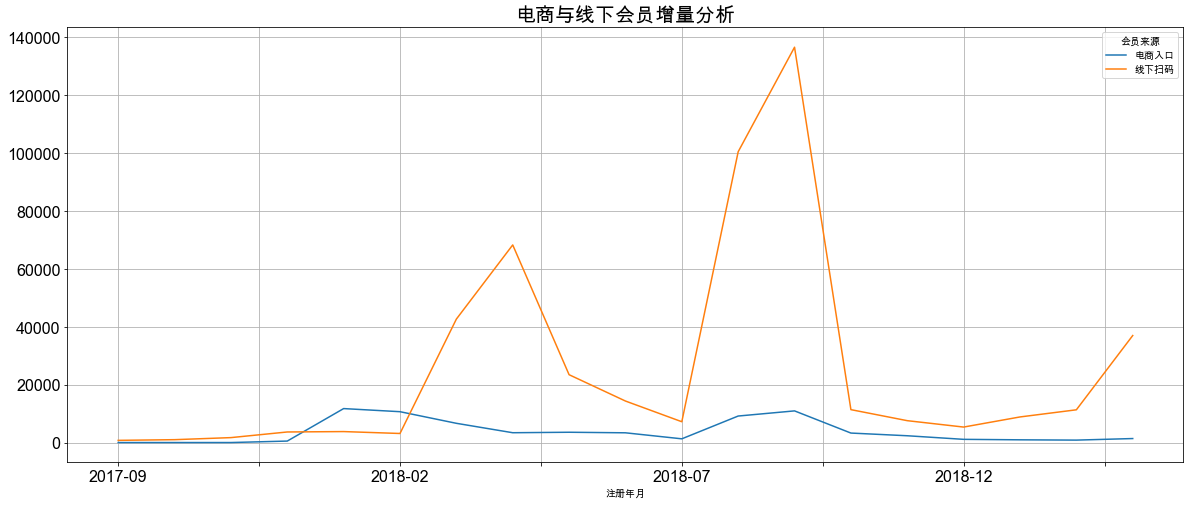
from_data.plot(figsize=(20, 8), fontsize=16, grid=True)
plt.title('电商与线下会员增量分析', fontsize=20)
2.7 地区店均会员数量
思路:会员信息查询表中,只有店铺信息,没有地区信息,需要从门店信息表中关联地区信息
1)加载 门店信息表.XLSX 数据,并从中提取出 店铺代码 和 地区编码
store_info = pd.read_excel('./data/门店信息表.XLSX')
store_info
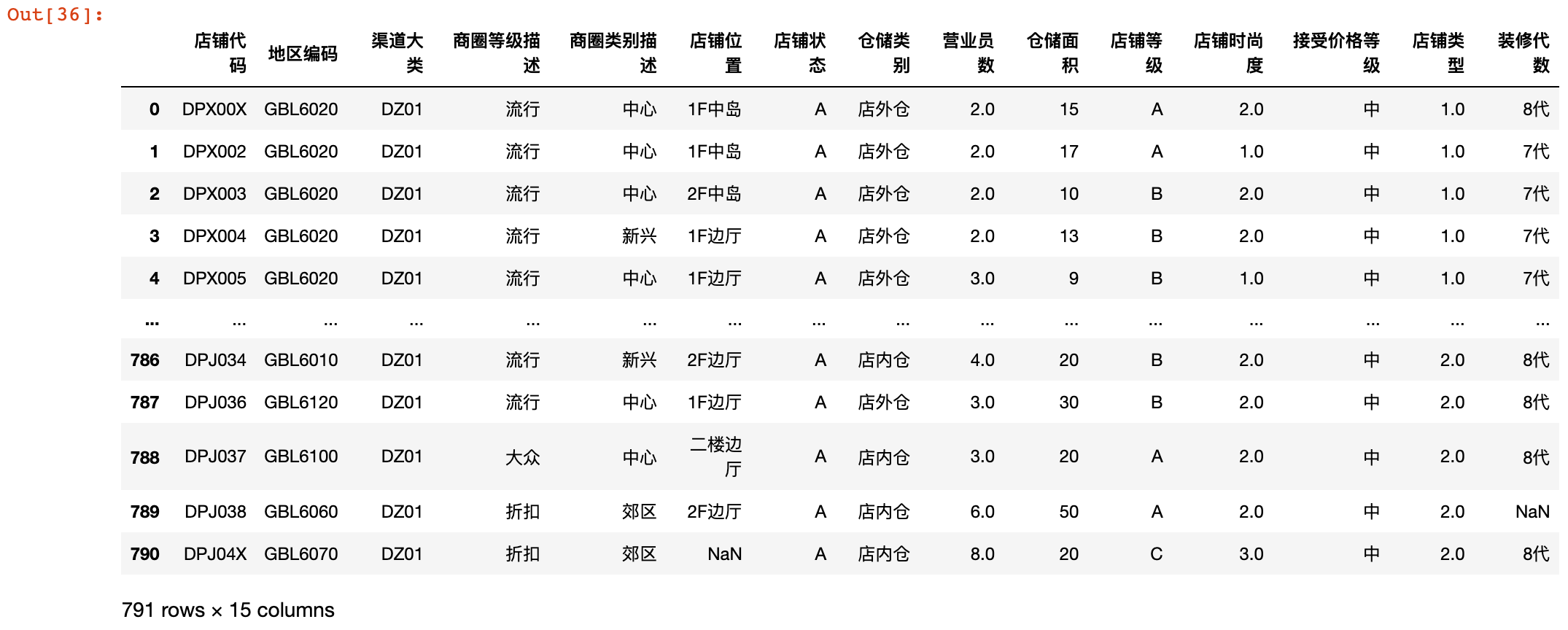
store_info[['店铺代码', '地区编码']]

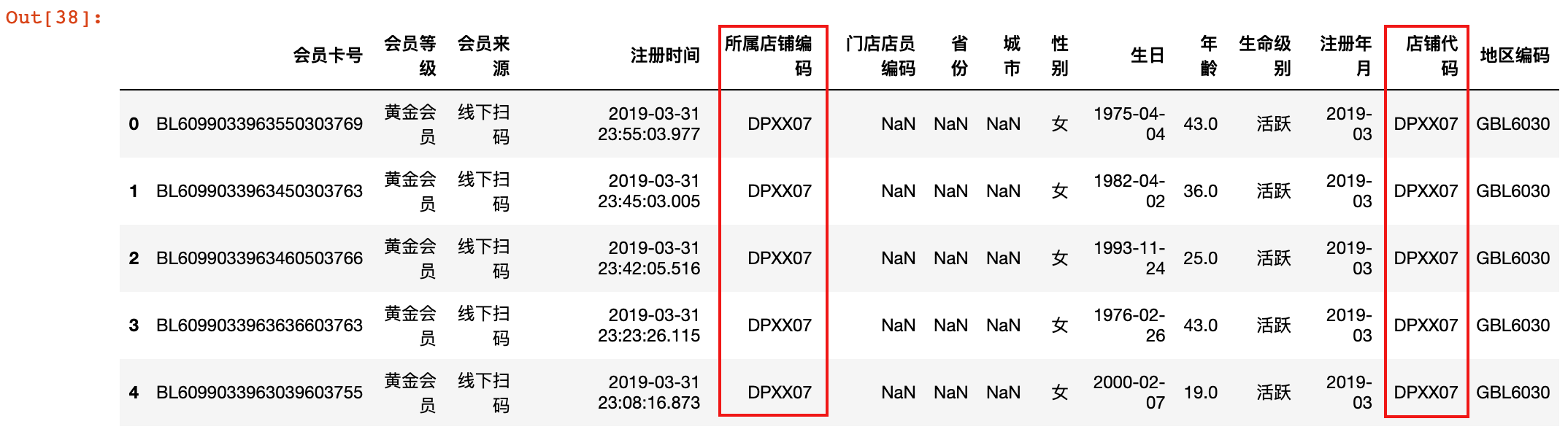
2)将会员信息数据和门店数据进行 merge 操作
country_info = pd.merge(member_df, store_info[['店铺代码', '地区编码']],
left_on='所属店铺编码', right_on='店铺代码')
country_info.head()
3)统计不同地区的会员数量
注意只统计线下,不统计电商渠道, GBL6D01 地区为电商
district = country_info[country_info['地区编码']!='GBL6D01'].groupby('地区编码')[['会员卡号']].count()
district

4)修改列标签
# 修改列标签
district.columns = ['会员数量']
district.head()

4)统计不同地区的店铺数
district['店铺数'] = country_info[['地区编码', '所属店铺编码']].drop_duplicates().groupby('地区编码')['所属店铺编码'].count()
district
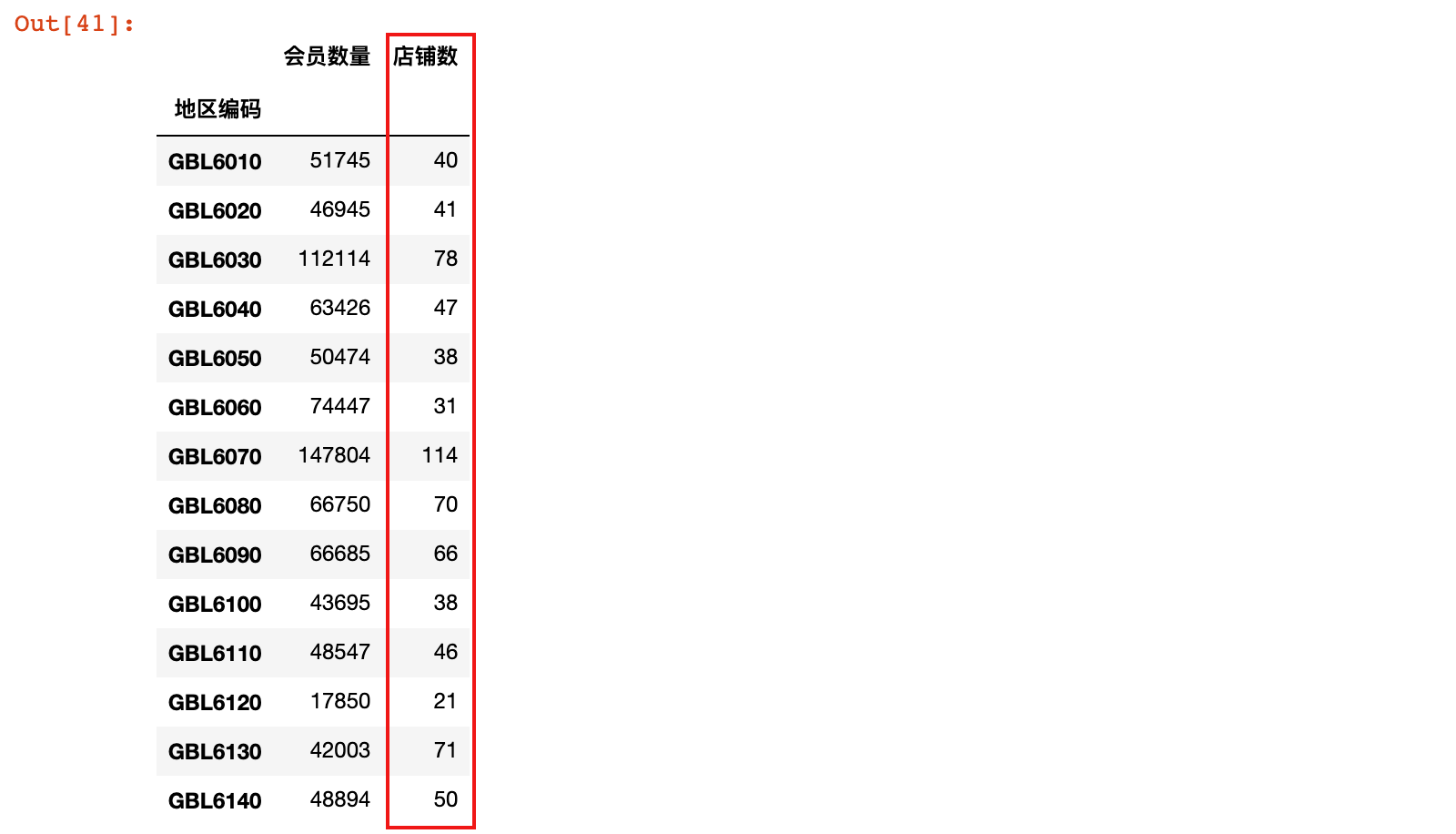
5)计算店均会员数和总平均会员数
district.loc[:, '每店平均会员数'] = round(district['会员数量']/district['店铺数'])
district.loc[:, '总平均会员数'] = district['会员数量'].sum()/district['店铺数'].sum()
district
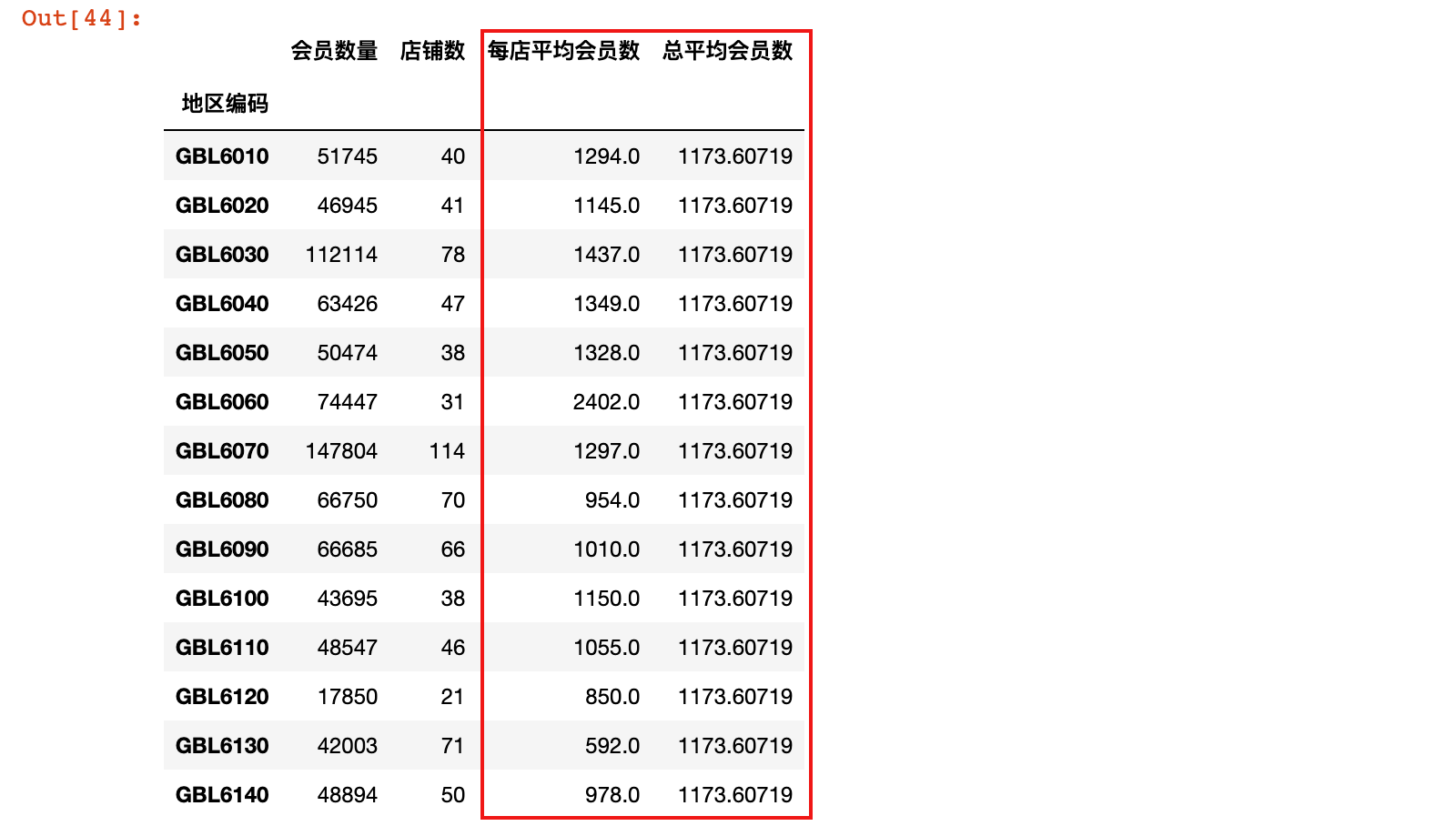
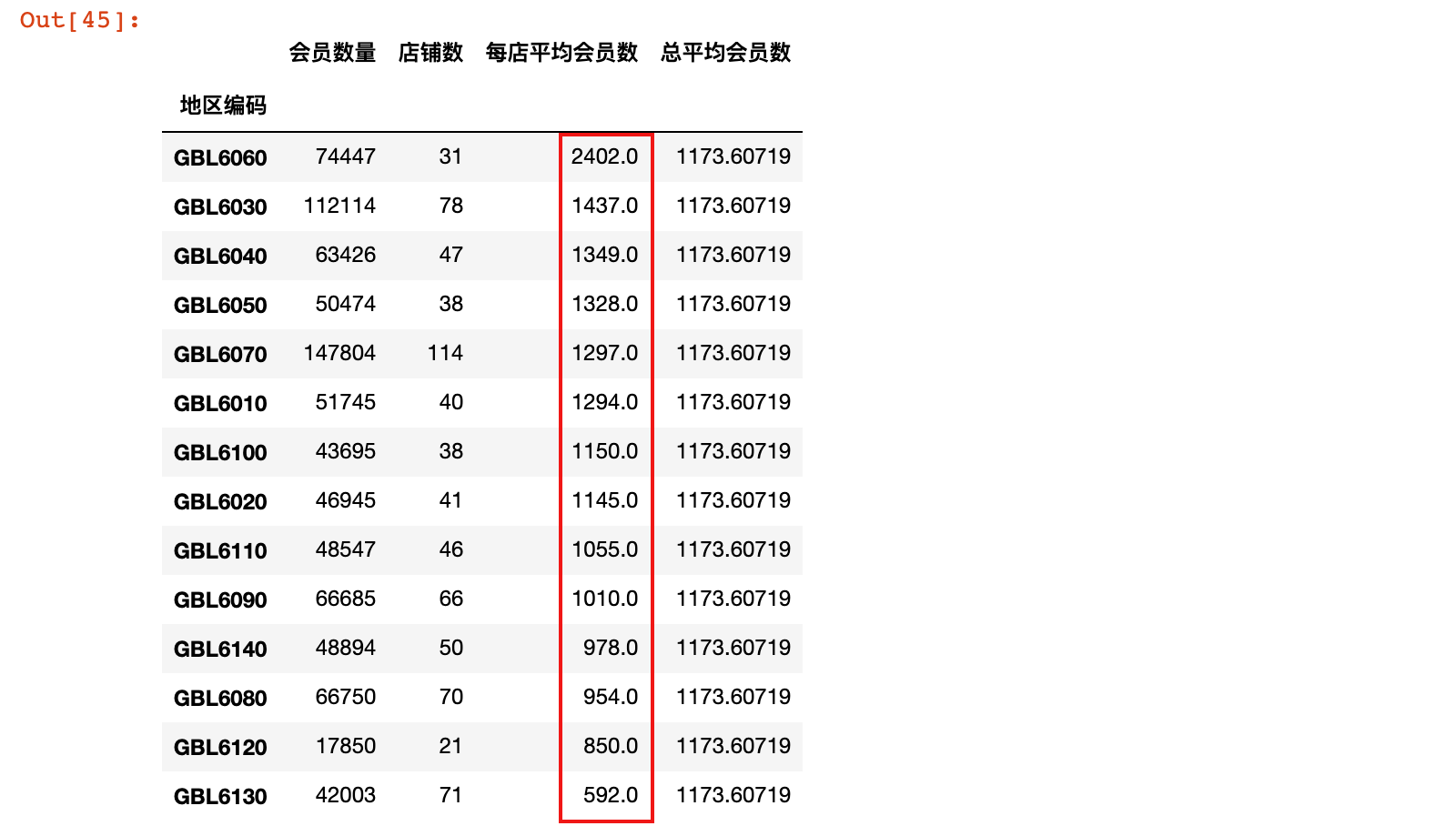
6)按照店均会员数对数据进行排序
district = district.sort_values('每店平均会员数', ascending=False)
district
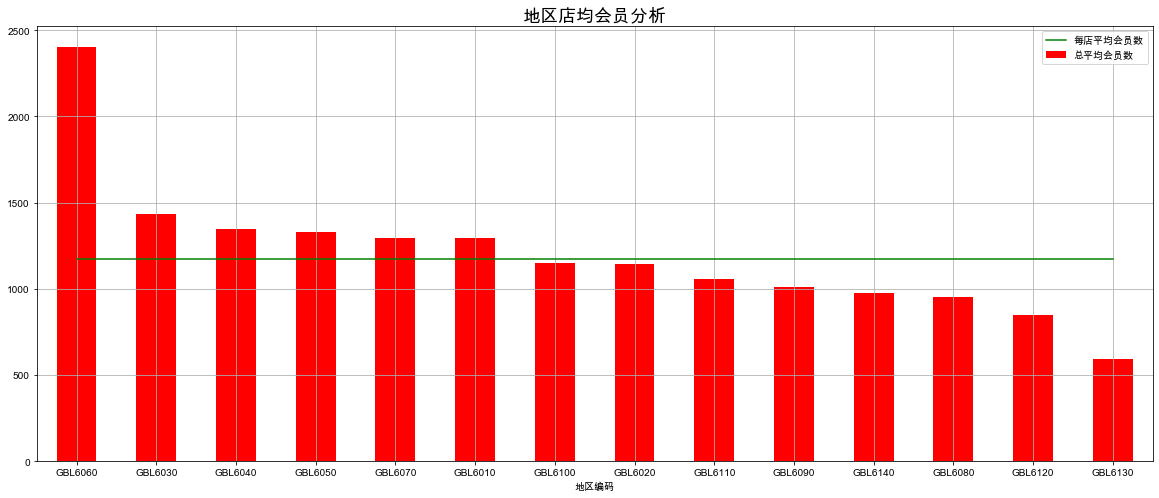
7)对上面的统计结果进行可视化
district['每店平均会员数'].plot.bar(figsize=(20, 8), color='r', legend=True, grid=True)
district['总平均会员数'].plot(figsize=(20, 8), color='g', legend=True, grid=True)
plt.title('地区店均会员分析', fontsize=18)
2.8 各地区会销比
会销比的计算和分析会销比的作用:
- 会销比 = 会员消费的金额 / 全部客户消费的金额
- 由于数据脱敏的原因,没有全部客户消费金额的数据,所以用如下方式替换
- 会销比 = 会员消费的订单数 / 全部销售订单数
- 会销比统计的是会员消费占所有销售金额的比例
- 通过会销比可以衡量会员的整体质量
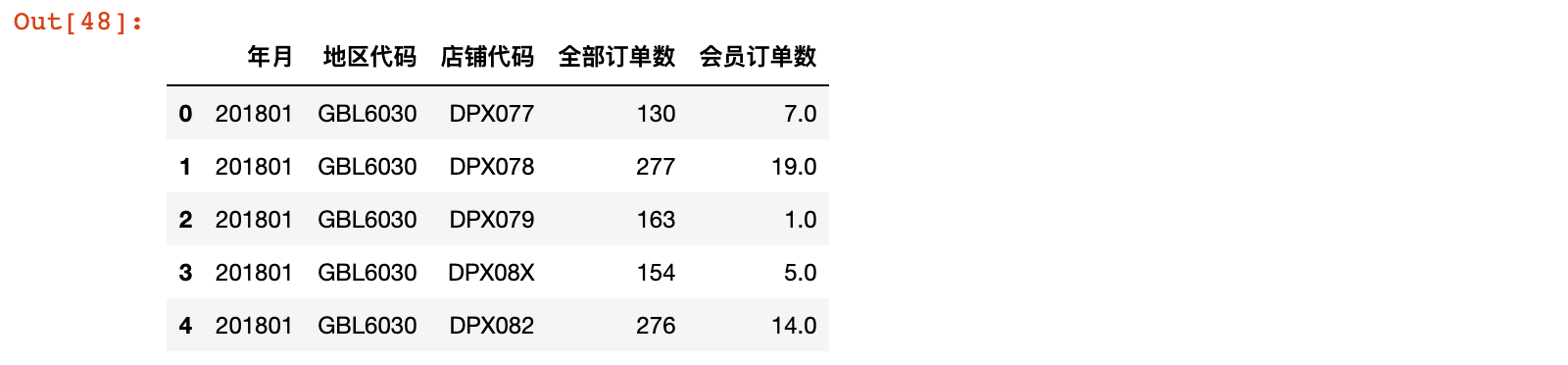
1)加载 全国销售订单数量表.xlsx 数据
all_orders = pd.read_excel('./data/全国销售订单数量表.xlsx')
all_orders.head()
2)按照地区和年月统计会员订单数
member_orders = all_orders.pivot_table(values='会员订单数',
index='地区代码',
columns='年月',
aggfunc='sum',
margins='all')
member_orders
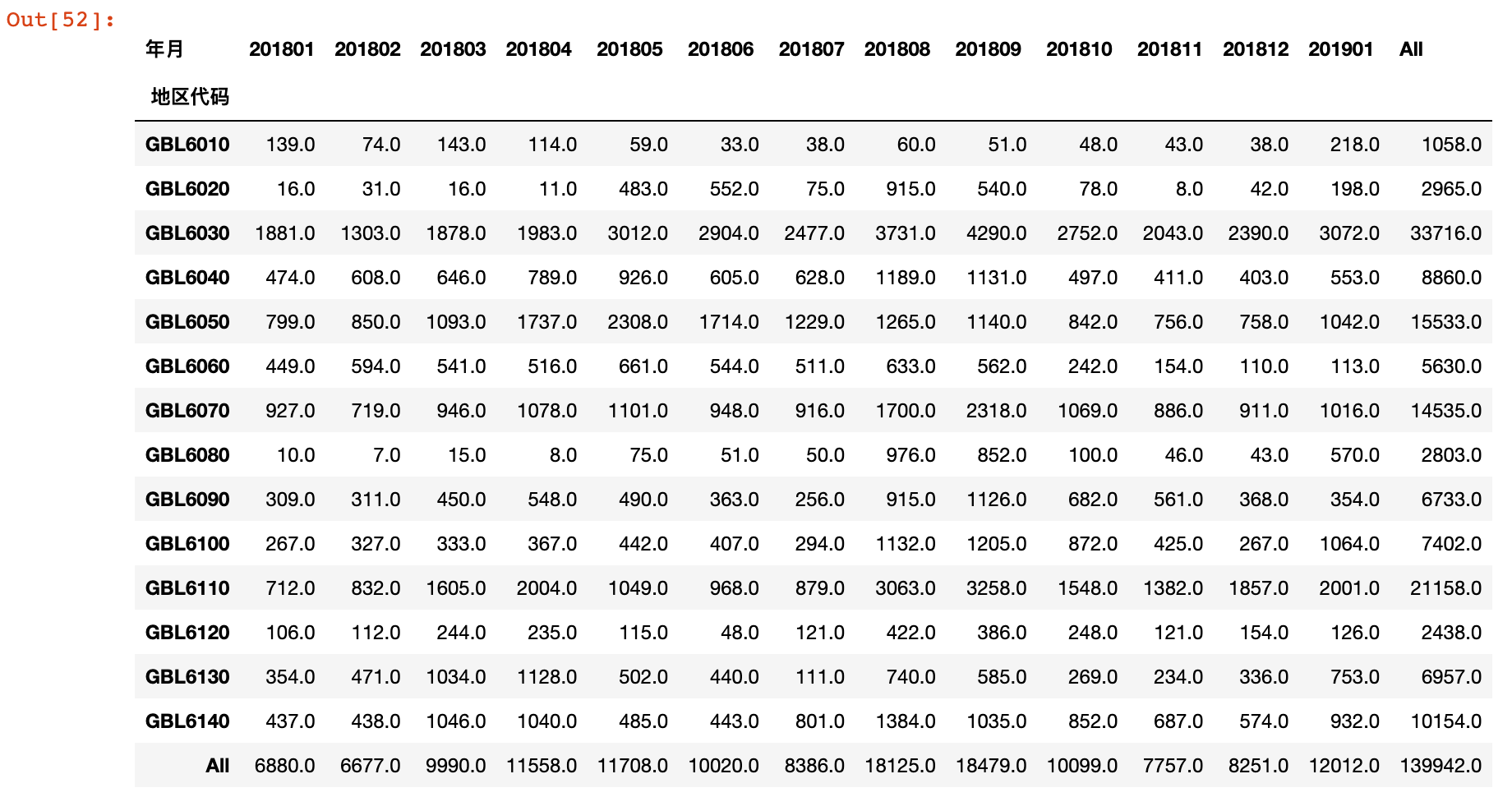
3)按照地区和年月统计全部订单数
country_sales = all_orders.pivot_table(values='全部订单数',
index='地区代码',
columns='年月',
aggfunc='sum',
margins='all')
country_sales
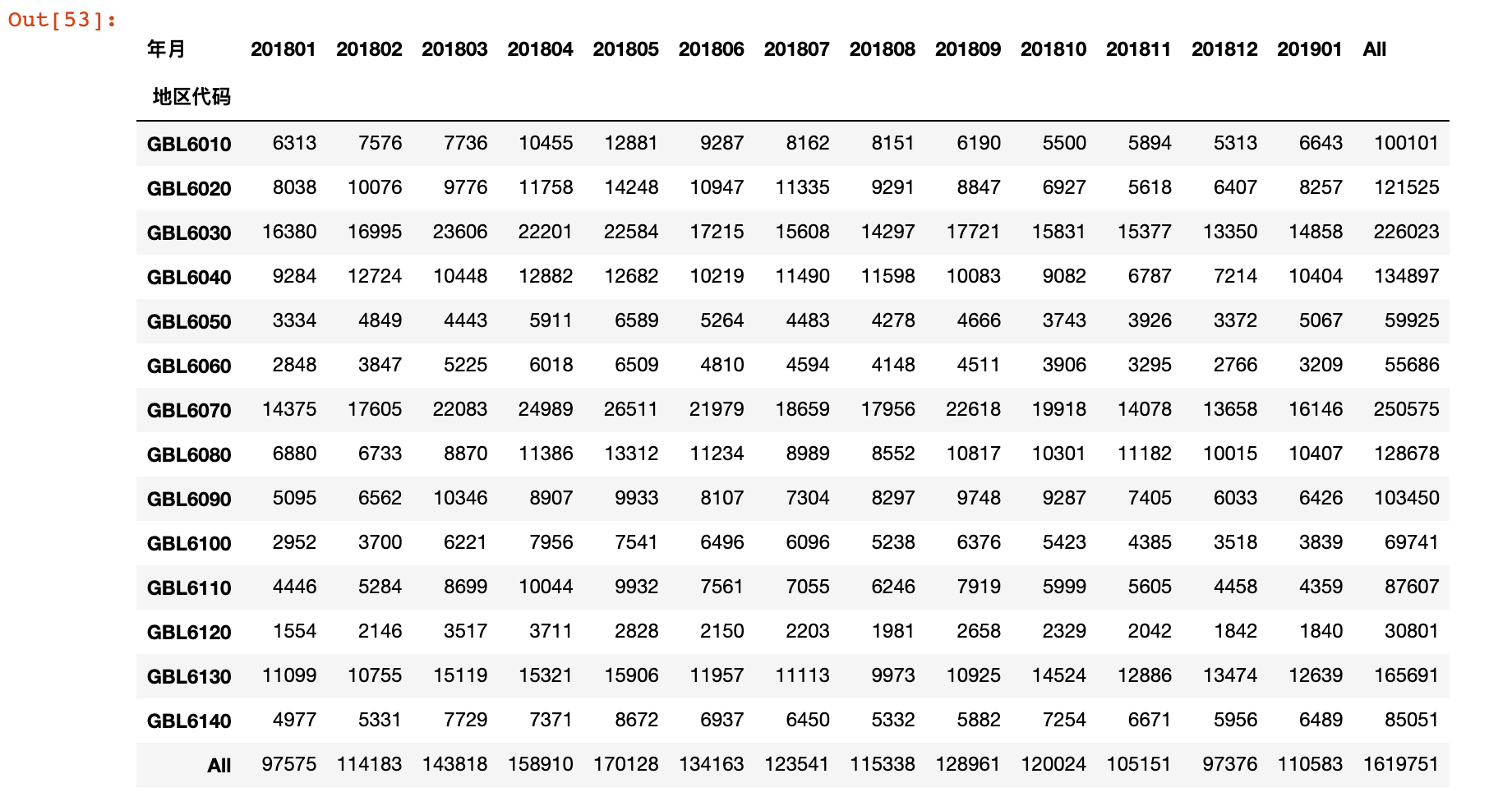
4)计算会销比
result = member_orders / country_sales
result.applymap(lambda x: format(x, '.2%'))
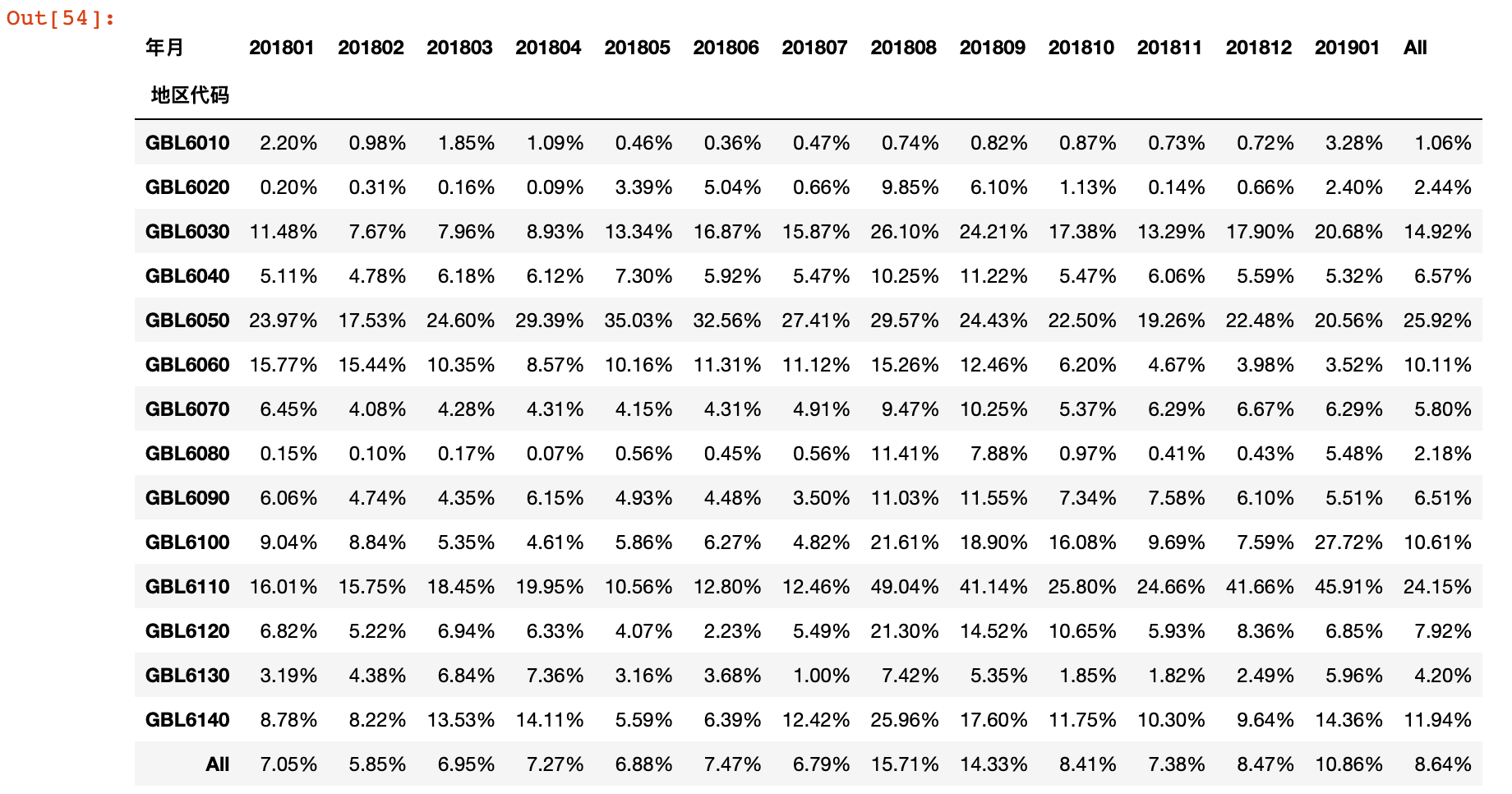
2.9 各地区会员连带率分析
连带率的概念和为什么分析连带率:
1)连带率是指销售的件数和交易的次数相除后的数值,反映的是顾客平均单次消费的产品件数
2)为什么分析连带率?
- 连带率直接影响到客单价
- 连带率反应运营质量
3)分析连带率的作用
- 通过连带率分析可以反映出人、货、场几个角度的业务问题
连带率的计算
- 连带率 = 消费数量 / 订单数量
用到的数据:
会员消费报表.xlsx:会员消费记录门店信息表.xlsx:建立门店地区对应关系
案例分析实现:
1)加载 会员消费报表 数据
member_consume = pd.read_excel('./data/会员消费报表.xlsx')
member_consume
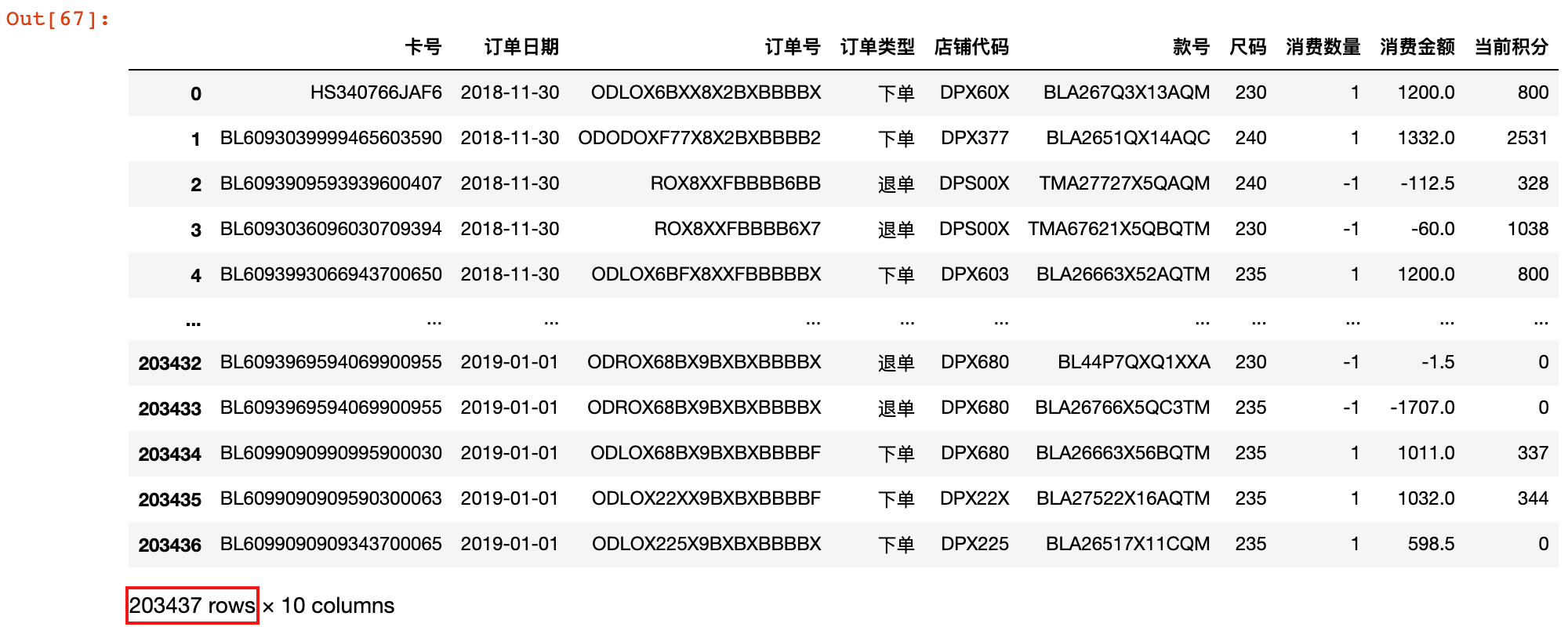
2)排除其中的 退单 数据
member_consume = member_consume.query('订单类型 == "下单"')
member_consume
3)给 member_consume 数据增加 年月 列
import numpy as np
member_consume['年月'] = pd.to_datetime(member_consume['订单日期']).apply(
lambda x: datetime.strftime(x, '%Y%m')).astype(np.int32)
member_consume
3)将 member_consume(会员消费数据) 和 store_info(地区门店数据) 进行 merge 操作
ret = member_consume[['年月', '订单号', '店铺代码', '消费数量']].merge(store_info[['店铺代码', '地区编码']], on='店铺代码')
ret
4)剔除电商渠道的数据,电商渠道地区编码为:GBL6D01
ret = ret.query('地区编码!="GBL6D01"')
ret
5)按照地区和年月统计会员消费数量
consume_count = ret.pivot_table(values='消费数量',
index='地区编码',
columns='年月',
aggfunc='sum')
consume_count
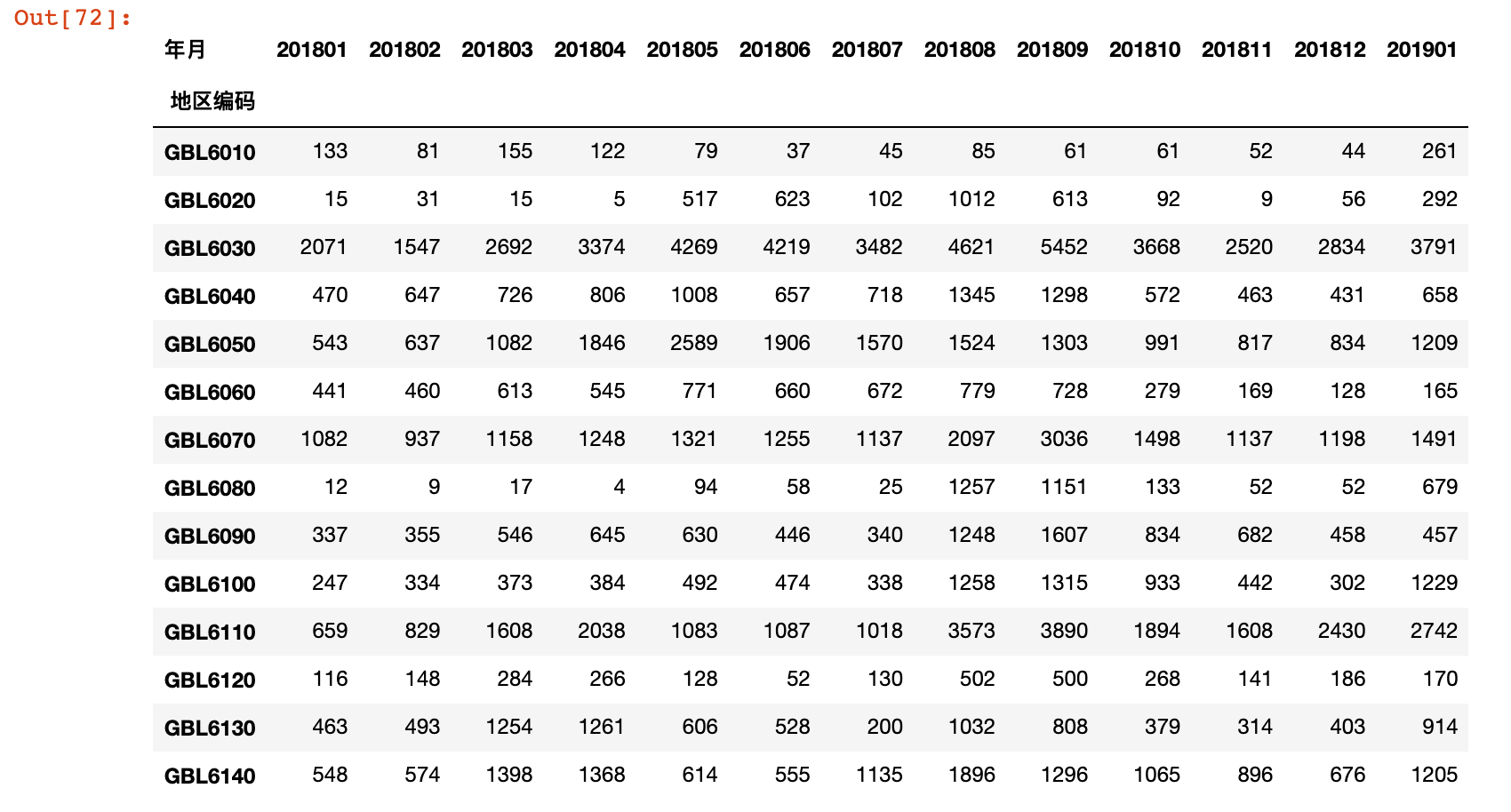
6)按照地区和年月统计会员订单数
order_count = ret.pivot_table(values='订单号',
index='地区编码',
columns='年月',
aggfunc='nunique')
order_count
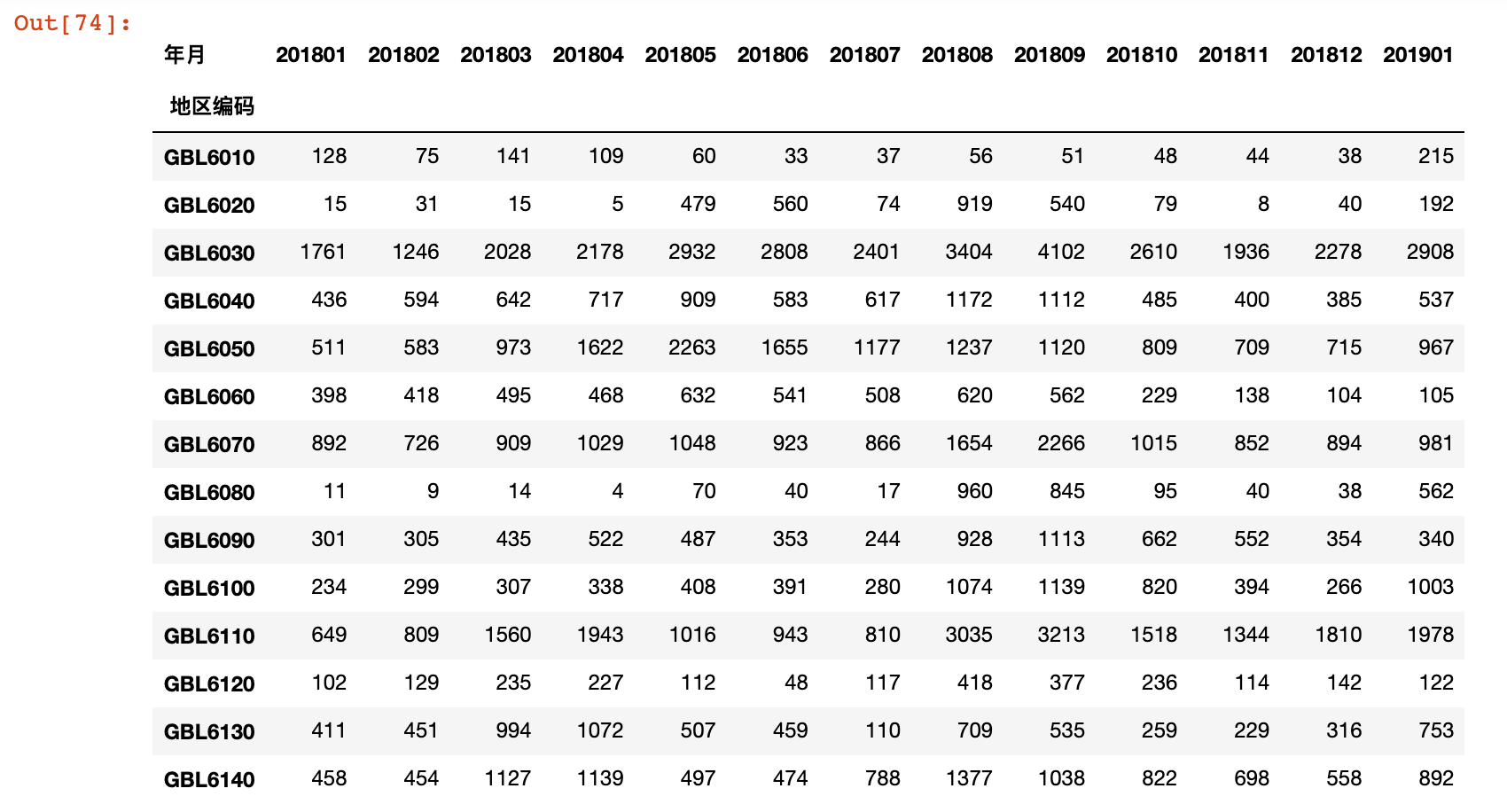
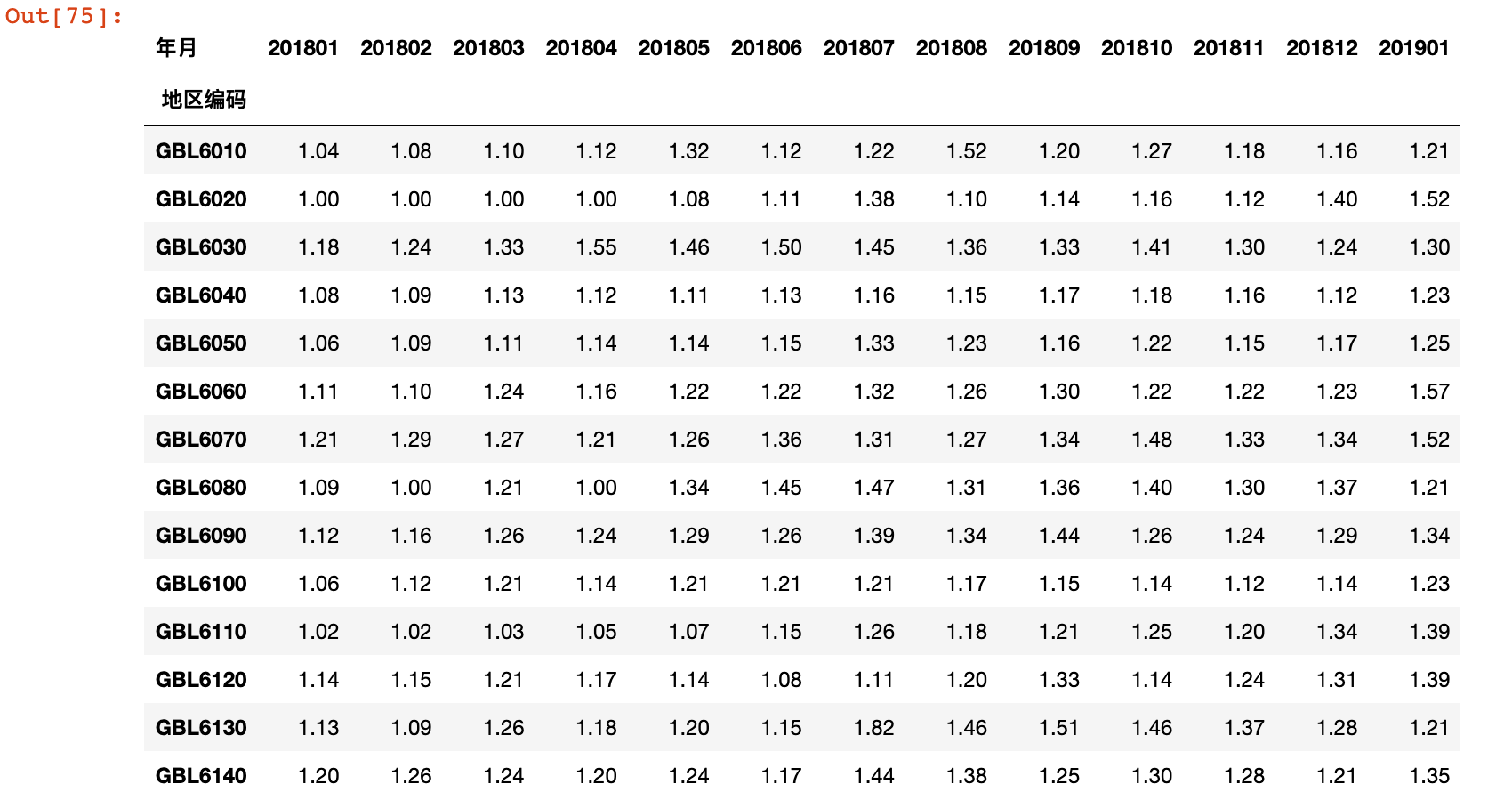
7)计算会员连带率
result = consume_count/order_count
result.applymap(lambda x: format(x, '.2f'))
2.10 会员复购率分析
复购率的概念和复购率分析的作用:
- 复购率:指会员对该品牌产品或者服务的重复购买次数,重复购买率越多,则反应出会员对品牌的忠诚度就越高,反之则越低。
- 计算复购率需要指定时间范围
- 如何计算复购:会员消费次数一天之内只计算一次
- 复购率 = 一段时间内消费次数大于1次的人数 / 总消费人数
- 复购率分析的作用:通过复购率分析可以反映出运营状态
复购率计算步骤:
- 统计会员消费次数与是否复购
- 计算复购率并定义函数
- 统计2018年01月~2018年12月复购率和2018年02月~2019年01月复购率
- 计算复购率环比
案例分析实现:
1)将 member_consume(会员消费数据) 和 store_info(地区门店数据) 进行 merge 操作
order_data = member_consume[['年月', '订单日期', '卡号', '订单号', '订单类型', '店铺代码']].merge(
store_info[['店铺代码', '地区编码']], on='店铺代码').query('订单类型!="退单"')
order_data
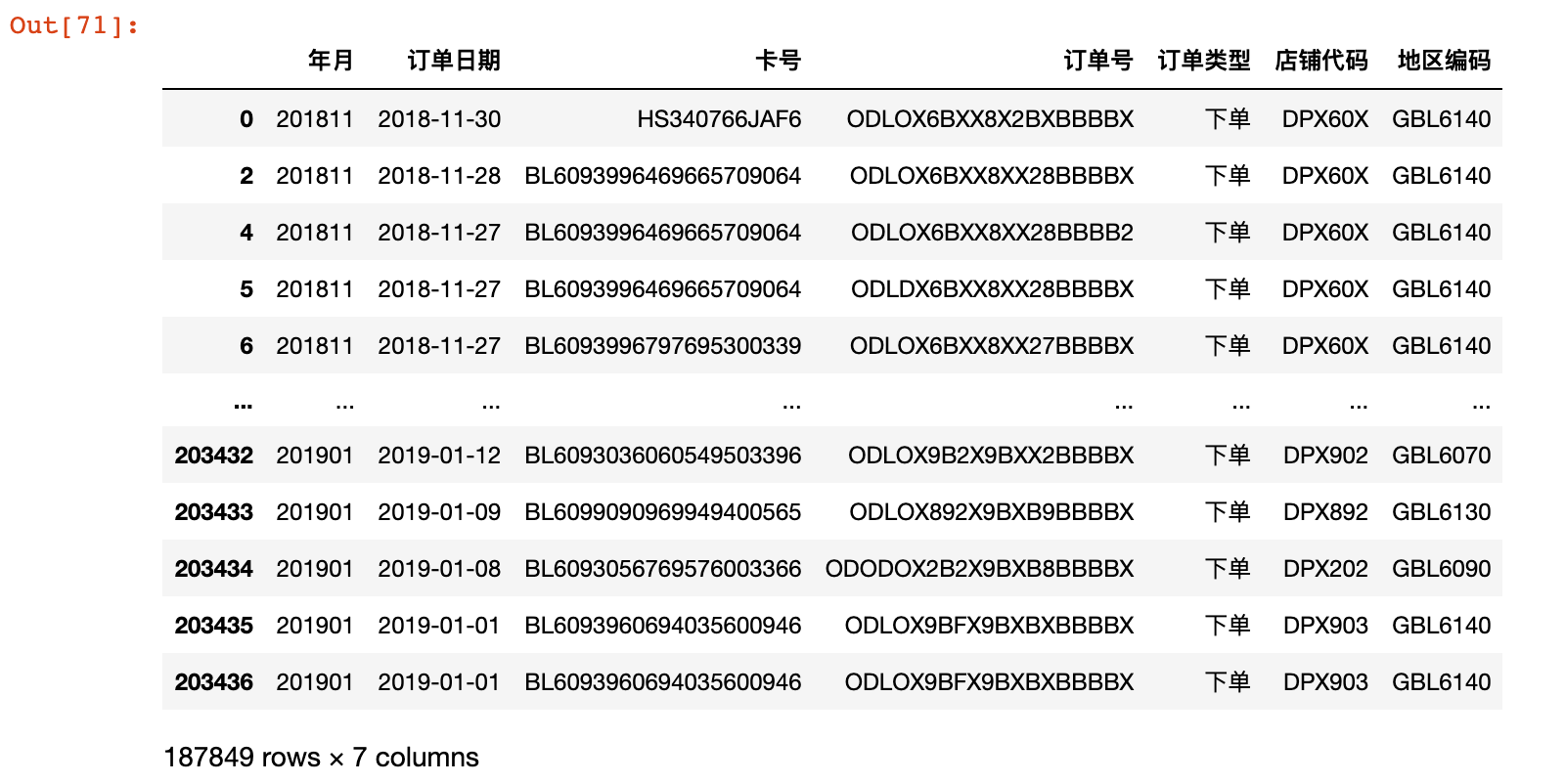
2)统计会员是否复购
由于一个会员同一天消费多次也算一次消费,所以会员消费次数按一天一次计算 因此需要对"会员卡号"和"时间"进行去重
order_data = order_data[['年月', '订单日期', '卡号', '地区编码']].drop_duplicates()
order_data
consume_count = order_data.pivot_table(values='年月',
index=['地区编码', '卡号'],
aggfunc='count').reset_index()
consume_count
consume_count.rename(columns={'年月': '消费次数'}, inplace=True)
consume_count
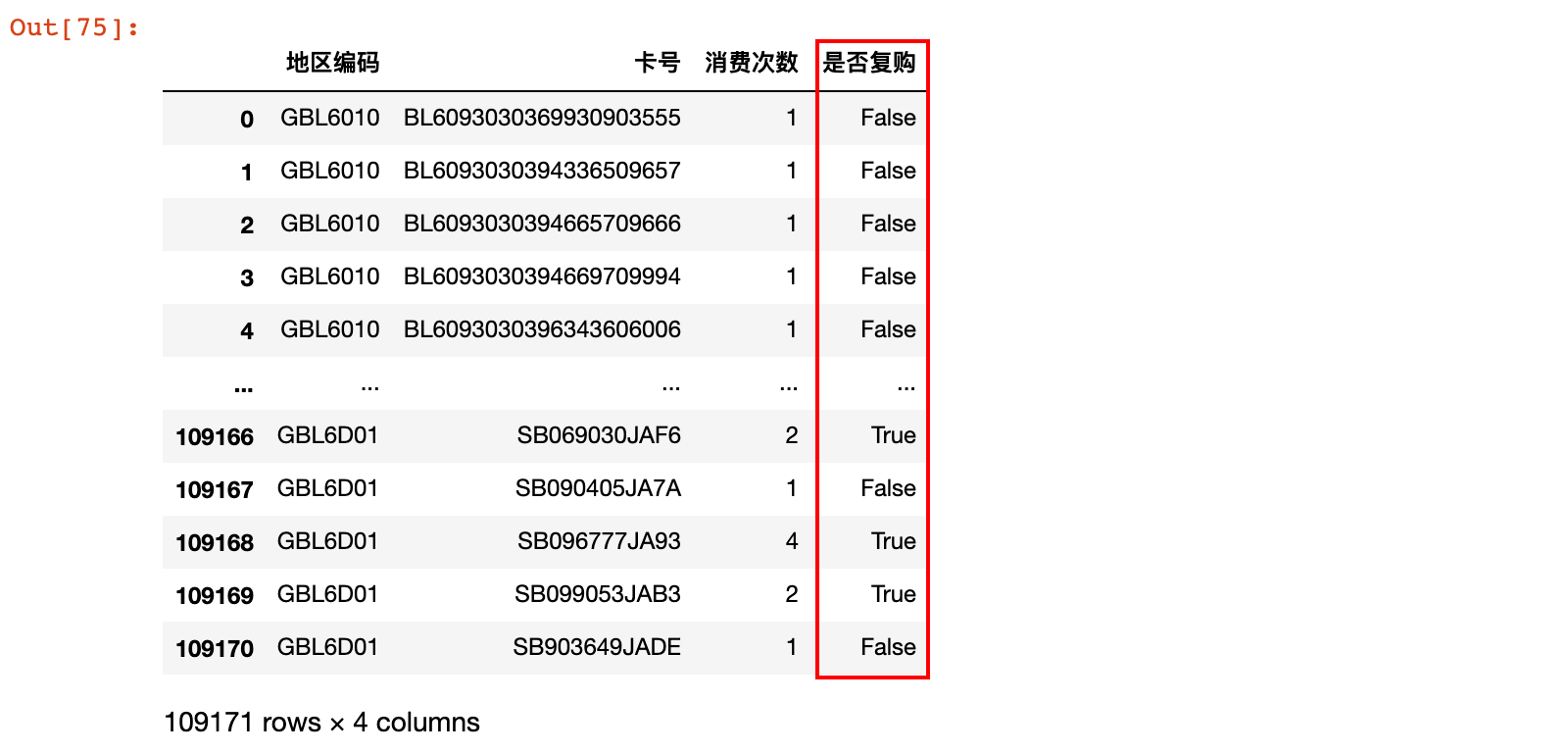
# 判断是否复购
consume_count['是否复购'] = consume_count['消费次数'] > 1
consume_count
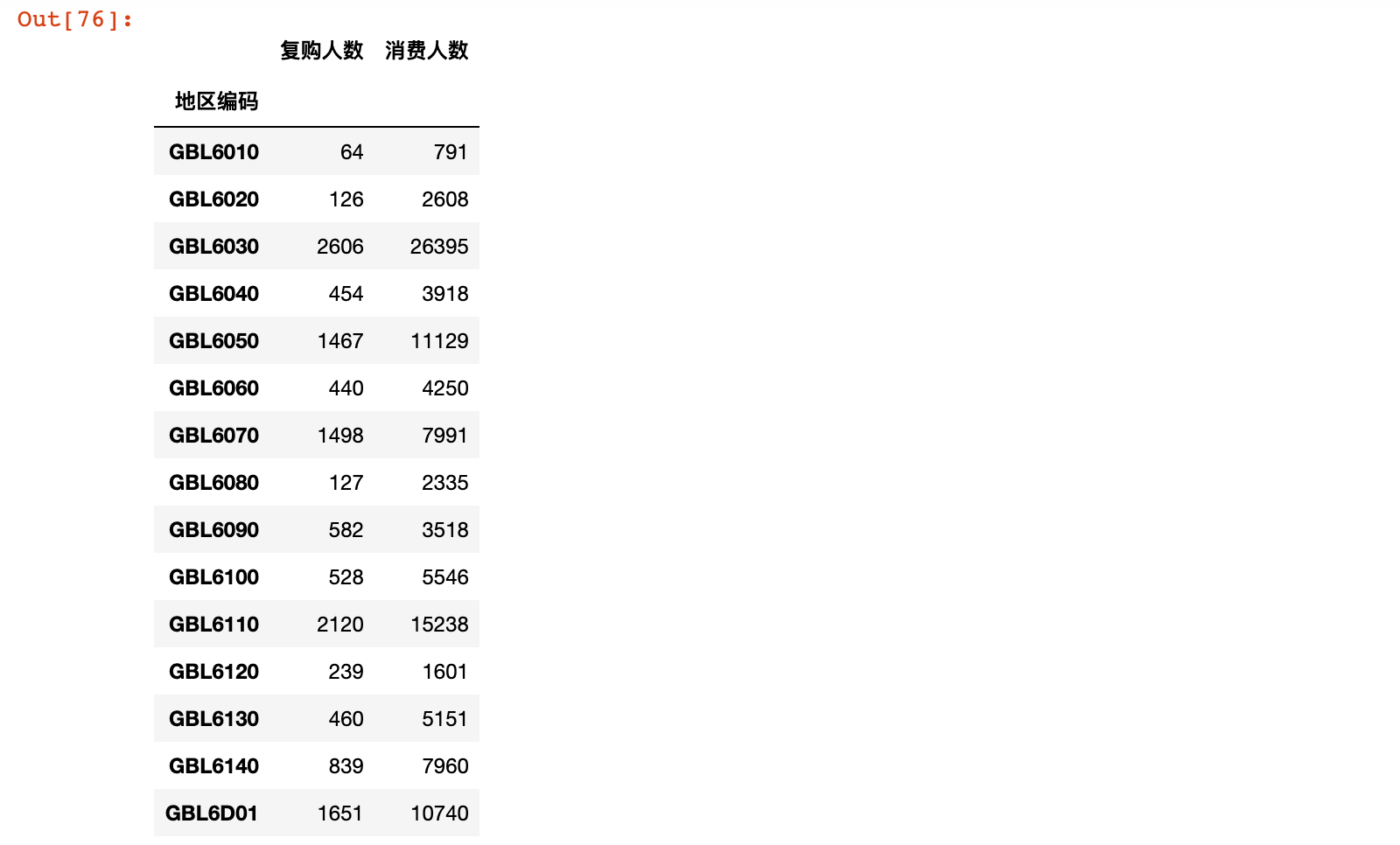
3)按地区统计复购人数和消费人数
depart_data = consume_count.pivot_table(
values=['消费次数', '是否复购'],
index='地区编码', aggfunc={'消费次数': 'count', '是否复购': 'sum'})
depart_data.columns = ['复购人数', '消费人数']
depart_data
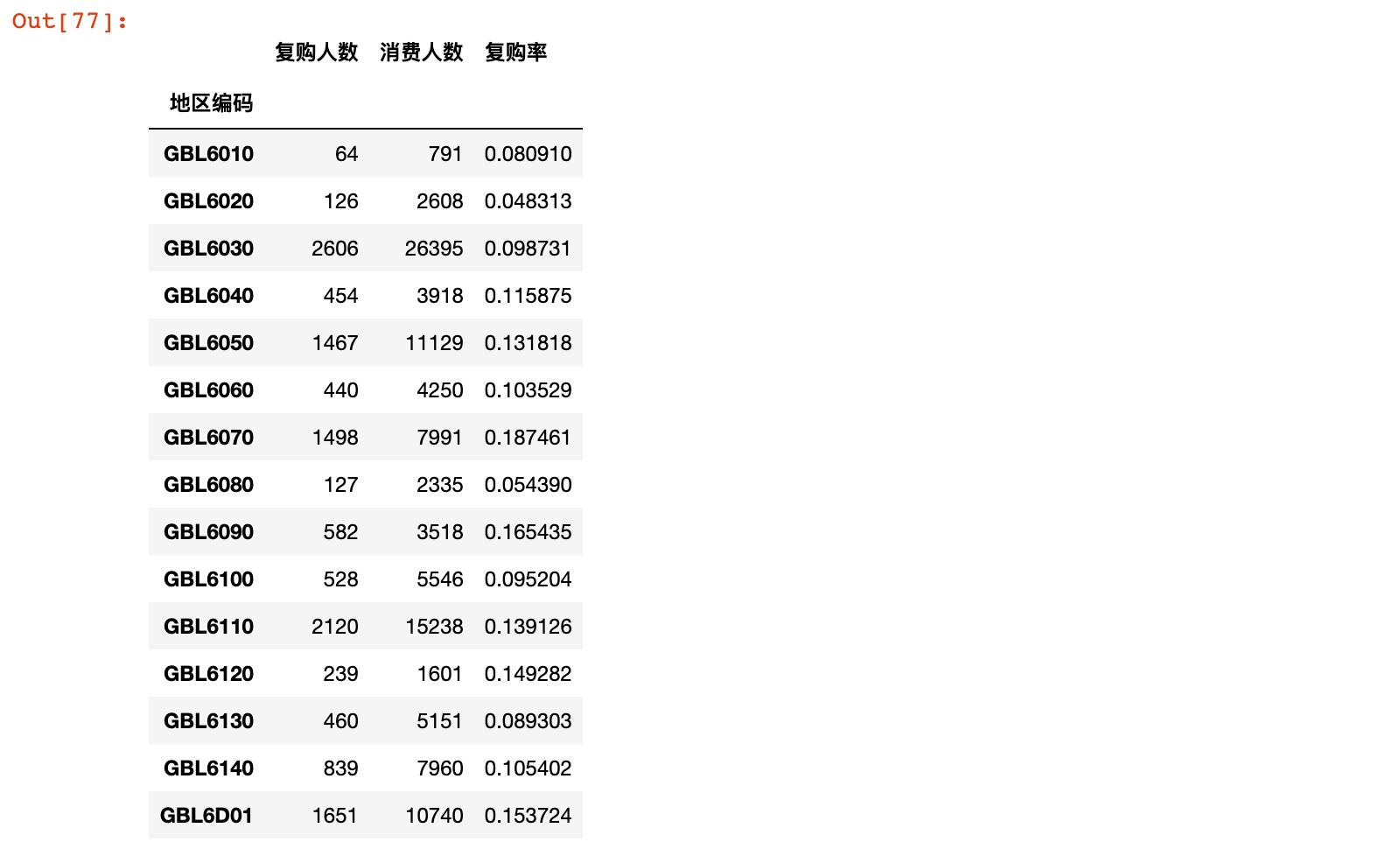
4)计算复购率
depart_data['复购率'] = depart_data['复购人数']/depart_data['消费人数']
depart_data
5)定义计算指定时间范围复购率的函数
def stats_reorder(start, end, col):
"""统计指定起始年月的复购率"""
# 会员下单消费数据和地区门店数据进行 merge
order_data = member_consume[['年月', '订单日期', '卡号', '订单号', '订单类型', '店铺代码']].merge(store_info[['店铺代码', '地区编码']], on='店铺代码').query('订单类型!="退单"')
# 筛选日期
order_data= order_data[(order_data['年月']<=end) & (order_data['年月']>=start)]
# 因为需要用到地区编号和年月 所以选择 年月、订单日期、卡号、地区编码 四个字段一起去重
order_data=order_data[['年月', '订单日期', '卡号', '地区编码']].drop_duplicates()
# 按照地区编码和卡号进行分组 统计订单日期数量 就是每个地区每个会员的购买次数
consume_count = order_data.pivot_table(index =['地区编码','卡号'],values='年月',aggfunc='count').reset_index()
# 重命名列
consume_count.rename(columns={'年月':'消费次数'},inplace=True)
# 判断是否复购
consume_count['是否复购']=consume_count['消费次数']>1
# 统计每个地区的购买人数和复购人数
depart_data=consume_count.pivot_table(index = ['地区编码'],values=['消费次数','是否复购'],aggfunc={'消费次数':'count','是否复购':'sum'})
# 重命名列
depart_data.columns=['复购人数','购买人数']
# 计算复购率
depart_data[col+'复购率']=depart_data['复购人数']/depart_data['购买人数']
return depart_data
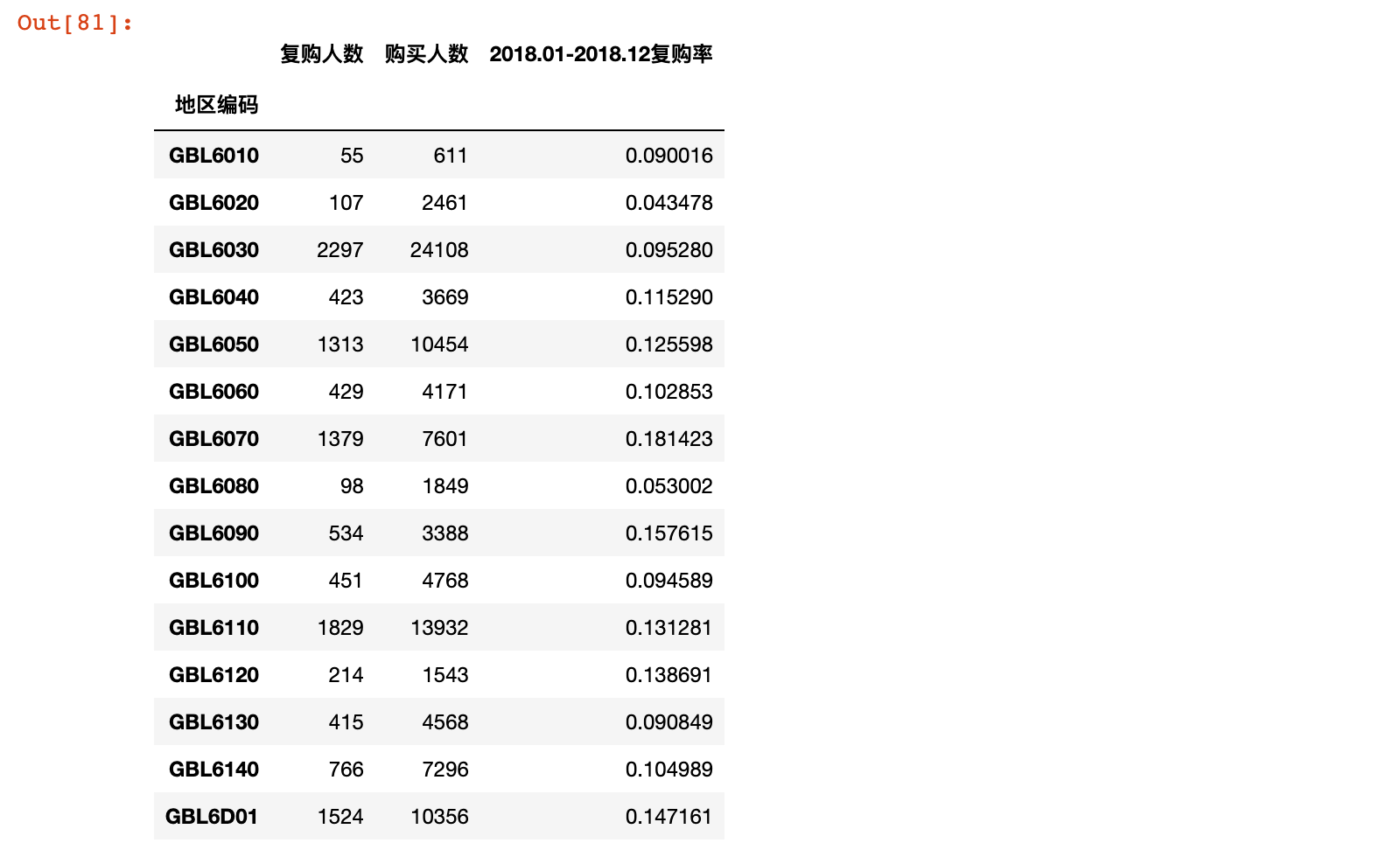
6)统计2018年01月~2018年12月复购率和2018年02月~2019年01月复购率
reorder_2018 = stats_reorder(201801, 201812, '2018.01-2018.12')
reorder_2018
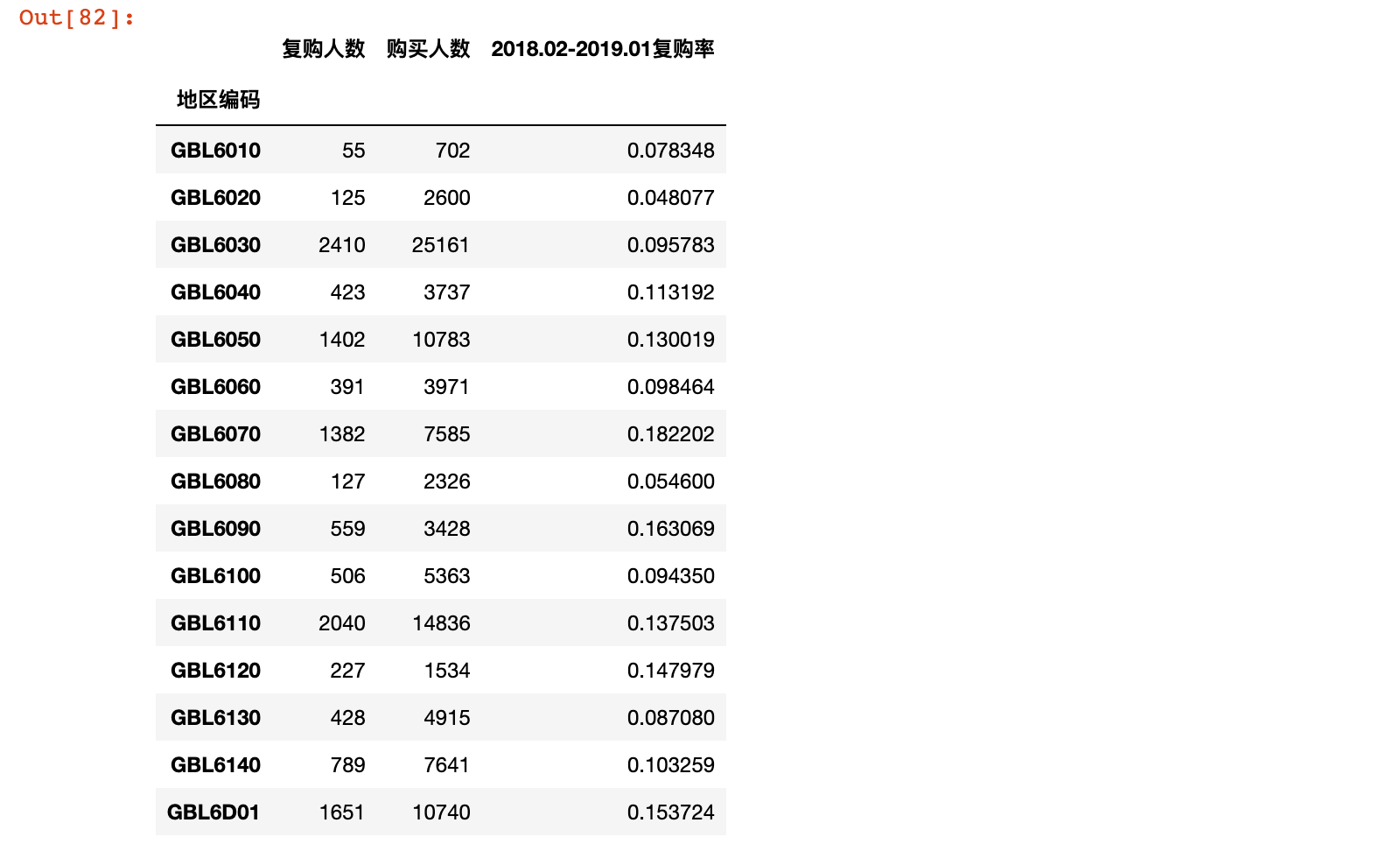
reorder_2019 = stats_reorder(201802, 201901, '2018.02-2019.01')
reorder_2019
7)计算2018年01月~2018年12月和2018年02月~2019年01月复购率环比
result = pd.concat([reorder_2018['2018.01-2018.12复购率'], reorder_2019['2018.02-2019.01复购率']], axis=1)
result
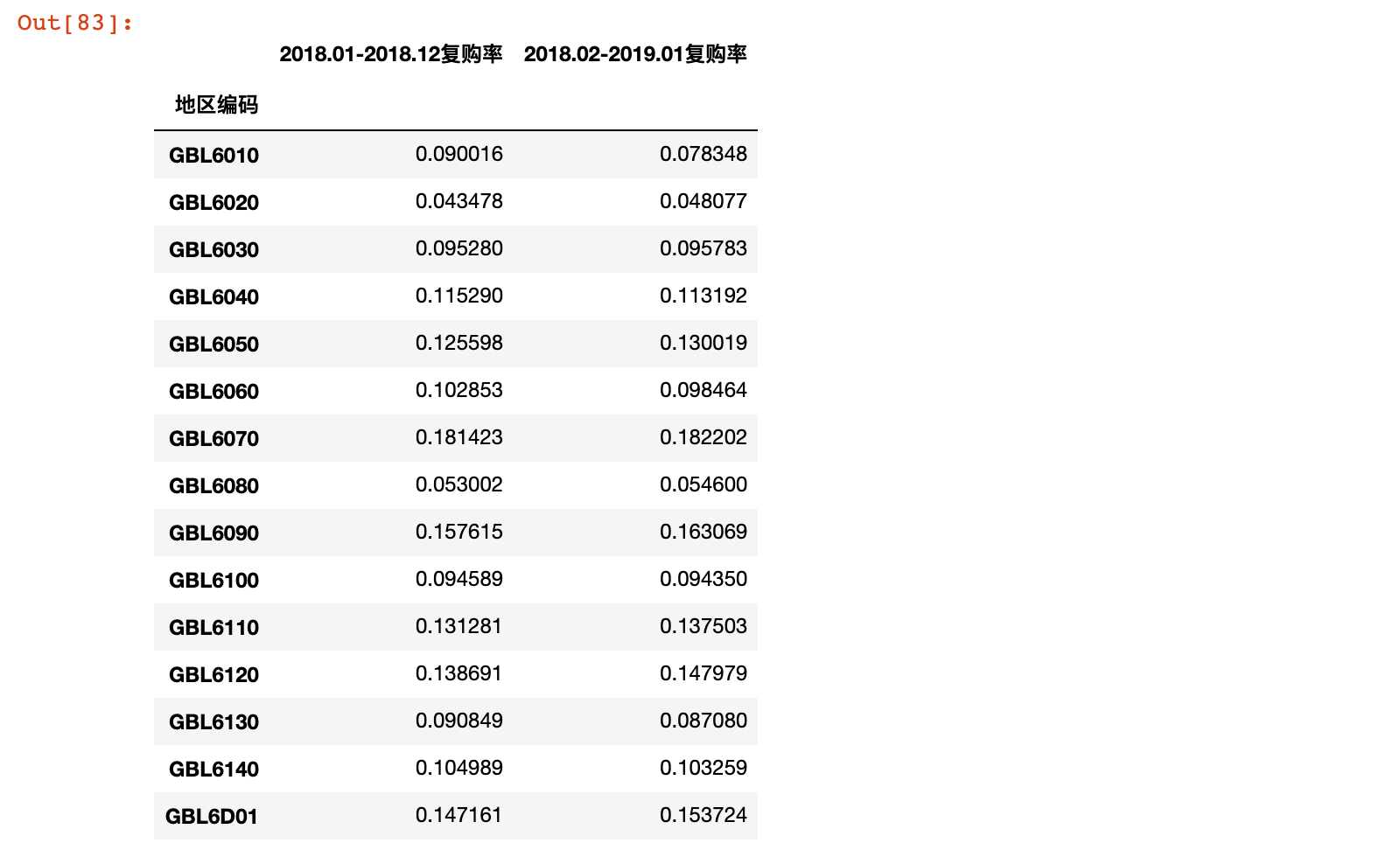
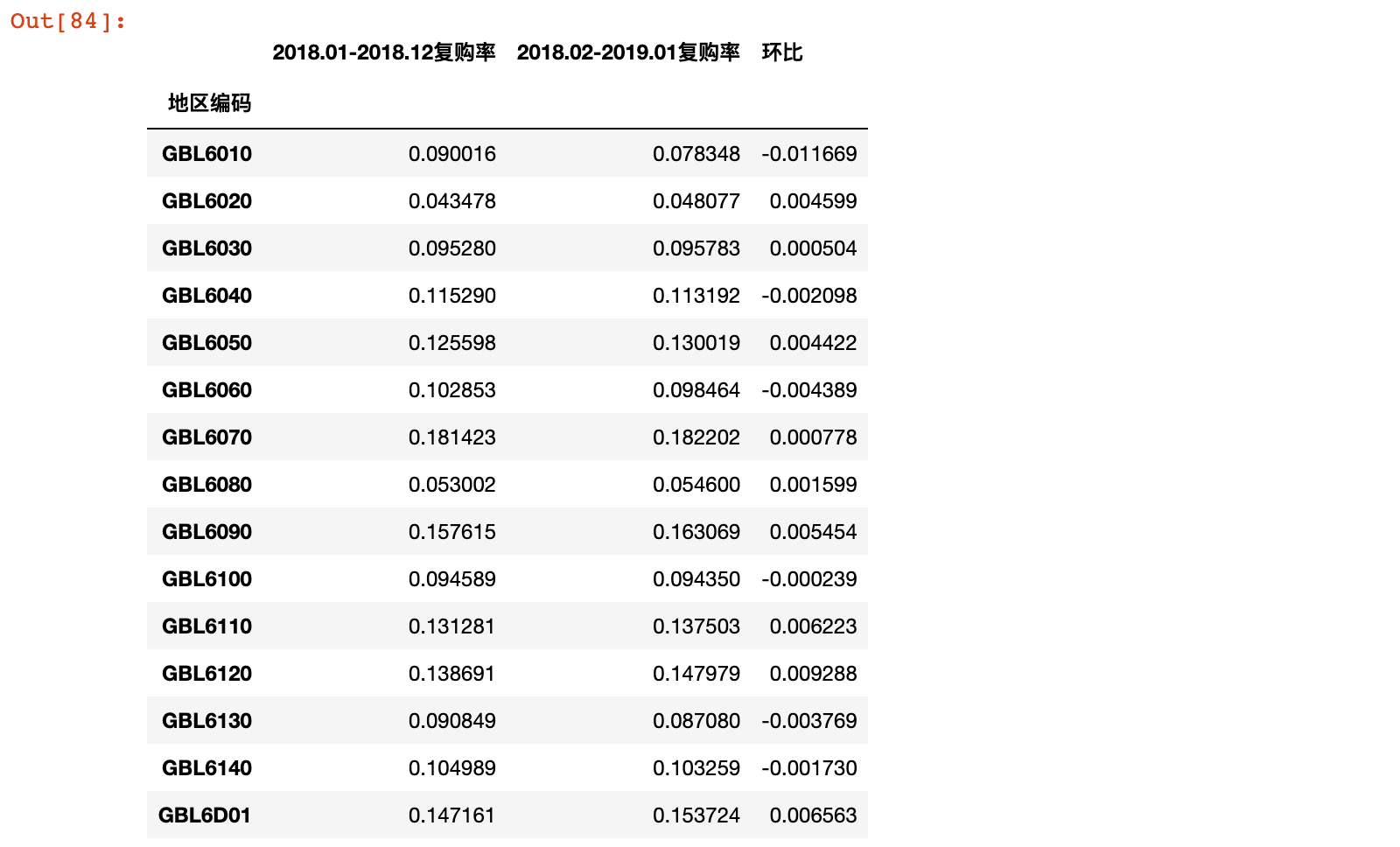
result['环比'] = result['2018.02-2019.01复购率'] - result['2018.01-2018.12复购率']
result
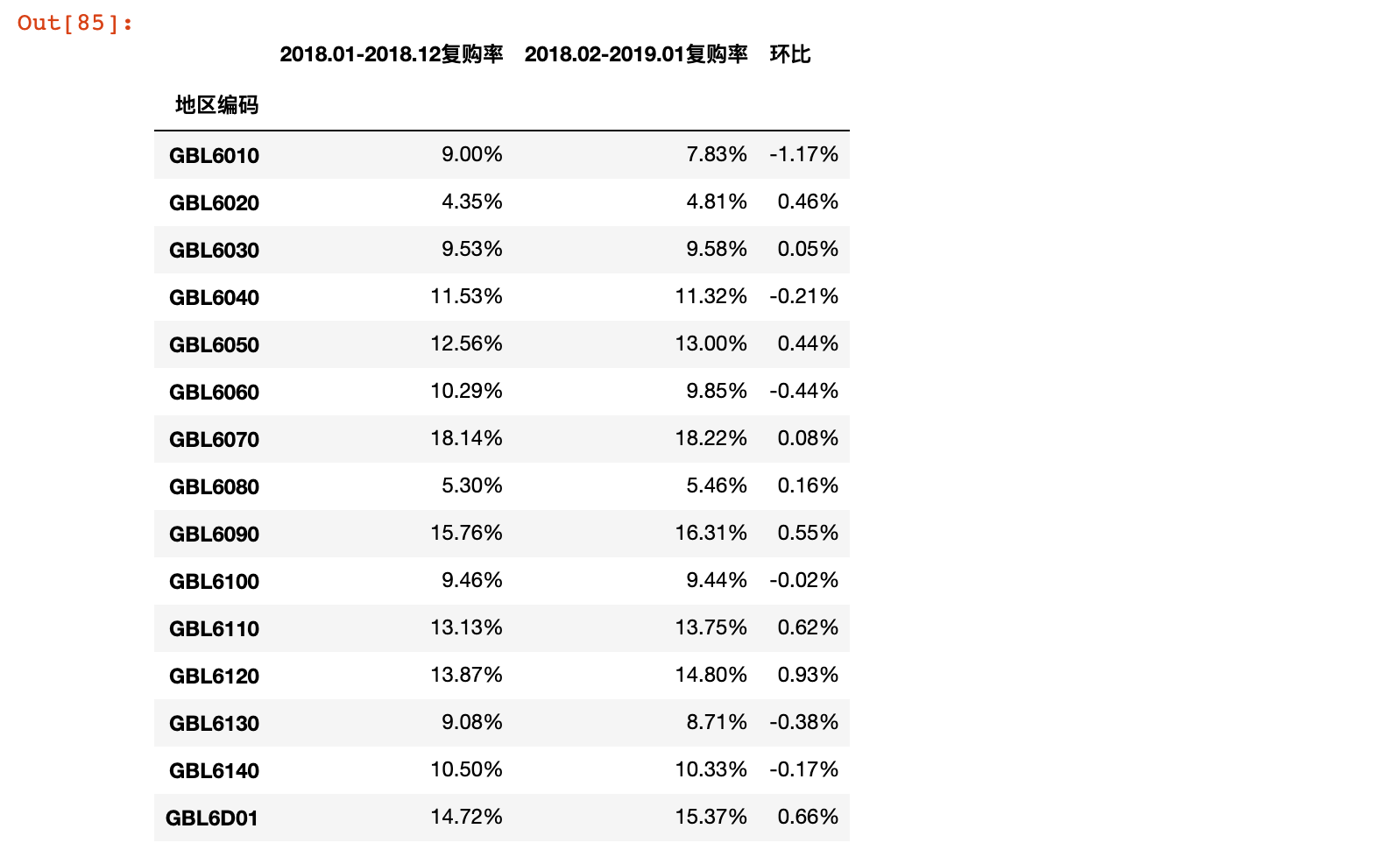
result = result.applymap(lambda x: format(x, '.2%'))
result
总结
- 透视表是数据分析中经常使用的 API,跟 Excel 中的数据透视表功能类似
- pandas 的数据透视表:pivot_table,常用几个参数 index、values、columns、aggfuc、margin
- pandas 的数据透视表功能与 groupby 功能类似