DataFrame增删改
学习目标
- 能够进行 DataFrame 的行操作(添加行/修改行/删除行)
- 能够进行 DataFrame 的列操作(添加列/修改列/删除列)
- 能够进行 DataFrame 的数据导出操作(pickle、csv、excel)
1. DataFrame 行操作
1.1 添加行
注意:添加行时,会返回新的 DataFrame。
基本格式:
| 方法 | 说明 |
|---|---|
df.append(other) |
向 DataFrame 末尾添加 other 新行数据,返回新的 DataFrame |
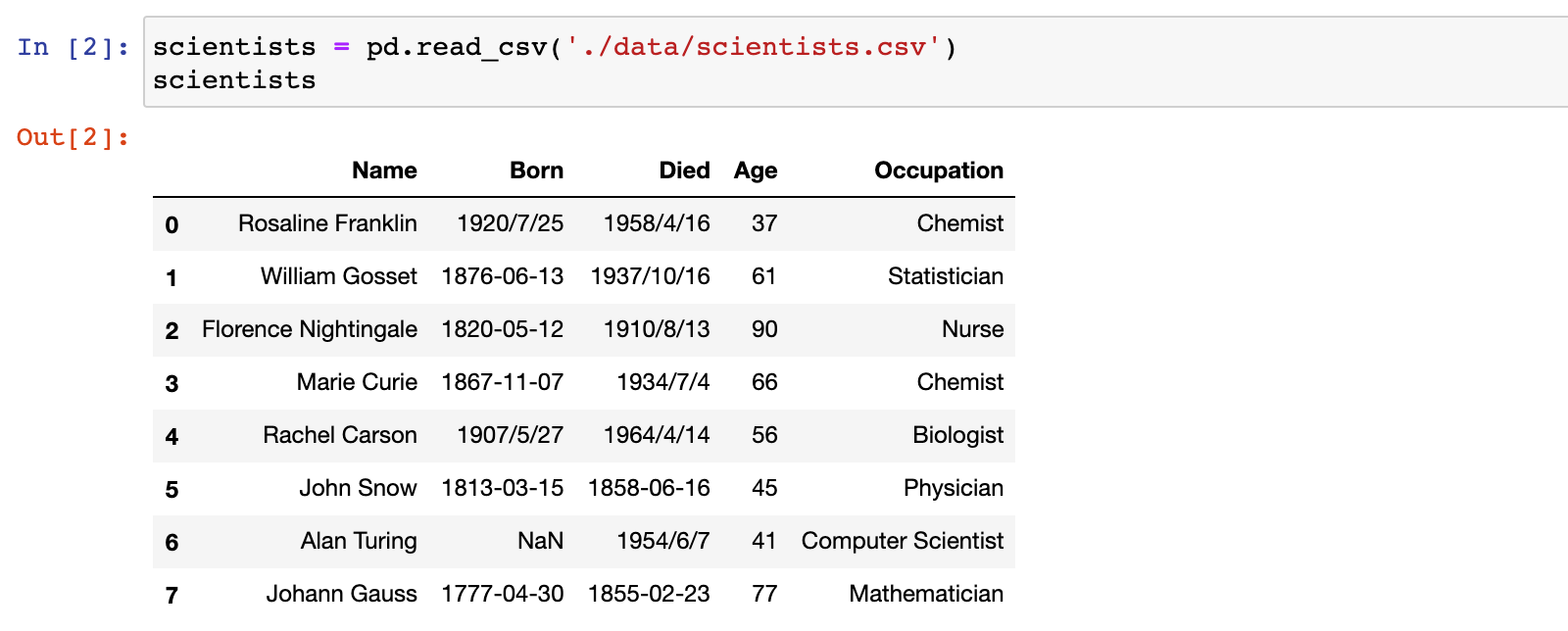
1)加载 scientists.csv 数据集
scientists = pd.read_csv('./data/scientists.csv')
scientists
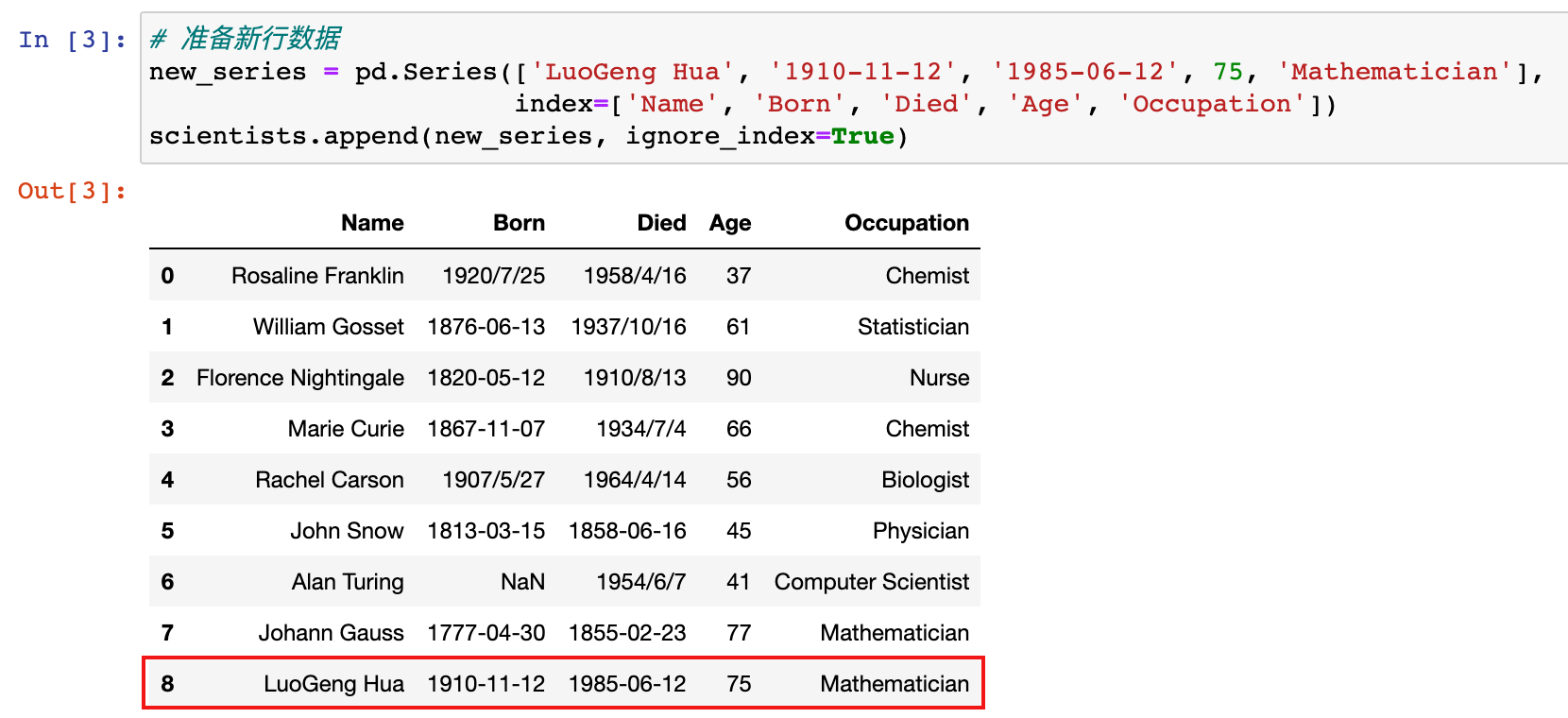
2)示例:在 scientists 数据末尾添加一行新数据
# 准备新行数据
new_series = pd.Series(['LuoGeng Hua', '1910-11-12', '1985-06-12', 75, 'Mathematician'],
index=['Name', 'Born', 'Died', 'Age', 'Occupation'])
scientists.append(new_series, ignore_index=True)
1.2 修改行
注意:修改行时,是直接对原始 DataFrame 进行修改。
基本格式:
| 方式 | 说明 |
|---|---|
df.loc[['行标签', ...],['列标签', ...]] |
修改行标签对应行的对应列的数据 |
df.iloc[['行位置', ...],['列位置', ...]] |
修改行位置对应行的对应列的数据 |
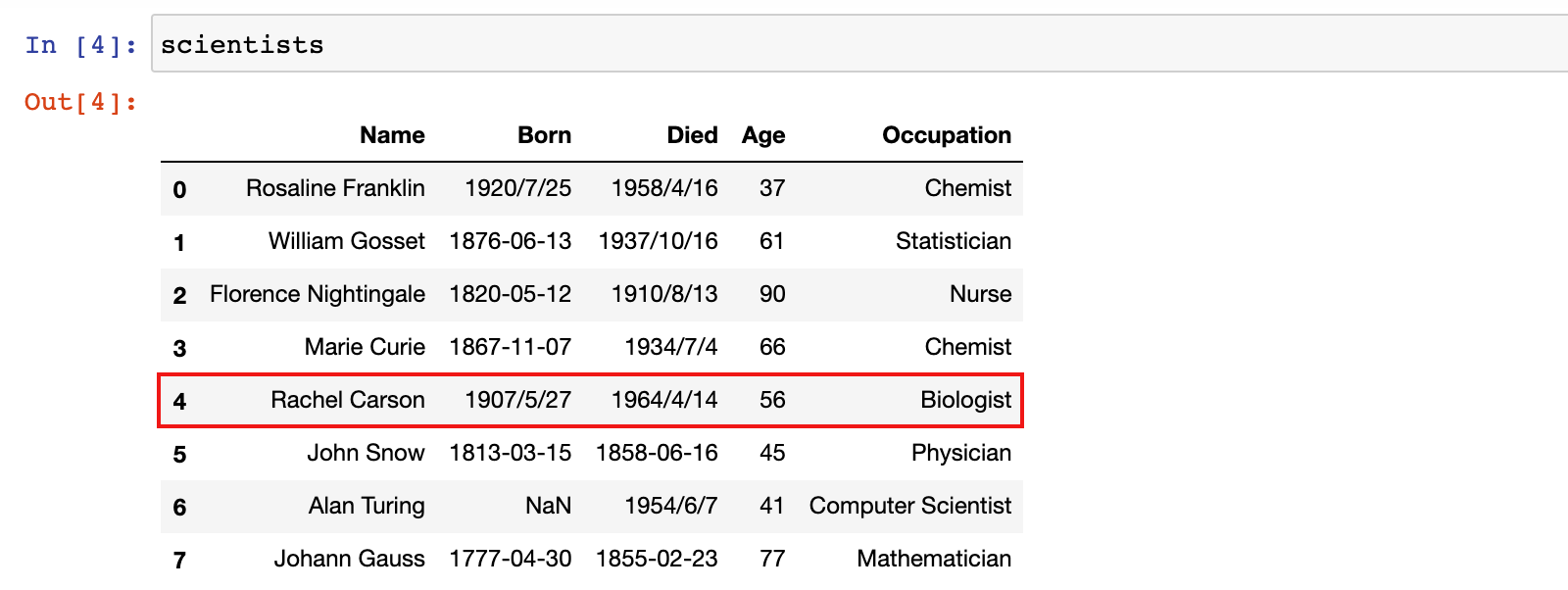
1)示例:修改行标签为 4 的行的所有数据
修改之前:
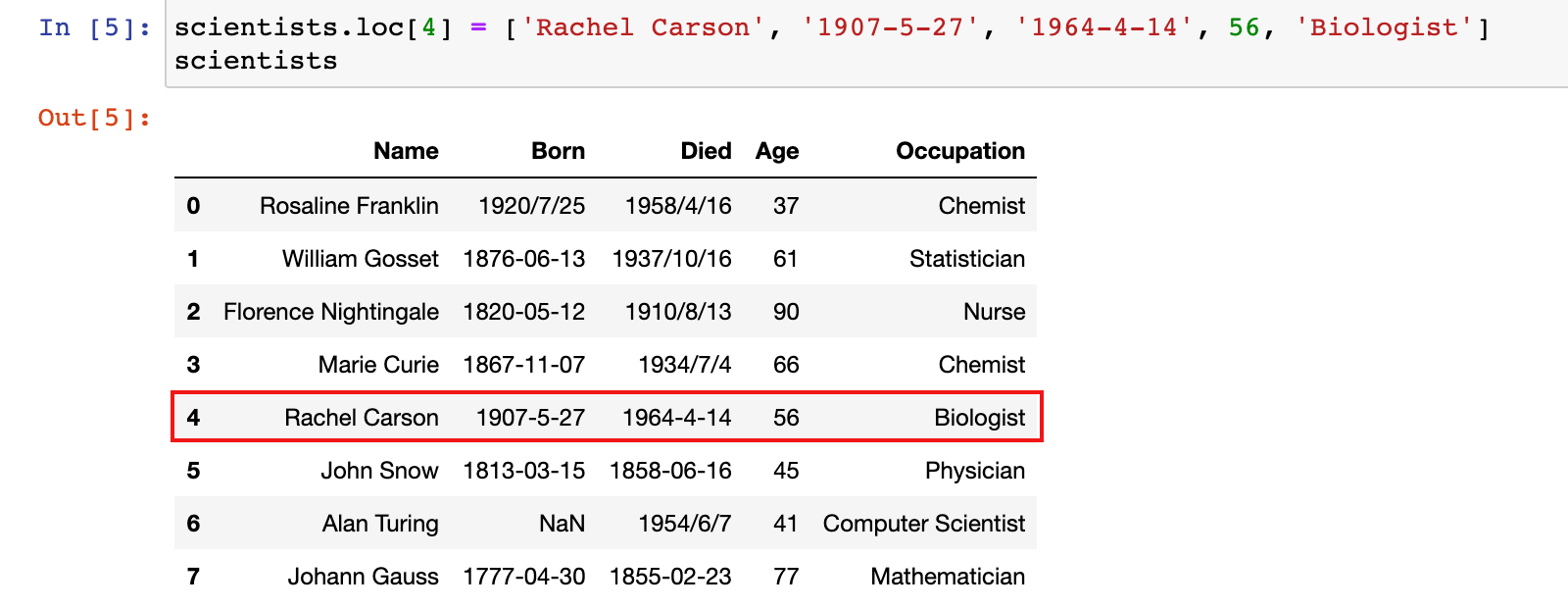
修改之后:
scientists.loc[4] = ['Rachel Carson', '1907-5-27', '1964-4-14', 56, 'Biologist']
scientists
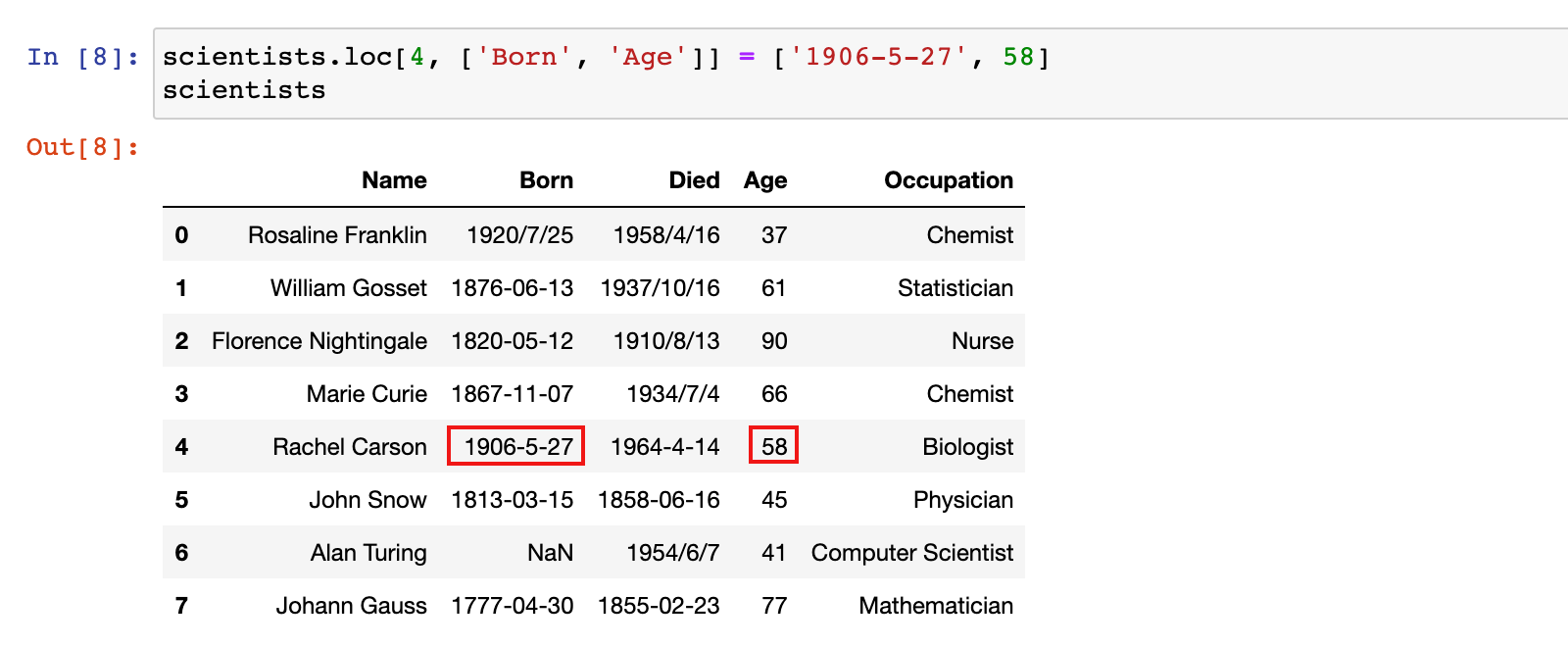
2)示例:修改行标签为 4 的行的 Born 和 Age 列的数据
scientists.loc[4, ['Born', 'Age']] = ['1906-5-27', 58]
scientists
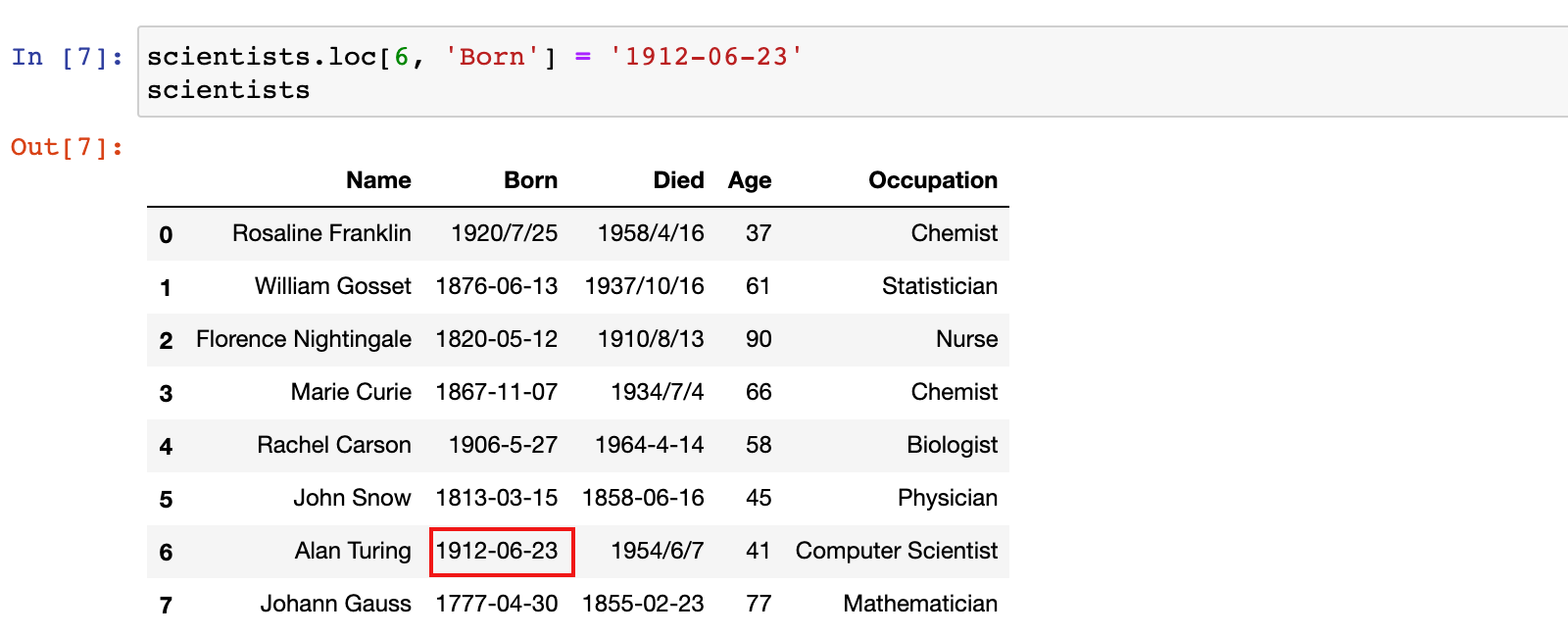
3)示例:修改行标签为 6 的行的 Born 列的数据为 1912-06-23
scientists.loc[6, 'Born'] = '1912-06-23'
scientists
1.3 删除行
注意:删除行时,会返回新的 DataFrame。
基本格式:
| 方式 | 说明 |
|---|---|
df.drop(['行标签', ...]) |
删除行标签对应行的数据,返回新的 DataFrame |
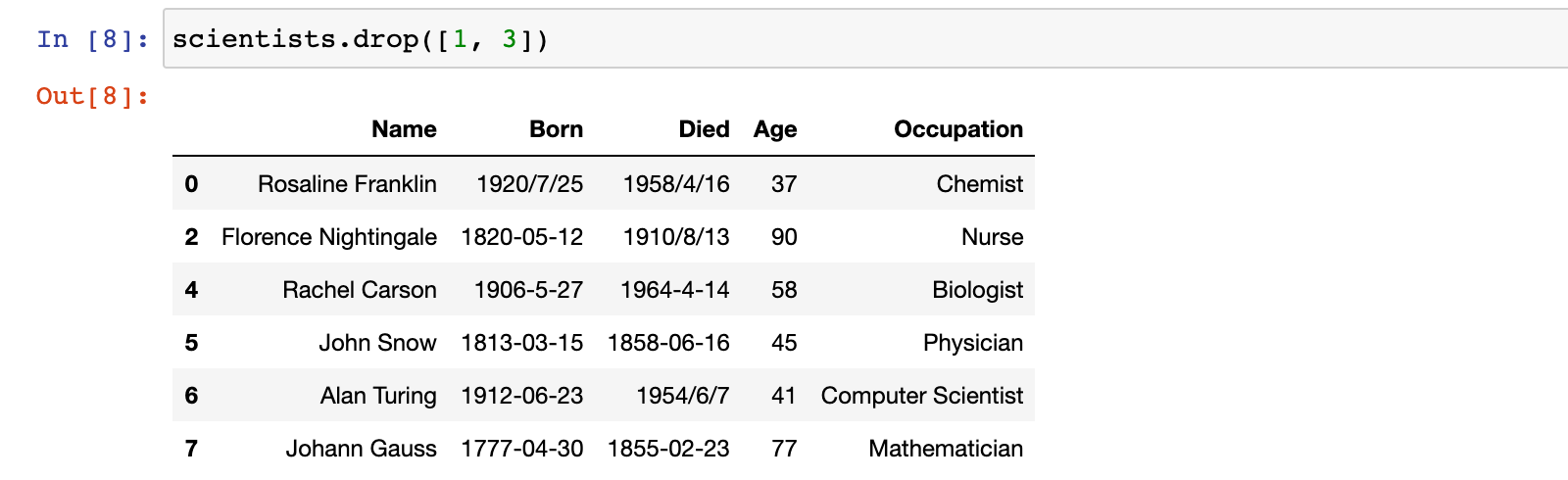
1)示例:删除行标签为 1 和 3 的行
scientists.drop([1, 3])
2. DataFrame 列操作
2.1 新增列/修改列
注意:添加列/修改列时,是直接对原始 DataFrame 进行修改。
基本格式:
| 方式 | 说明 |
|---|---|
df['列标签']=新列 |
1)如果 DataFrame 中不存在对应的列,则在 DataFrame 最右侧增加新列 2)如果 DataFrame 中存在对应的列,则修改 DataFrame 中该列的数据 |
df.loc[:, 列标签]=新列 |
1)如果 DataFrame 中不存在对应的列,则在 DataFrame 最右侧增加新列 2)如果 DataFrame 中存在对应的列,则修改 DataFrame 中该列的数据 |
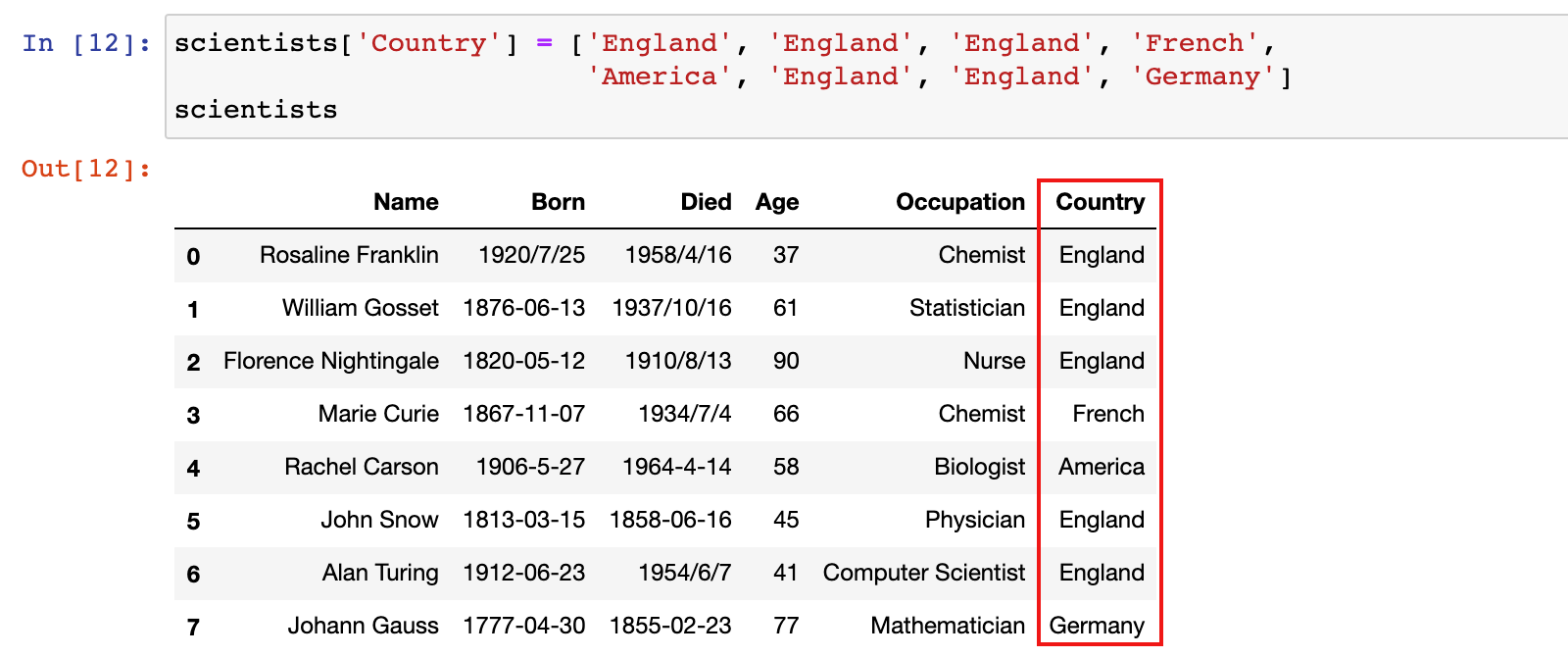
1)示例:给 scientists 数据增加一个 Country 列
scientists['Country'] = ['England', 'England', 'England', 'French',
'America', 'England', 'England', 'Germany']
或
scientists.loc[:, 'Country'] = ['England', 'England', 'England', 'French',
'America', 'England', 'England', 'Germany']
scientists
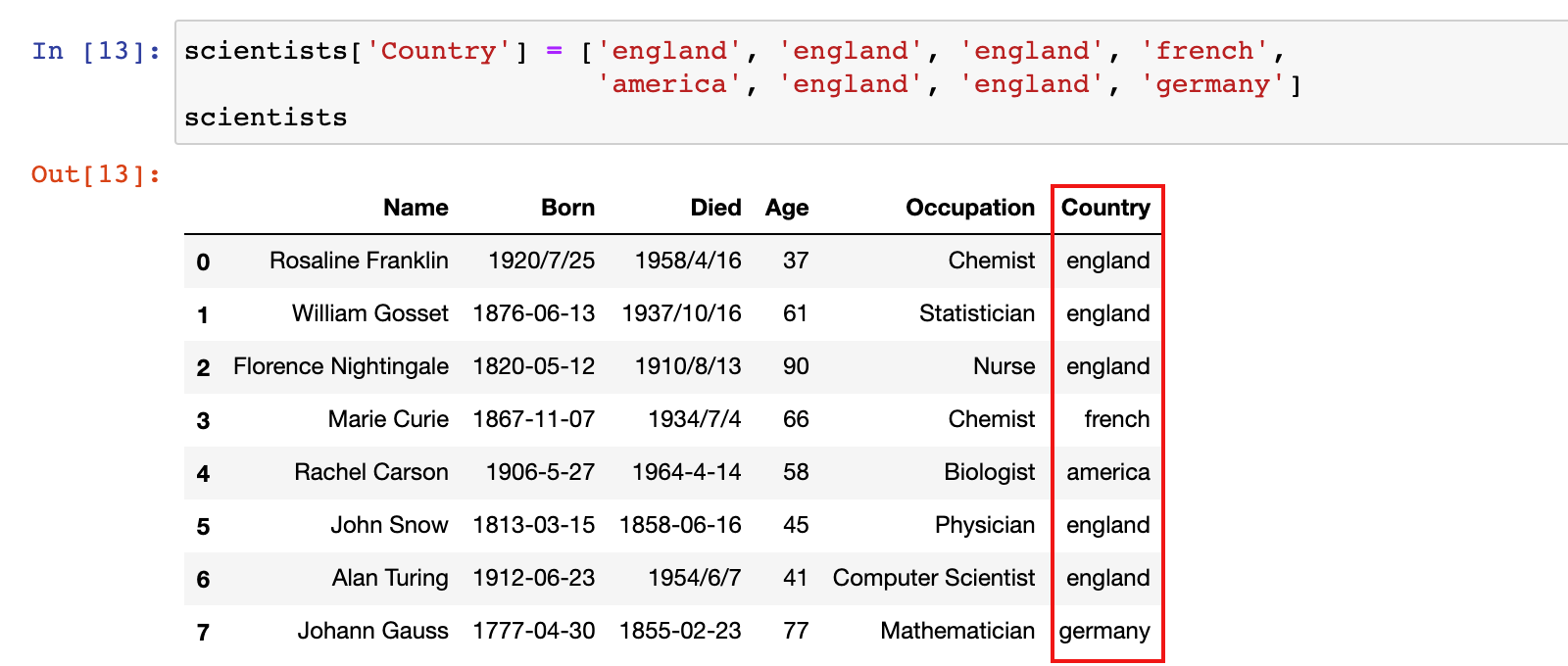
3)示例:修改 scientists 数据中 Country 列的数据
scientists['Country'] = ['england', 'england', 'england', 'french',
'america', 'england', 'england', 'germany']
或
scientists.loc[:, 'Country'] = ['england', 'england', 'england', 'french',
'america', 'england', 'england', 'germany']
scientists
2.2 删除列
注意:删除列时,会返回新的 DataFrame。
基本格式:
| 方式 | 说明 |
|---|---|
df.drop(['列标签', ...], axis=1) |
删除列标签对应的列数据,返回新的 DataFrame |
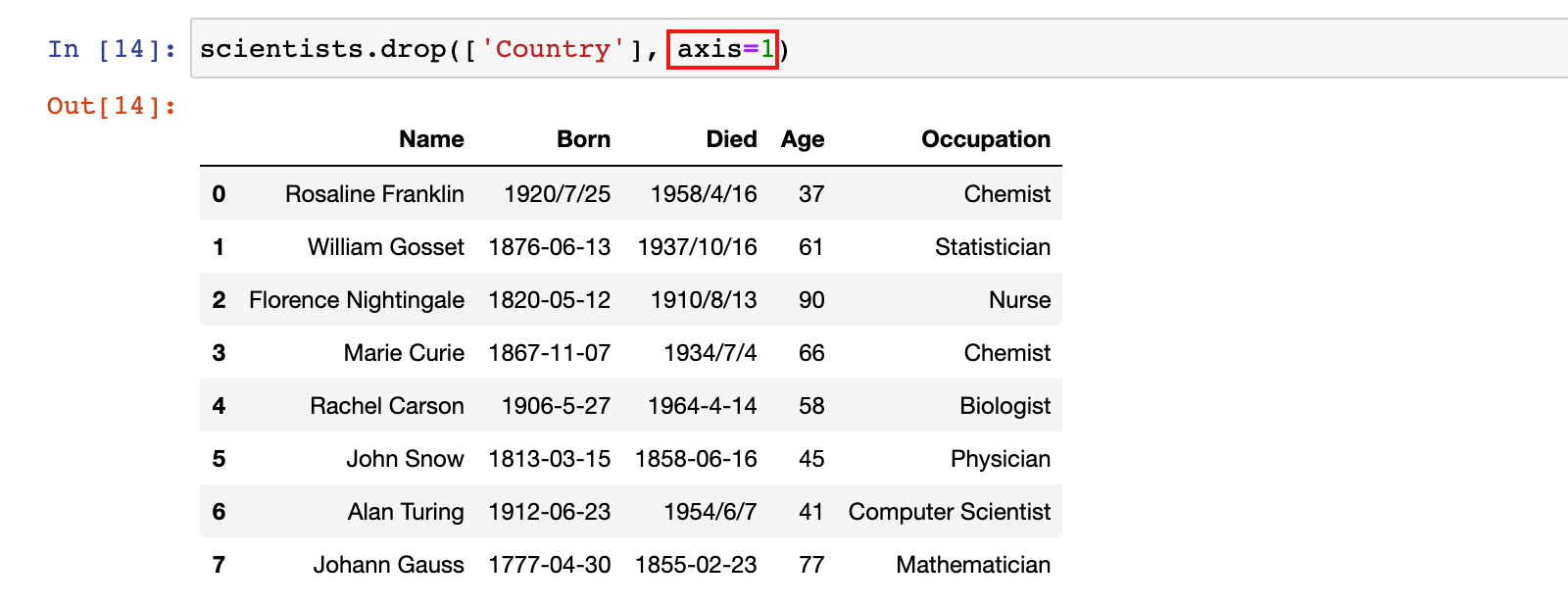
1)示例:删除 scientists 数据中 Country 列的数据
scientists.drop(['Country'], axis=1)
3. DataFrame 数据导出和导入
3.1 Pickle 文件
导出到pickle文件:
- 调用to_pickle方法将以二进制格式保存数据
- 如要保存的对象是计算的中间结果,或者保存的对象以后会在Python中复用,可把对象保存为.pickle文件
- 如果保存成pickle文件,只能在python中使用
- 文件的扩展名可以是.p、.pkl、.pickle
scientists = pd.read_csv('data/scientists.csv')
scientists.to_pickle('./data/scientists_df.pickle')
读取pickle文件:
可以使用pd.read_pickle函数读取.pickle文件中的数据
scientists_df = pd.read_pickle('./data/scientists_df.pickle')
scientists_df
3.2 CSV 文件
我们用pd.read_csv()函数读取csv文件,使用df.to_csv()将数据保存为csv文件
- 在CSV文件中,对于每一行,各列采用逗号分隔;使用
\n换行符换行 - 除了逗号,还可以使用其他类型的分隔符,比如TSV文件,使用制表符作为分隔符
- CSV是数据协作和共享的首选格式,因为可以使用excel打开
# TSV文件,设置分隔符必须为\t
scientists.to_csv('./data/scientists_df.tsv', sep='\t')
# 不在csv文件中存入行标签
scientists.to_csv('./data/scientists_df_noindex.csv', index=False)
3.3 Excel文件
注意:根据anaconda的版本不同,pandas读写excel有时需要额外安装
xlwt、xlrd、openpyxl三个包pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xlwt pip install -i https://pypi.tuna.tsinghua.edu.cn/simple openpyxl pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xlrd
导出成Excel文件:
scientists.to_excel('./data/scientists_df.xlsx', sheet_name='scientists', index=False)
读取Excel文件:
使用pd.read_excel() 读取Excel文件
pd.read_excel('./data/scientists_df.xlsx')
3.4 【了解】feather格式文件
- feather是一种文件格式,用于存储二进制对象
- feather对象也可以加载到R语言中使用
- feather格式的主要优点是在Python和R语言之间的读写速度要比CSV文件快
- feather数据格式通常只用中间数据格式,用于Python和R之间传递数据
- 一般不用做保存最终数据
3.5 【了解】数据导出的其他方法
其他导出方法清单:
| 导出方法 | 说明 |
|---|---|
| to_clipboard | 把数据保存到系统剪贴板,方便粘贴 |
| to_dict | 把数据转换成Python字典 |
| to_hdf | 把数据保存为HDF格式 |
| to_html | 把数据转换成HTML |
| to_json | 把数据转换成JSON字符串 |
| to_sql | 把数据保存到SQL数据库 |
总结
- 能够进行 DataFrame 的行操作(添加行/修改行/删除行)
- 能够进行 DataFrame 的列操作(添加列/修改列/删除列)
- 能够进行 DataFrame 的数据导出操作(pickle、csv、excel)
- to_pickle、read_pickle
- to_csv、read_csv
- to_excel、read_excel