pandas数据类型
学习目标
- 了解 Numpy 的特点
- 应用 pandas 数据类型转换
- 掌握 pandas 分类数据类型使用方法
1. pandas 数据类型简介
1.1 Numpy 介绍
Numpy(Numerical Python)是一个开源的Python科学计算库,用于快速处理任意维度的数组。
1)Numpy 支持常见的数组和矩阵操作
- 对于同样的数值计算任务,使用 Numpy 比直接使用 Python 要简洁的多
2)Numpy 使用ndarray对象来处理多维数组,该对象是一个快速而灵活的大数据容器
比如我们现在对下面表格中的数据用 Numpy 的 ndarray 类型来存储:
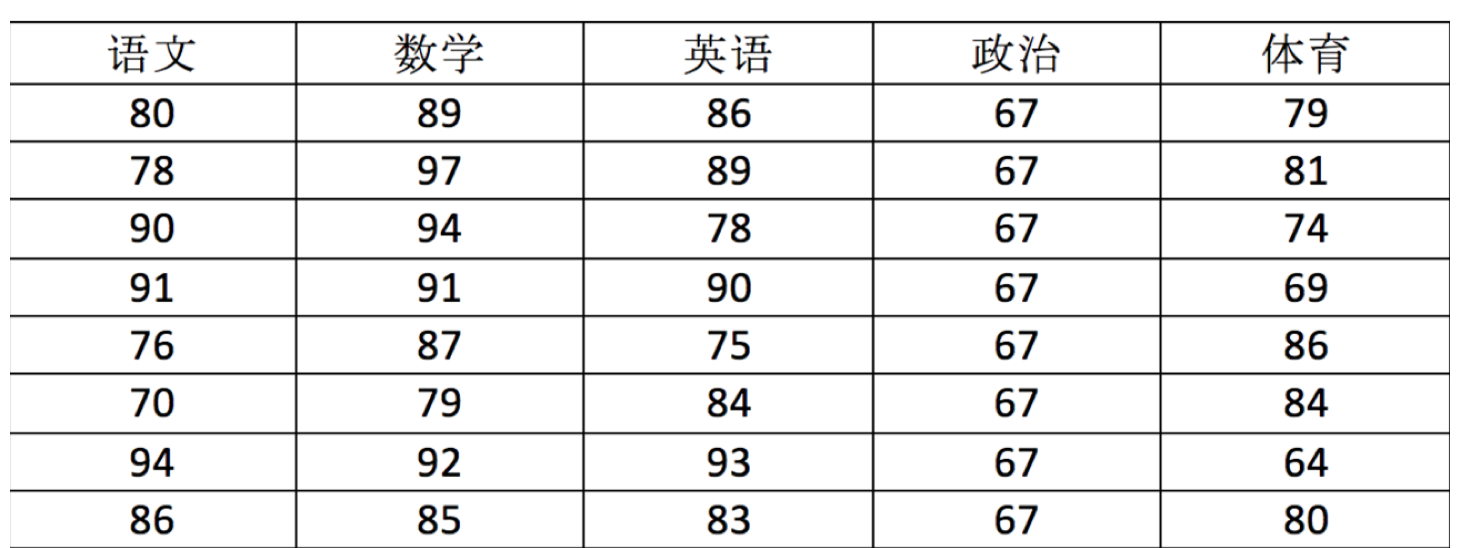
import numpy as np
# 创建ndarray
score = np.array([
[80, 89, 86, 67, 79],
[78, 97, 89, 67, 81],
[90, 94, 78, 67, 74],
[91, 91, 90, 67, 69],
[76, 87, 75, 67, 86],
[70, 79, 84, 67, 84],
[94, 92, 93, 67, 64],
[86, 85, 83, 67, 80]
])
print(score)
print(type(score))

思考:使用 Python 列表可以存储一维数组,通过列表的嵌套可以实现存储多维数组,那么为什么还需要使用Numpy的ndarray呢?
答:我们来做一个ndarray与Python原生list运算效率对比,ndarry 计算效率更高
import random
import time
import numpy as np
a = []
for i in range(1000000):
a.append(random.random())
t1 = time.time()
sum1=sum(a)
t2=time.time()
b=np.array(a)
t3=time.time()
sum2=np.sum(b)
t4=time.time()
print(t2-t1, t4-t3)
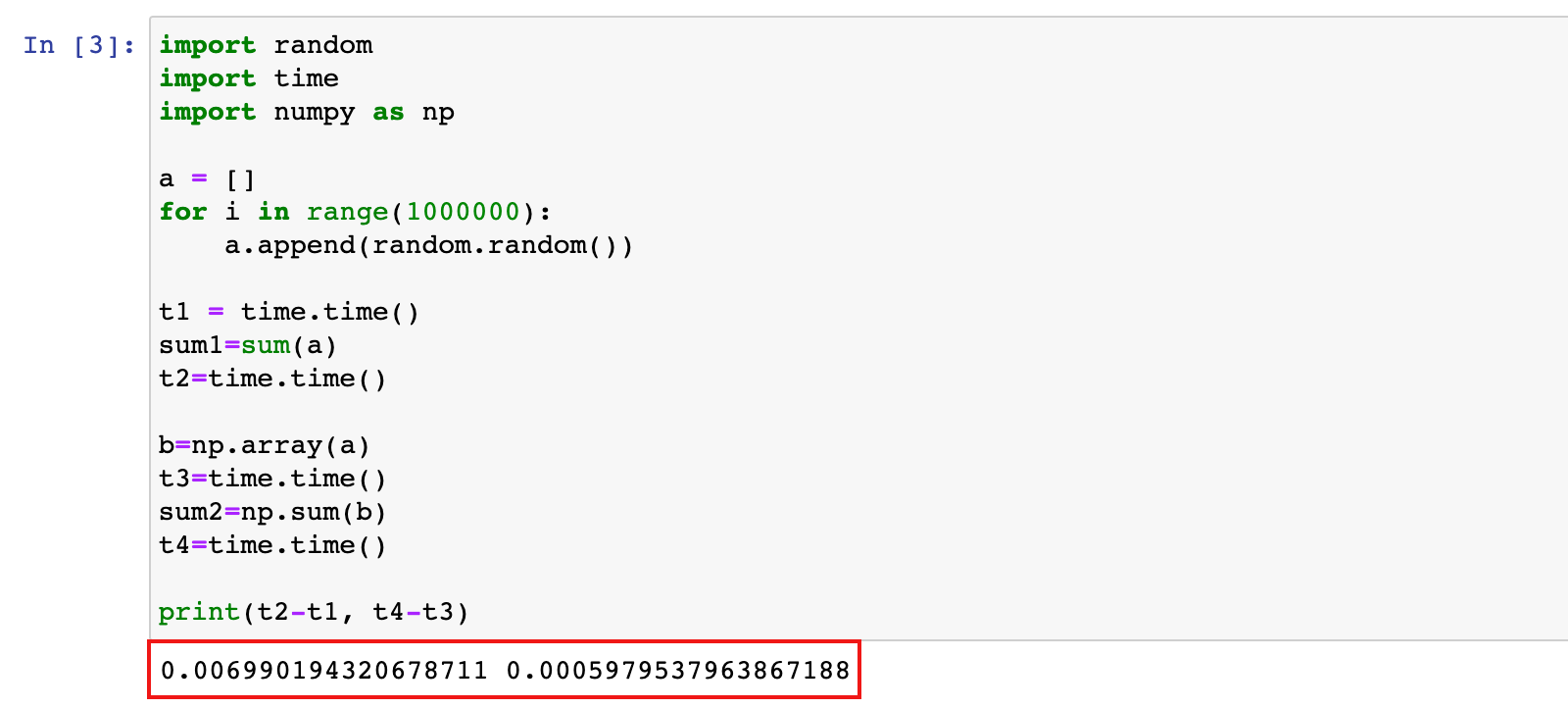
Numpy专门针对ndarray的操作和运算进行了设计,所以数组的存储效率和输入输出性能远优于Python中的嵌套列表,数组越大,Numpy的优势就越明显
Numpy ndarray的优势:
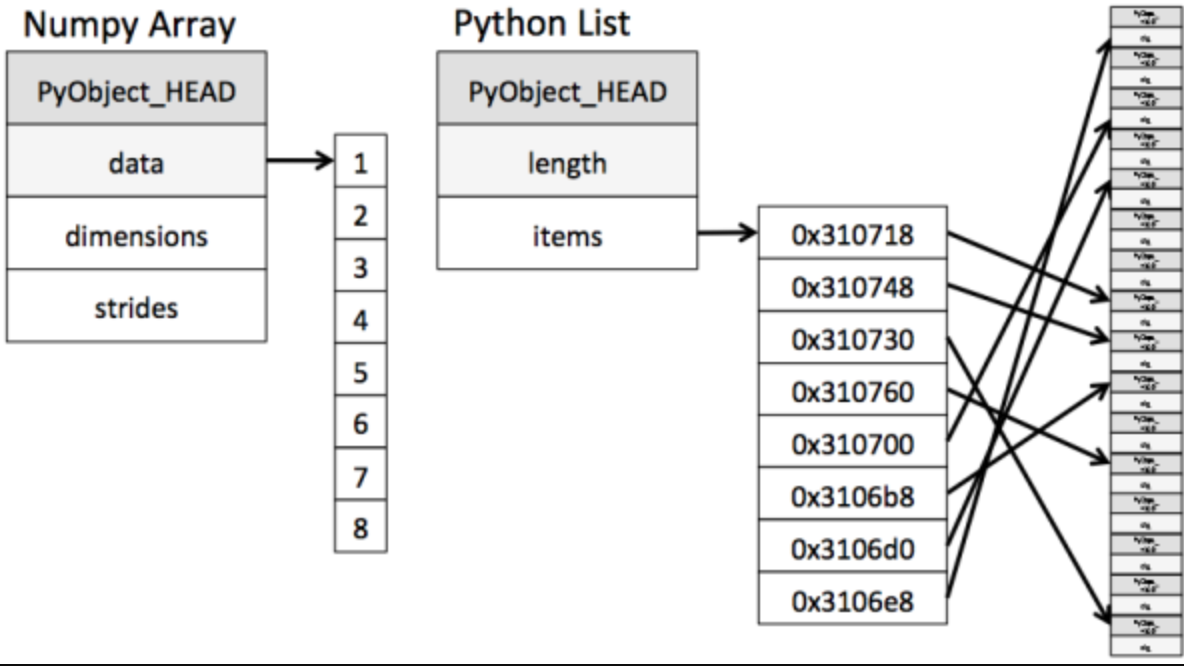
1)数据在内存中存储的风格
- ndarray 在存储数据时所有元素的类型都是相同的,数据内存地址是连续的,批量操作数组元素时速度更快
- python 原生 list 只能通过寻址方式找到下一个元素,这虽然也导致了在通用性方面 Numpy 的 ndarray 不及python 原生 list,但计算的时候速度就慢了
2)ndarray 支持并行化运算
3)Numpy 底层使用 C 语言编写,内部解除了 GIL(全局解释器锁),其对数组的操作速度不受 python 解释器的限制,可以利用CPU的多核心进行运算,效率远高于纯 python 代码
1.2 Numpy 的 ndarray
1.2.1 ndarray 的属性
ndarray的属性清单:
| 属性 | 说明 |
|---|---|
| ndarray.shape | 数组维度的元组 |
| ndarray.ndim | 数组维数 |
| ndarray.size | 数组中的元素数量 |
| ndarray.itemsize | 一个数组元素的长度(字节) |
| ndarray.dtype | 数组元素的类型 |
执行下面的代码:
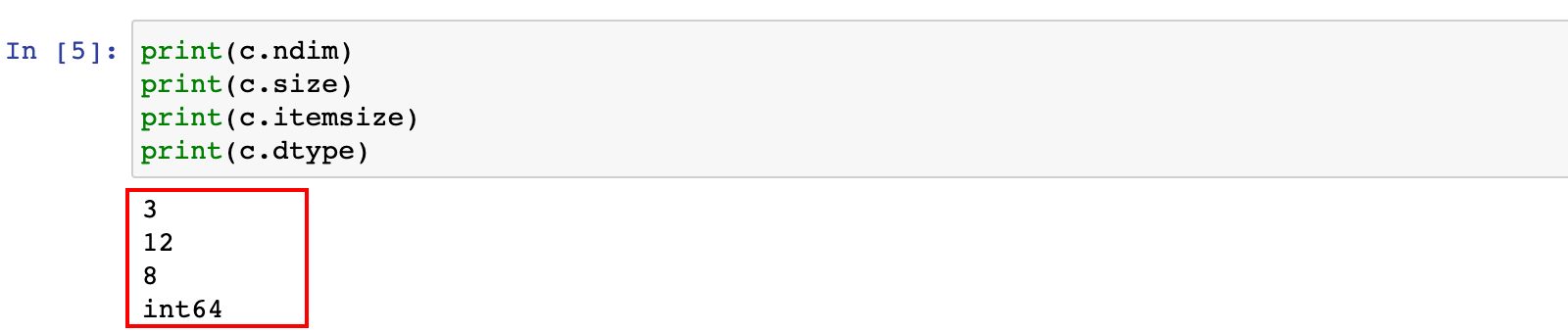
a = np.array([1, 2, 3, 4])
b = np.array([[1, 2, 3], [4, 5, 6]])
c = np.array([[[1, 2, 3], [4, 5, 6]], [[1, 2, 3], [4, 5, 6]]])
print(a.shape)
print(b.shape)
print(c.shape)

print(c.ndim)
print(c.size)
print(c.itemsize)
print(c.dtype)
1.2.2 ndarray 的类型
下表为ndarray的全部数据类型;最常用的类型是布尔和int64,其他只要了解就好:
| 名称 | 描述 | 简写 |
|---|---|---|
| np.bool | 用一个字节存储的布尔类型(True或False) | 'b' |
| np.int8 | 一个字节大小,-128 至 127 | 'i' |
| np.int16 | 整数,-32768 至 32767 | 'i2' |
| np.int32 | 整数,-2的31次方 至 2的32次方 -1 | 'i4' |
| np.int64 | 整数,-2的63次方 至 2的63次方 - 1 | 'i8' |
| np.uint8 | 无符号整数,0 至 255 | 'u' |
| np.uint16 | 无符号整数,0 至 65535 | 'u2' |
| np.uint32 | 无符号整数,0 至 2的32次方 - 1 | 'u4' |
| np.uint64 | 无符号整数,0 至 2的64次方 - 1 | 'u8' |
| np.float16 | 半精度浮点数:16位,正负号1位,指数5位,精度10位 | 'f2' |
| np.float32 | 单精度浮点数:32位,正负号1位,指数8位,精度23位 | 'f4' |
| np.float64 | 双精度浮点数:64位,正负号1位,指数11位,精度52位 | 'f8' |
| np.complex64 | 复数,分别用两个32位浮点数表示实部和虚部 | 'c8' |
| np.complex128 | 复数,分别用两个64位浮点数表示实部和虚部 | 'c16' |
| np.object_ | python对象 | 'O' |
| np.string_ | 字符串 | 'S' |
| np.unicode_ | unicode类型 |
创建 ndarry 的时候指定类型:
b = np.array([[1, 2, 3], [4, 5, 6]], dtype=np.float32)
b.dtype

1.3 pandas 的数据类型
pandas 是基于 Numpy 的,很多功能都依赖于 Numpy 的 ndarray 实现的,pandas 的数据类型很多与 Numpy 类似,属性也有很多类似。比如 pandas 数据中的 NaN 就是 numpy.nan
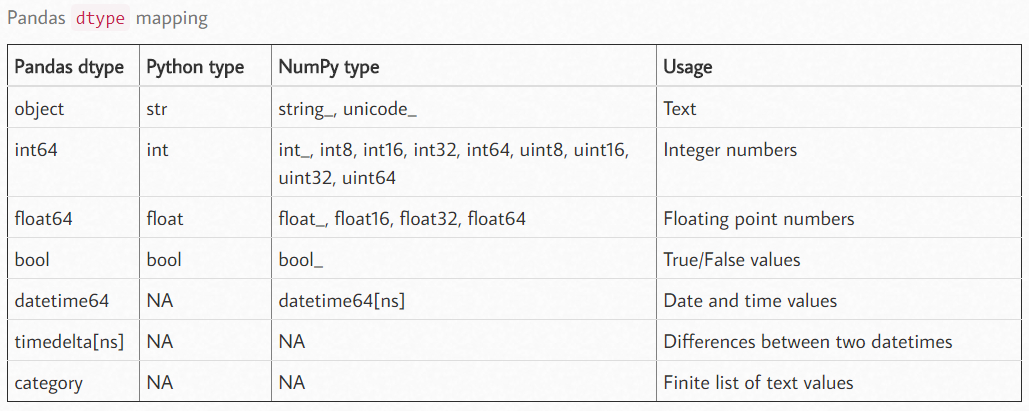
下图中为 pandas 的数据类型清单,其中 category 我们之前的学习中没有见过的:
- category 是由固定的且有限数量的变量组成的。比如:性别、社会阶层、血型、国籍、观察时段、赞美程度等等。
- category 类型的数据可以具有特定的顺序。比如:性别分为男、女,血型ABO。我们会在本章节的最后来了解这种数据类型。
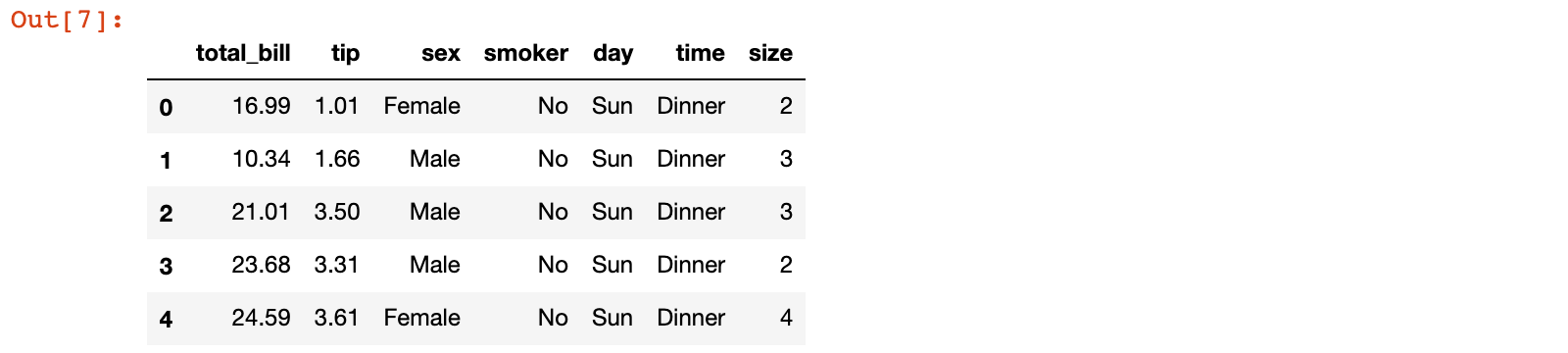
我们以 seaborn 包中自带的 tips 数据集为例,具体来查看数据类型:
import seaborn as sns
tips = sns.load_dataset('tips')
tips.head()
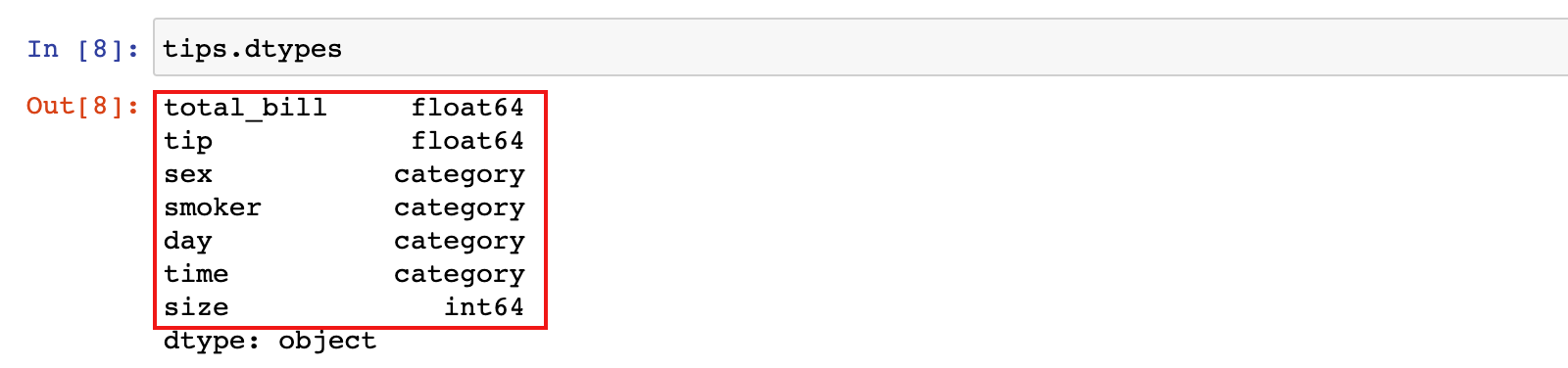
# 查看数据类型
tips.dtypes
2. 类型转换
2.1 astype函数
astype方法是通用函数,可用于把DataFrame中的任何列转换为其他dtype
可以向astype方法提供任何内置类型或numpy类型来转换列的数据类型
2.2 转换为字符串对象
在上面的tips数据中,sex、smoker、day 和 time 变量都是category类型。通常,如果变量不是数值类型,应先将其转换成字符串类型以便后续处理
有些数据集中可能含有id列,id的值虽然是数字,但对id进行计算(求和,求平均等)没有任何意义,在某些情况下,可能需要把它们转换为字符串对象类型。
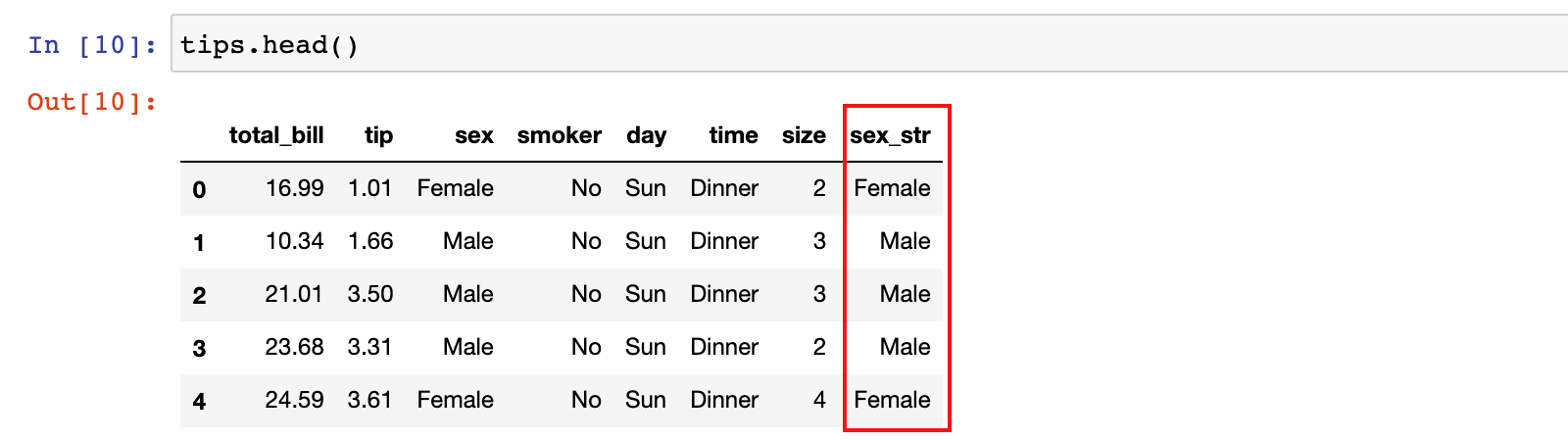
1)把一列的数据类型转换为字符串,可以使用 astype方法:
tips['sex_str'] = tips['sex'].astype(str)
print(tips.dtypes)
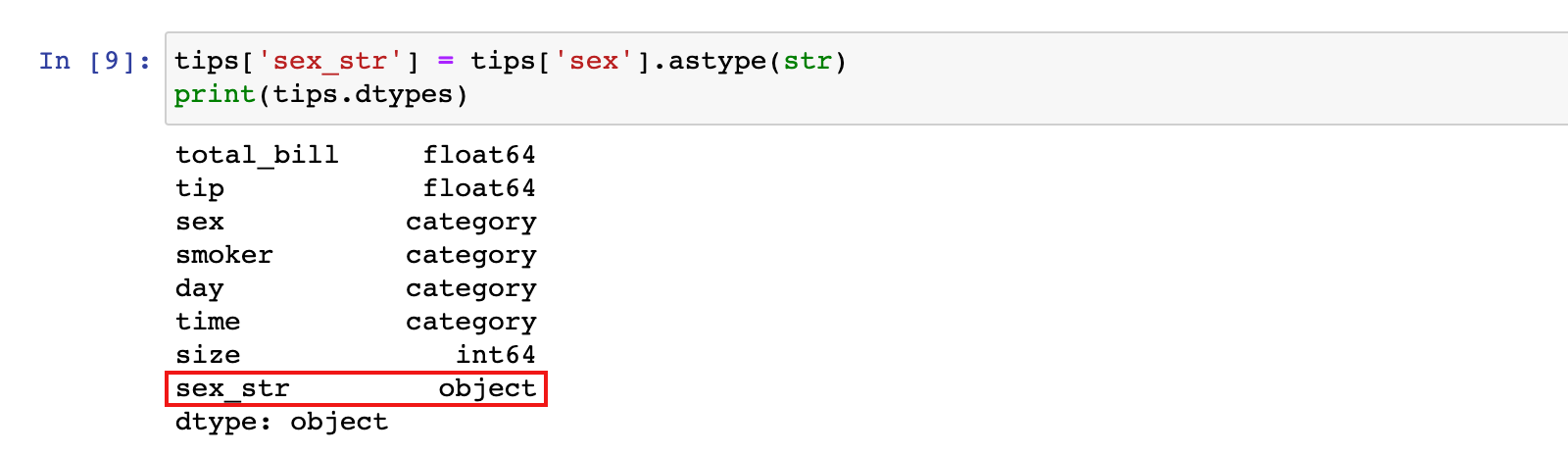
tips
2.3 转换为数值类型
2.3.1 使用 astype 函数
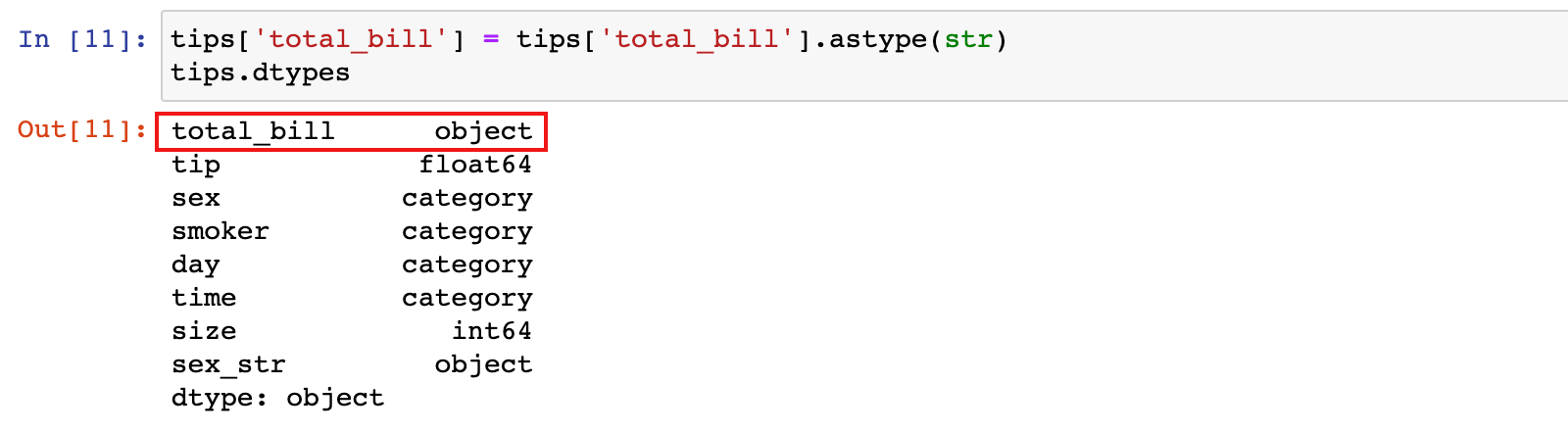
1)为了演示效果,先把total_bill列转为object/str类型
tips['total_bill'] = tips['total_bill'].astype(str)
tips.dtypes
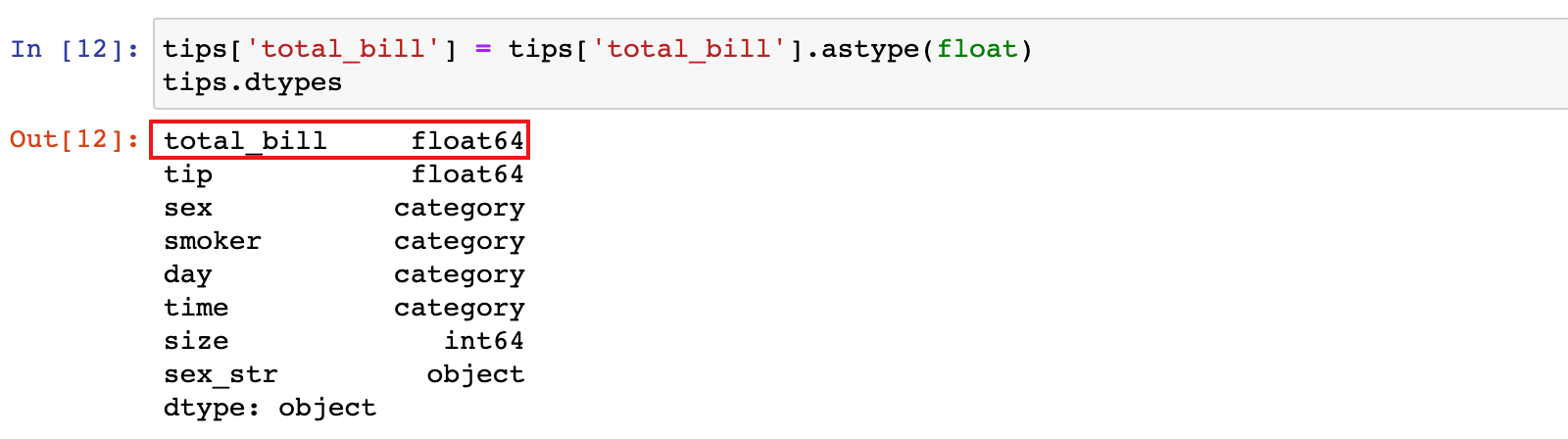
2)再把`object/str类型的total_bill列转为float64/float类型
tips['total_bill'] = tips['total_bill'].astype(float)
tips.dtypes
2.2.2 to_numeric 函数
如果想把变量转换为数值类型(int、float),还可以使用 pandas 的 to_numeric 函数
astype 函数要求 DataFrame 每一列的数据类型必须相同,当有些数据中有缺失,但不是 NaN 时(如'missing'、'null'等),会使整列数据变成字符串类型而不是数值型,这个时候可以使用 to_numeric 处理
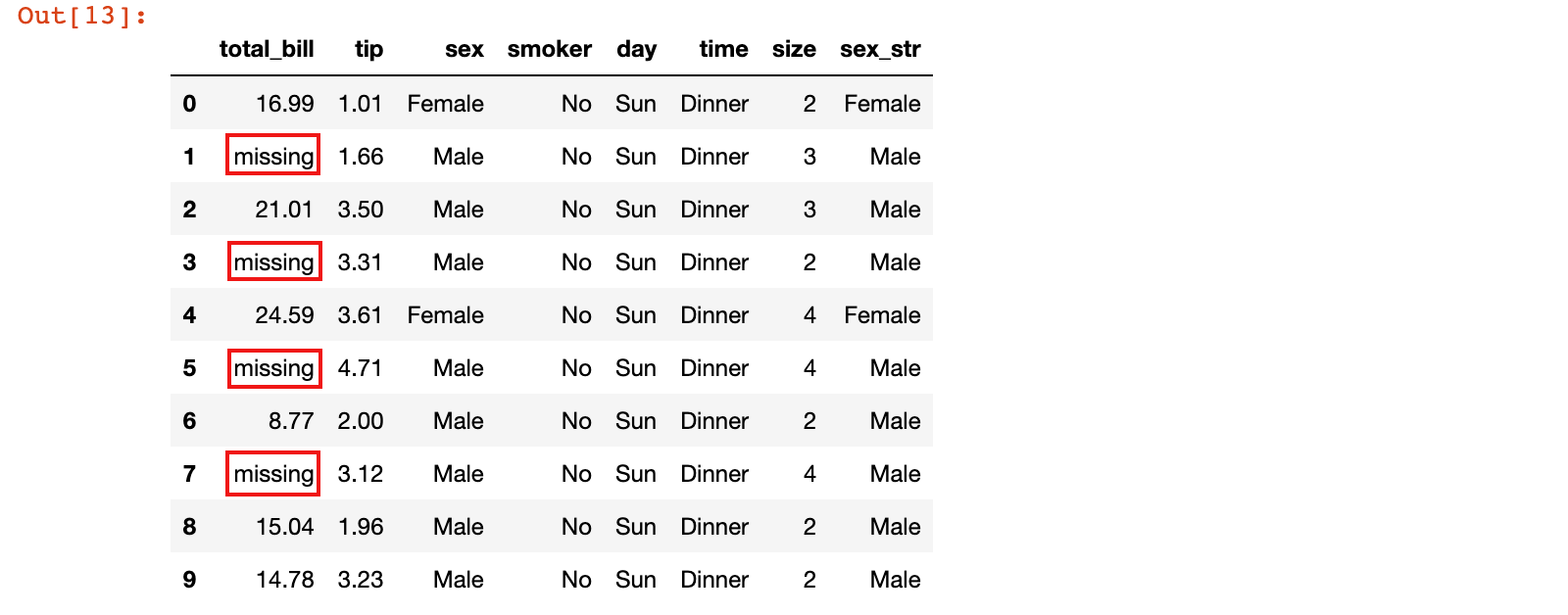
1)抽取部分数据,人为制造'missing'作为缺失值的 df 数据
tips_sub_miss = tips.head(10)
tips_sub_miss.loc[[1, 3, 5, 7], 'total_bill'] = 'missing'
tips_sub_miss
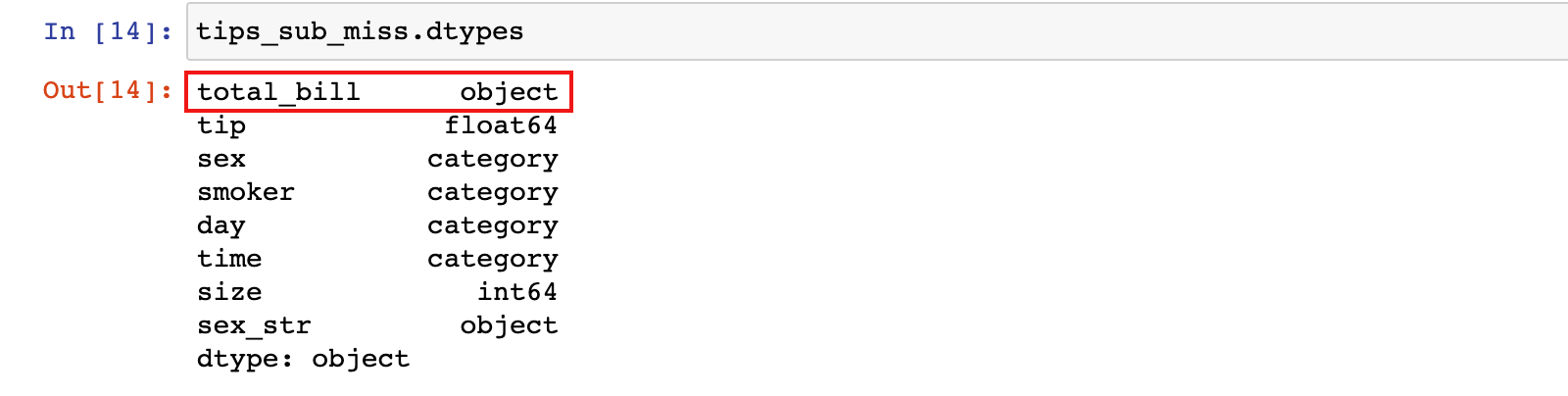
2)此时 total_bill 列变成了字符串对象类型
tips_sub_miss.dtypes
3)这时使用 astype 方法把 total_bill 列转换回float类型,会抛错,pandas 无法把'missing'转换成float
# 这句代码会出错
tips_sub_miss['total_bill'].astype(float)

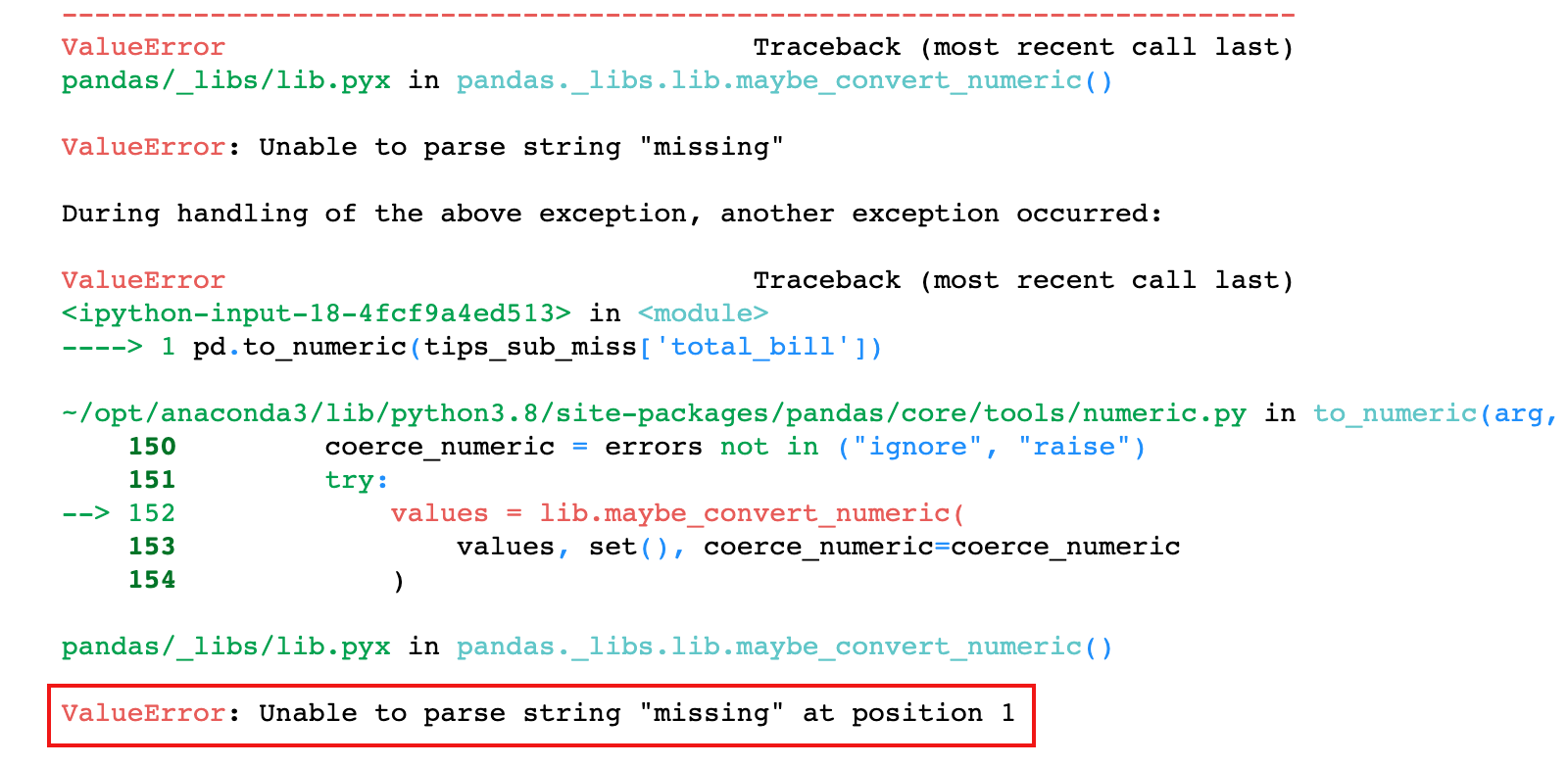
4)如果使用 pandas 库中的 to_numeric 函数进行转换,默认也会得到类似的错误
# 这句代码也会出错
pd.to_numeric(tips_sub_miss['total_bill'])
to_numeric 函数有一个参数 errors,它决定了当该函数遇到无法转换的数值时该如何处理:
1)默认情况下,该值为 raise,如果 to_numeric 遇到无法转换的值时,会抛错
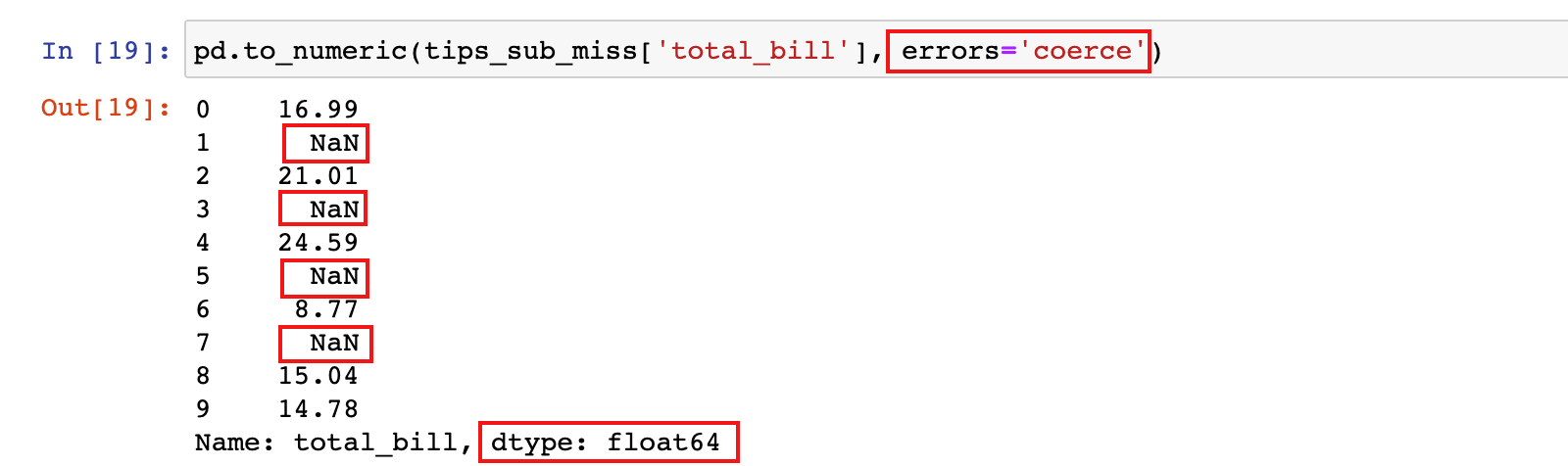
2)设置为
coerce:如果 to_numeric 遇到无法转换的值时,会返回NaN3)设置为
ignore:如果 to_numeric 遇到无法转换的值时,会放弃转换,什么都不做
pd.to_numeric(tips_sub_miss['total_bill'], errors='coerce')
pd.to_numeric(tips_sub_miss['total_bill'], errors='ignore')

to_numeric 函数还有一个
downcast参数,默认是None,接受的参数值为integer、signed、float和unsigned:1)如果设置了某一类型的数据,那么 pandas 会将原始数据转为能存储的最小子型态
2)如float的子型态有float16、float32、float64,所以设置了downcast=float,则会将数据转为能够以较少bytes去存储一个浮点数的float16
3)另外,downcast 参数和 errors 参数是分开的,如果 downcast 过程中出错,即使 errors 设置为 ignore 也会抛出异常
# downcast参数设置为float之后, total_bill的数据类型由float64变为float32
pd.to_numeric(tips_sub_miss['total_bill'], errors='coerce', downcast='float')
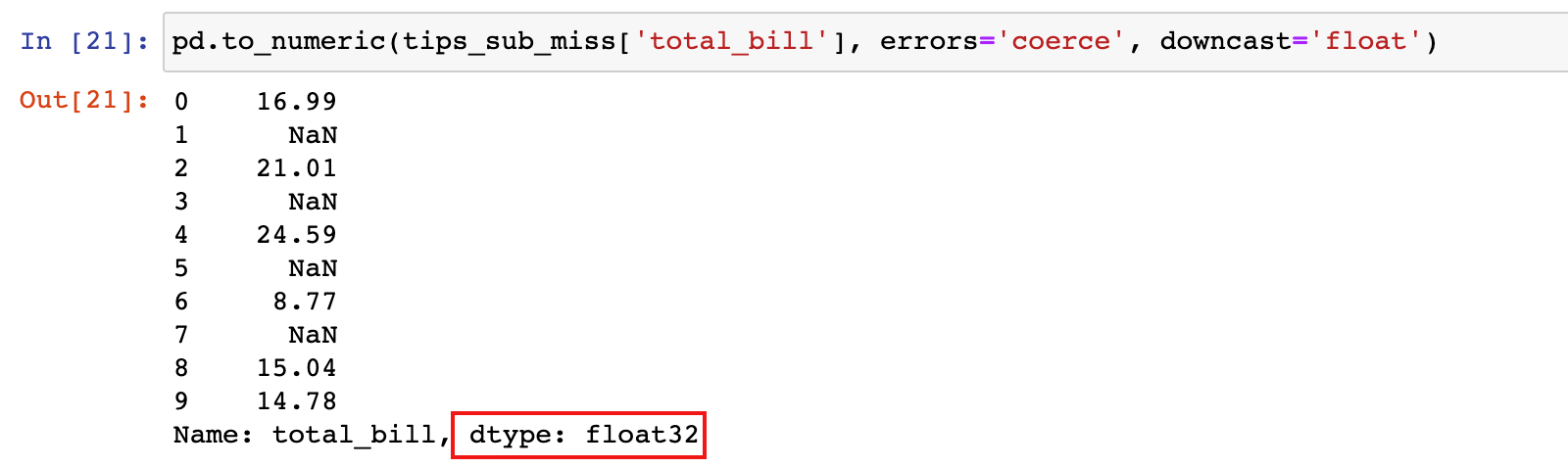
结果说明:从上面的结果看出,转换之后的数据类型为float32,意味着占用的内存更小了
3. 分类数据类型 category
在本章的1.3小节我们知道,pandas 有一种数据类型
category,用于对分类值进行编码
3.1 category 类型转换
1)category 转换为 object/str
tips['sex'] = tips['sex'].astype(str)
tips.info()
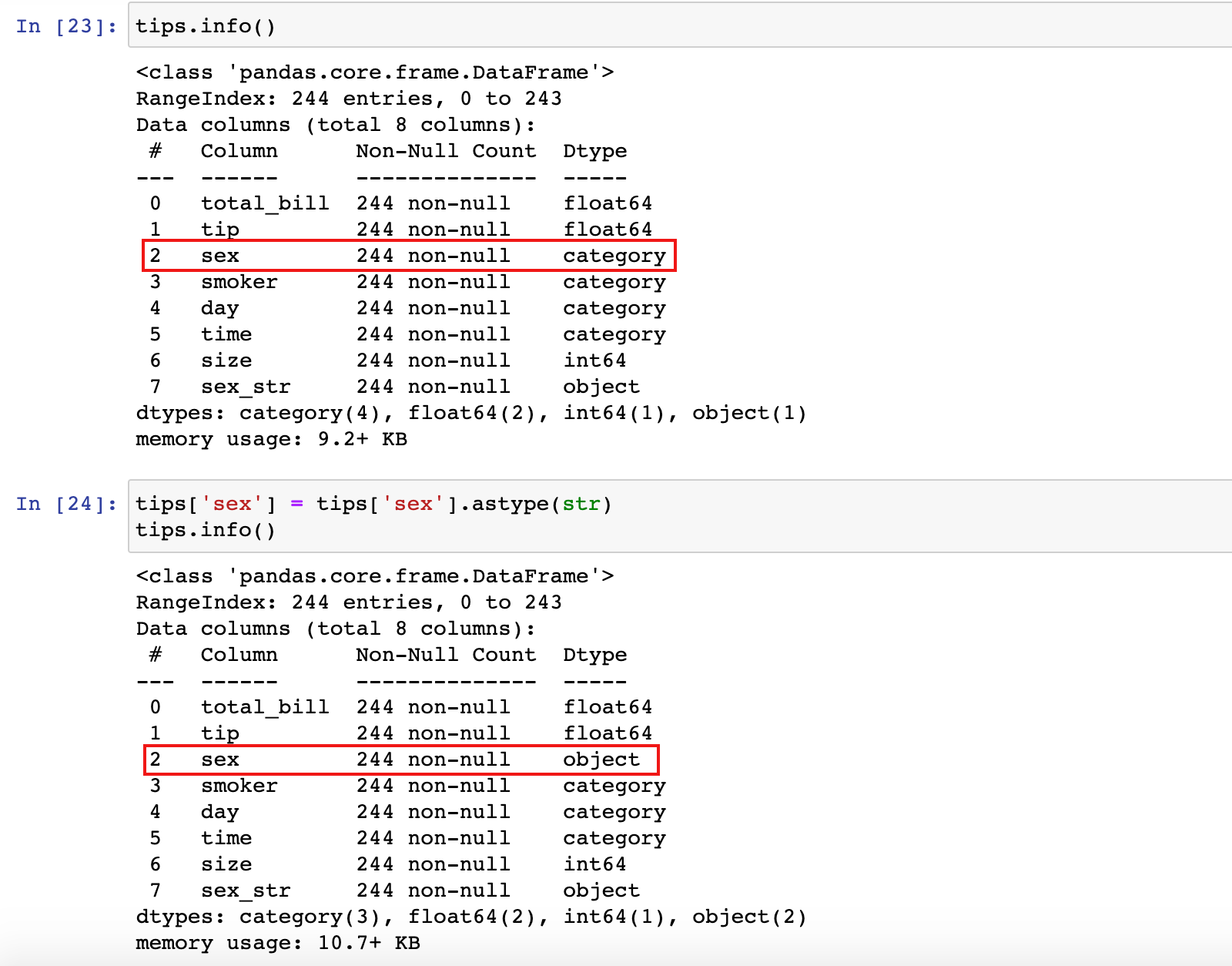
2)object/str转换为 category
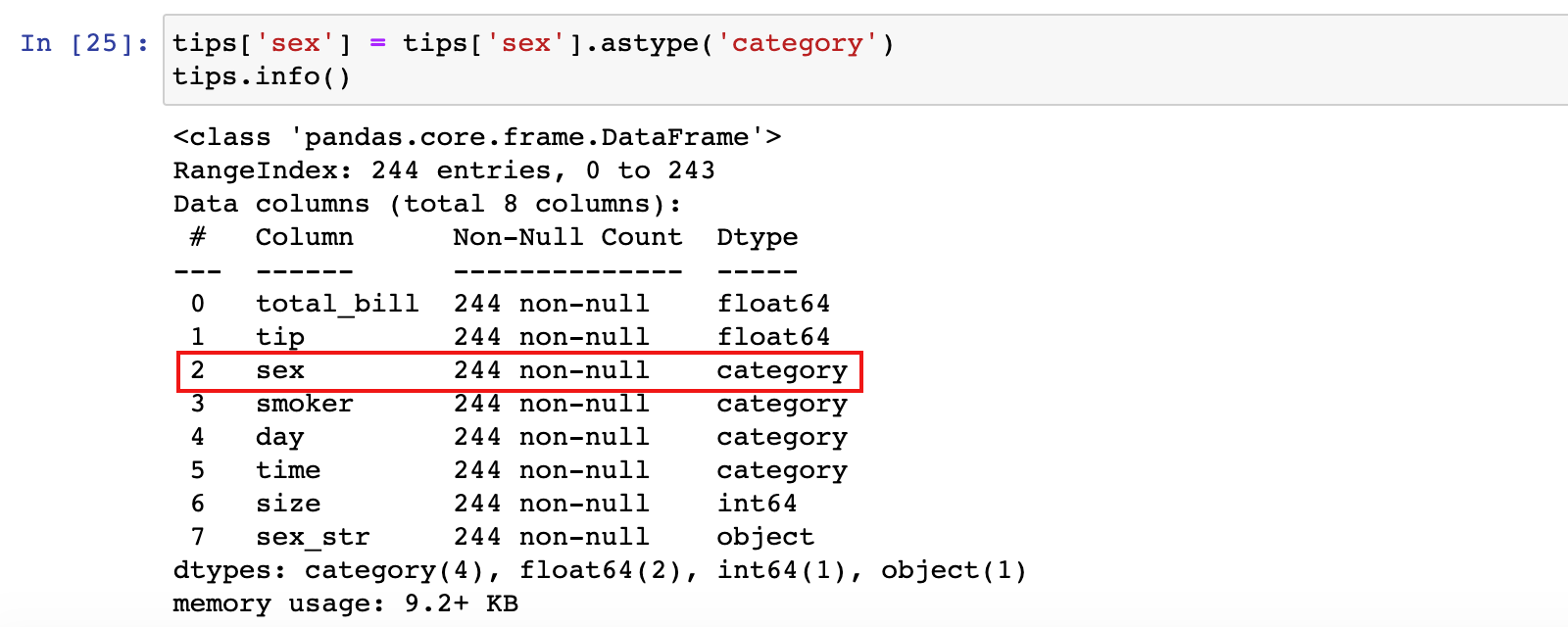
3.2 深入 category 数据类型
category 类型数据是由固定的且有限数量的变量组成的,比如:性别
1)通过 pd.Categorical 创建 category 类型数据,同时指定可选项
s = pd.Series(
pd.Categorical(['a', 'b', 'c', 'd'],
categories=['c', 'b', 'a'])
)
s

注意:不在 category 限定范围内的数据会被置为 NaN
2)通过 dtype 参数创建 category 类型数据
cat_series = pd.Series(['B', 'D', 'C', 'A'], dtype='category')
cat_series
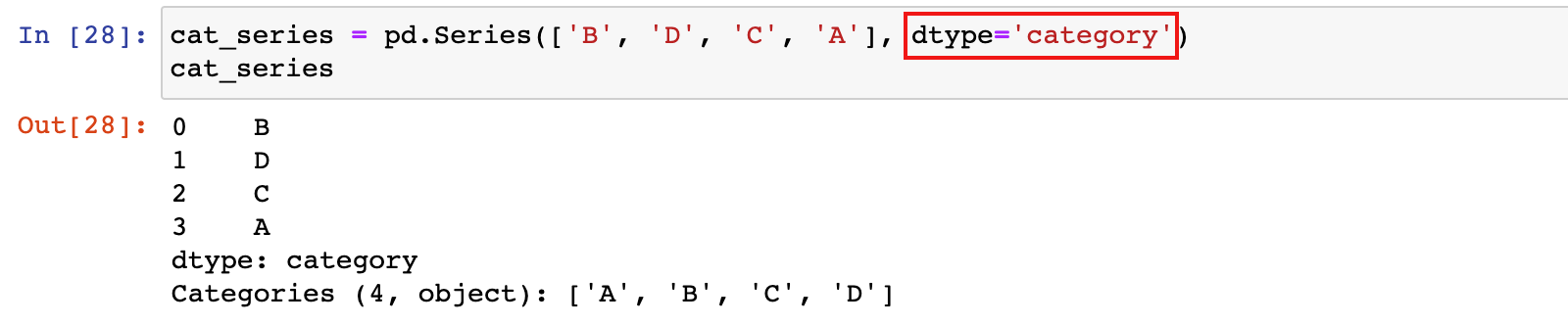
3)此时对数据进行排序
# 排序
cat_series.sort_values()

4)通过 CategoricalDtype 指定 category 数据的类型顺序
from pandas.api.types import CategoricalDtype
# 自定义一个有序的 category 类型
cat = CategoricalDtype(categories=['B', 'D', 'A', 'C'], ordered=True)
print(cat_series)
print('=' * 20)
print(cat_series.sort_values())
print('=' * 20)
print(cat_series.astype(cat).sort_values())
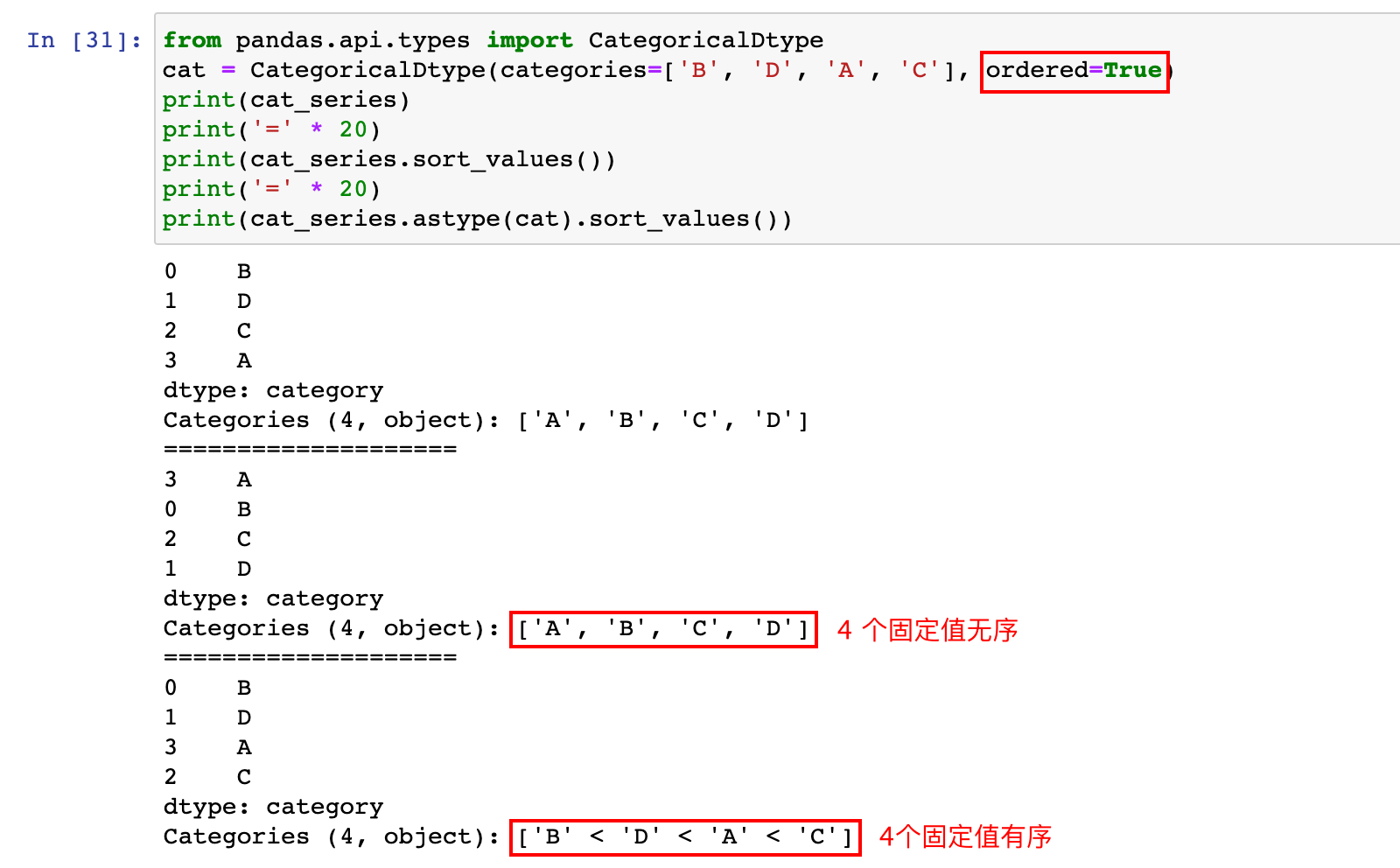
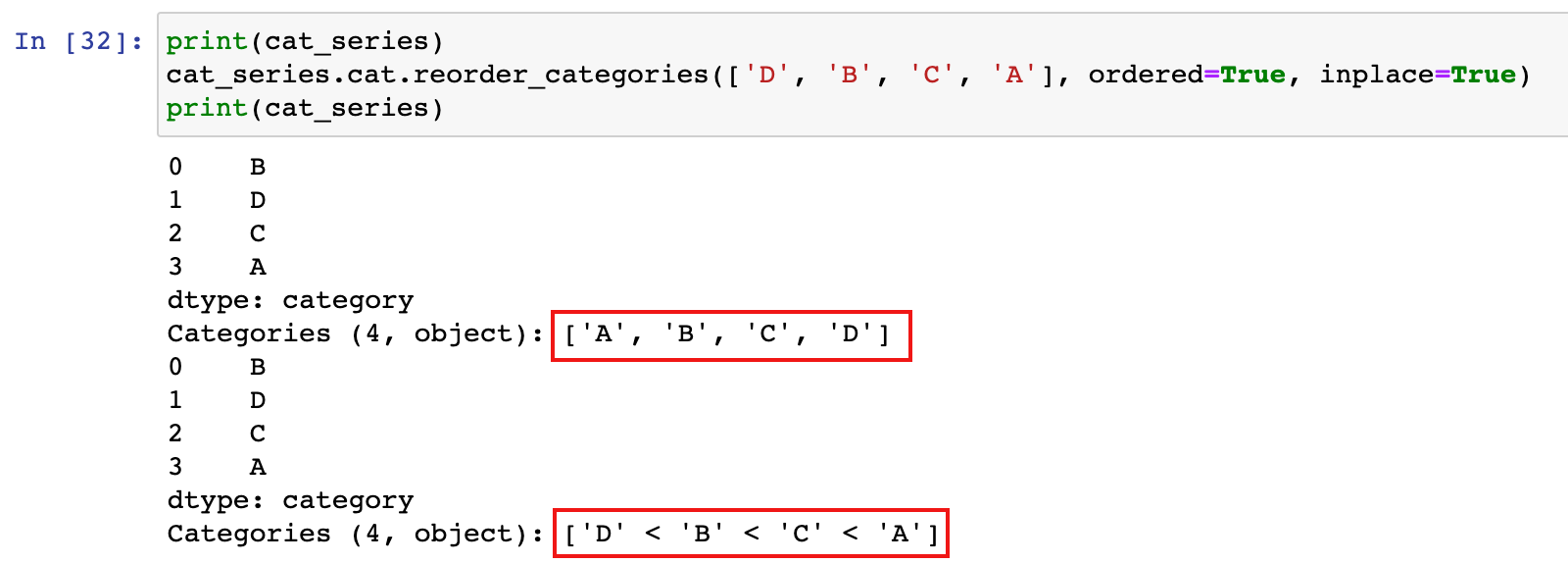
5)想要临时修改排序规则,可以使用categories类型的series对象.cat.reorder_categories()方法
print(cat_series)
cat_series.cat.reorder_categories(['D', 'B', 'C', 'A'], ordered=True, inplace=True)
print(cat_series)
总结
- Numpy 的特点
- Numpy 是一个高效科学计算库,pandas 的数据计算功能是对 Numpy 的封装
- ndarray 是 Numpy 的基本数据结构,pandas 的 Series 和 DataFrame 好多函数和属性都与 ndarray 一样
- Numpy 的计算效率比原生 Python 效率高很多,并且支持并行计算
- pandas 数据类型转换
- pandas 除了数值型的 int 和 float 类型外,还有object、category、bool、datetime类型
- 可以通过 as_type 和 to_numeric 函数进行数据类型转换
- pandas 分类数据类型
- category 类型,可以用来进行排序,并且可以自定义排序顺序
- CategoricalDtype 可以用来定义顺序