如何使用python处理csv文件
素材准备
csv⽂件其实就是⽂本⽂件,遵循了⼀定的格式,常⻅的csv⽂件⼀般是⽤逗号来隔开列,⽤换⾏符隔开不同的⾏,注意这⾥的符号都是英⽂符号。我们可以直接⽤open函数来打开csv⽂件;
本实验使用csv文件(example.csv)分享:https://osswangting.oss-cn-shanghai.aliyuncs.com/python/example.csv
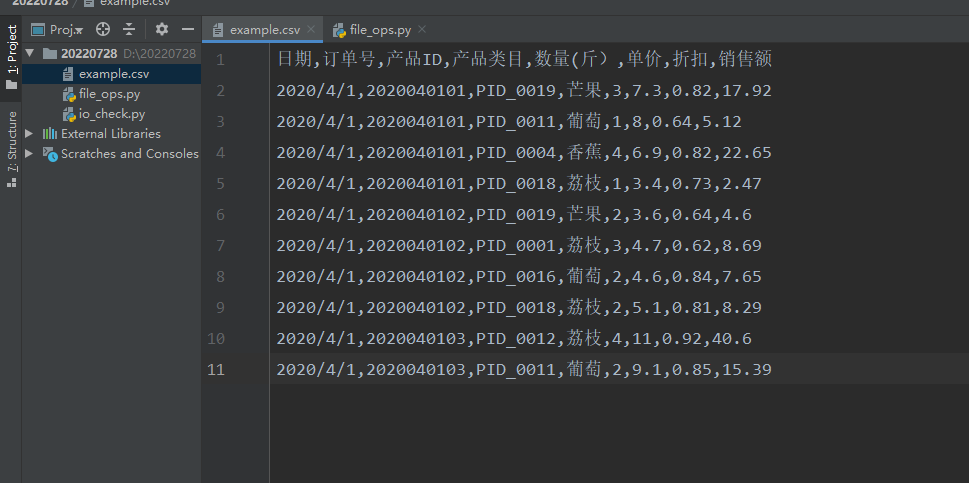
例如我们用文本编辑器打开csv文件时看到的内容一般为逗号分隔的纯文本文件:
日期,订单号,产品ID,产品类目,数量(斤),单价,折扣,销售额2020/4/1,2020040101,PID_0019,芒果,3,7.3,0.82,17.922020/4/1,2020040101,PID_0011,葡萄,1,8,0.64,5.122020/4/1,2020040101,PID_0004,香蕉,4,6.9,0.82,22.652020/4/1,2020040101,PID_0018,荔枝,1,3.4,0.73,2.472020/4/1,2020040102,PID_0019,芒果,2,3.6,0.64,4.62020/4/1,2020040102,PID_0001,荔枝,3,4.7,0.62,8.692020/4/1,2020040102,PID_0016,葡萄,2,4.6,0.84,7.652020/4/1,2020040102,PID_0018,荔枝,2,5.1,0.81,8.292020/4/1,2020040103,PID_0012,荔枝,4,11,0.92,40.62020/4/1,2020040103,PID_0011,葡萄,2,9.1,0.85,15.39
最基本方式打开csv
使用python代码打开一个csv文件基本形式:
代码:
xxxxxxxxxxwith open('./example.csv', 'r') as f: for line in f.readlines(): print(line)提示报错:
Traceback (most recent call last): File "D:/20220728/file_ops.py", line 2, in
for line in f.readlines(): UnicodeDecodeError: 'gbk' codec can't decode byte 0xb7 in position 15: illegal multibyte sequence 以只读方式打开时除了指定模式为"r"之外还有指定在python中以要打开的文件的编码相同的方式打开,也就是让python不以默认的 gbk方式打开,而是以我们指定的 utf-8 打开( encoding='utf-8' )
如果要保存的内容有中文,而且之后需要用Excel打开文件,那么需要选用
utf-8-sig编码。如果使用utf-8编码,会导致使用Excel查看文件时中文乱码
代码迭代:
xxxxxxxxxxwith open('./example.csv', 'r', encoding='utf-8') as f: for line in f.readlines(): print(line)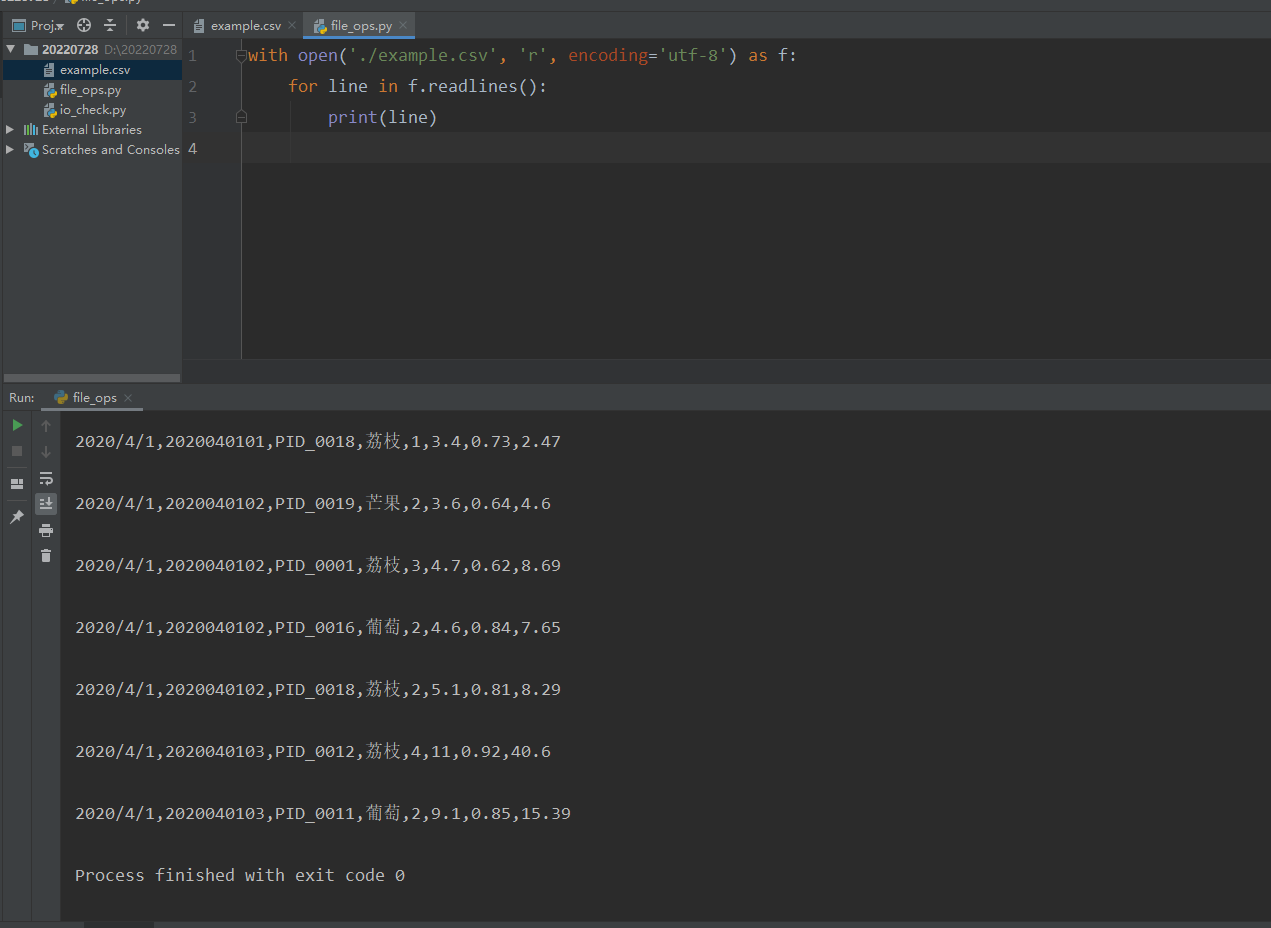
此时python代码成功将csv文件内容读取并输出到控制台
注意:文本内容都是以逗号来区分字段,但如果出现一个字段中有逗号符时,那么则会出现错列的情况,为了避免错列的情况发生,我们则需要在同一字段或同一列内容出现逗号时,用引号引起来规避这样的问题发生。
例如文中的:( 葡萄 ),如果文件中内容是( 葡,萄 ),那么( 葡,萄 )默认会别识别成2列,所以需要修改成( "葡,萄" ),则才可以识别成一列内容。
使用csv模块读取文件
Python库:csv Python中集成了专用于处理csv文件的库,名为:csv。
csv 库中有4个常用的对象:
- csv.reader:以列表的形式返回读取的数据。
- csv.writer:以列表的形式写入数据。
- csv.DictReader:以字典的形式返回读取的数据
- csv.DictWriter:以字典的形式写入数据
读取方法1-代码:
ximport csv
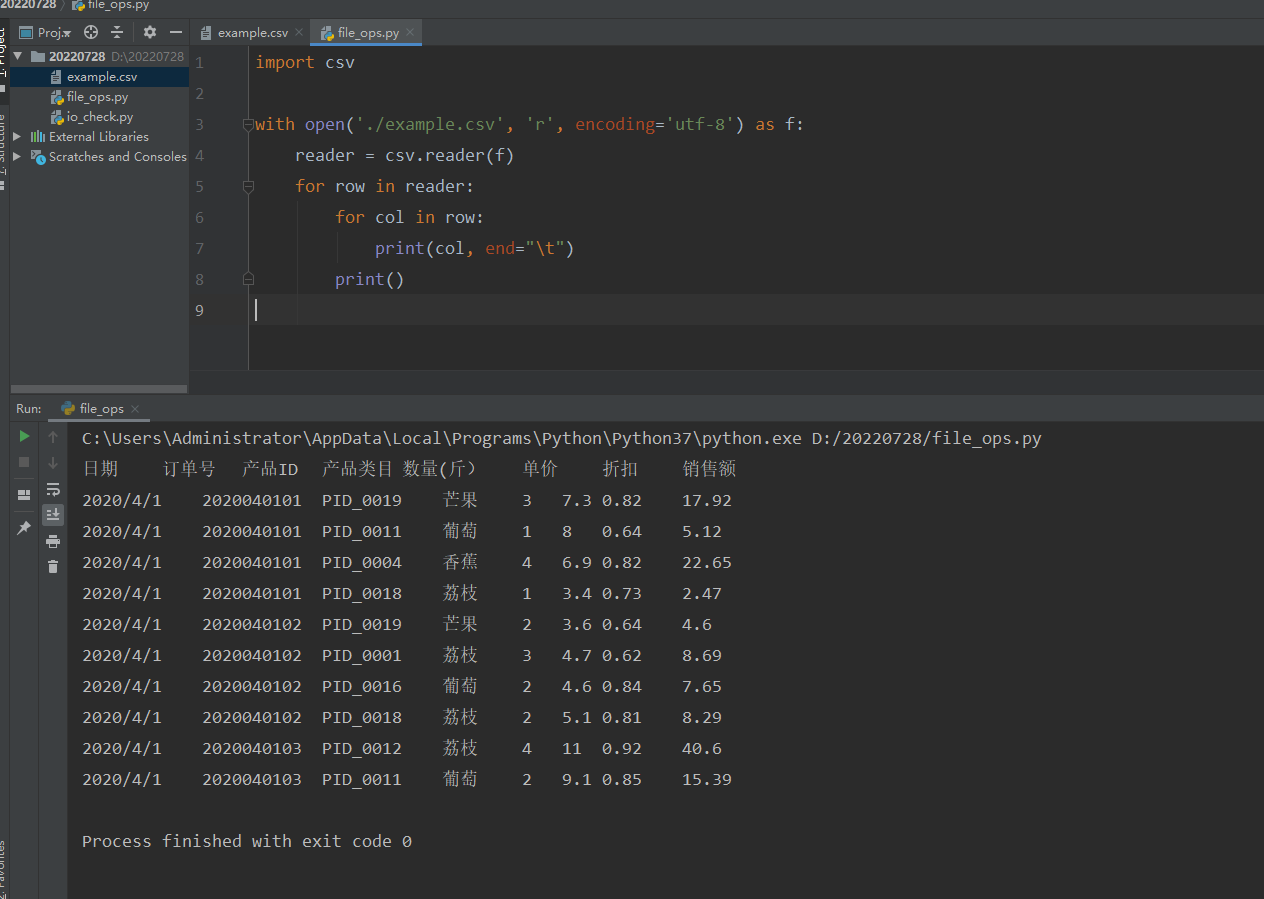
with open('./example.csv', 'r', encoding='utf-8') as f: reader = csv.reader(f) for row in reader: for col in row: print(col, end="\t") print()csv.reader(f)
reader() 按⾏读取,每⼀⾏是⼀个列表,reader是列表对象
一个元素为:['日期', '订单号', '产品ID', '产品类目', '数量(斤)', '单价', '折扣', '销售额']
所以遍历去获取其中的每一个字段
这种方法有一个缺点是一行一行整行取,不够灵活
读取方法2-代码:
xxxxxxxxxximport csv
with open('./example.csv', 'r', encoding='utf-8') as f: reader = csv.DictReader(f) for row in reader: print(row['产品类目'], row['销售额'])csv.DictReader(f)
字典对象
通过取key键来获取对应的值,key相当于字段名
使用csv模块写入文件
写入方法1-代码:
xxxxxxxxxximport csvsales = ( ("Peter", (78, 70, 65)), ("John", (88, 80, 85)), ("Tony", (90, 99, 95)), ("Henry", (80, 70, 55)), ("Mike", (95, 90, 95)),)with open('./sales.csv', 'w', newline="") as f: writer = csv.writer(f) writer.writerow(['name', 'Jan', 'Feb', 'Mar']) for name, qa in sales: writer.writerow([name, qa[0], qa[1], qa[2]]) # writer.writerow([name, *qa]) 等同于上方writerow()一次只能写入一行
如果使用writerows()一次可以写入多行
注意:, newline=""参数加入后,可以让表格数据行之间没有空白行,不加否则每行数据中间都会有一行空白行
写入方法2-代码:
xxxxxxxxxximport csv
sales = ( ("Peter", (78, 70, 65)), ("John", (88, 80, 85)), ("Tony", (90, 99, 95)), ("Henry", (80, 70, 55)), ("Mike", (95, 90, 95)),)
data = [{'name': name, 'amount': sum(qa)} for name, qa in sales]with open('./sales2.csv', 'w', newline="") as f: fieldnames = ['name', 'amount'] writer = csv.DictWriter(f, fieldnames) writer.writeheader() for row in data: writer.writerow(row)读取csv文件(使用pandas模块)
代码:
xxxxxxxxxximport pandas as pd
data = pd.read_csv('./example.csv')print(data)
csv文件内容去重(使用pandas模块)
xxxxxxxxxxpip install pandas
本实验使用csv文件(example.csv)分享:https://osswangting.oss-cn-shanghai.aliyuncs.com/python/example.csv
主要使用pandas模块中涉及的drop_duplicates()函数
| 参数 | 说明 |
|---|---|
| subset | 根据指定的列名进行去重,默认整个数据集 |
| keep | 可选{‘first’, ‘last’, False},默认first,即默认保留第一次出现的重复值,并删去其他重复的数据,False是指删去所有重复数据。 |
| inplace | 是否对数据集本身进行修改,默认False |
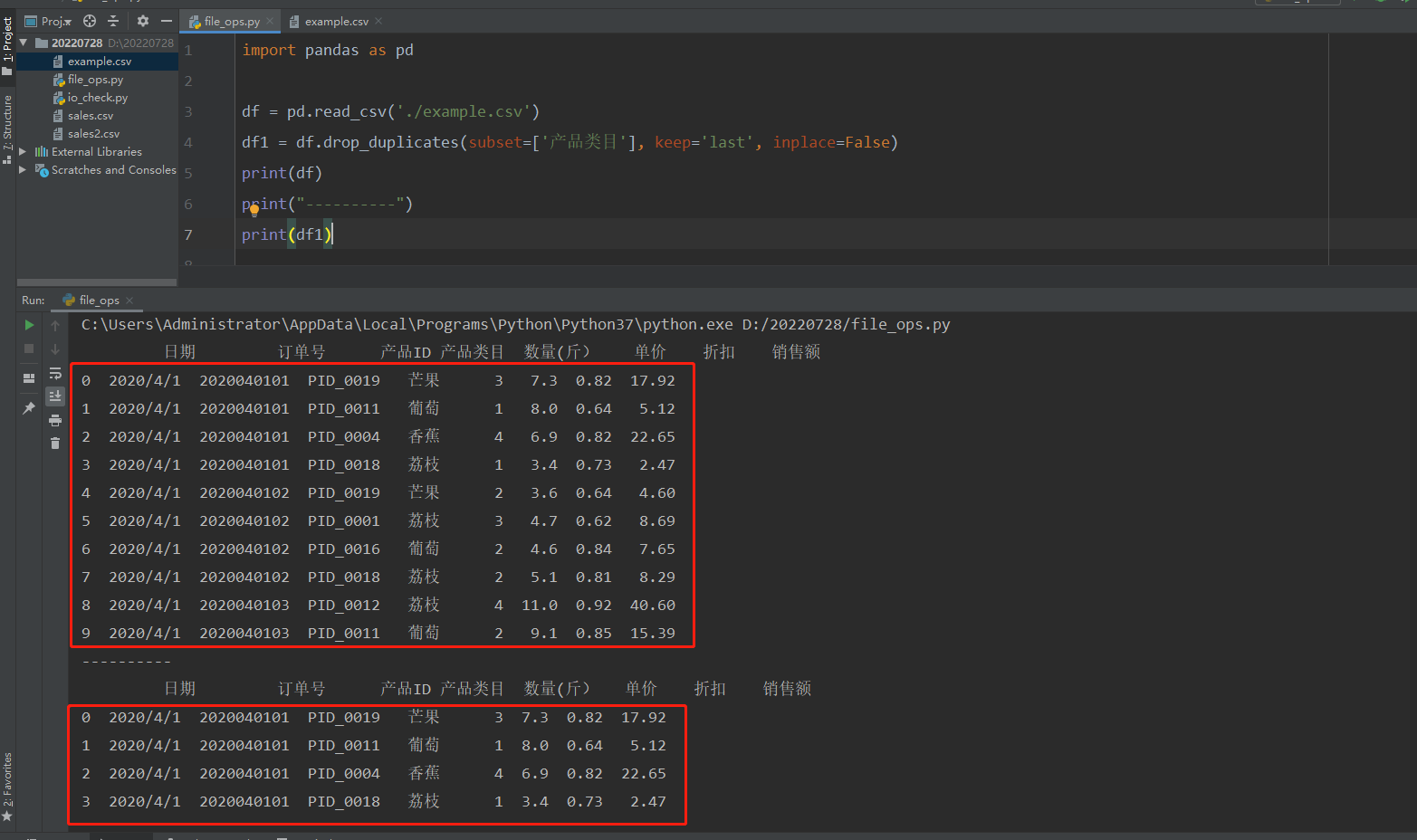
xxxxxxxxxximport pandas as pd
df = pd.read_csv('./example.csv')df1 = df.drop_duplicates(subset=['产品类目'], keep='last', inplace=False)print(df)print("----------")print(df1)代码中subset对应的值是列名,表示根据什么列来去重,可以多列去重 默认值为subset=None表示考虑所有列
keep='first'表示保留第一次出现的重复行,是默认值。keep另外两个取值为"last"和False,分别表示保留最后一次出现的重复行和去除所有重复行。
inplace=True表示直接在原来的DataFrame上删除重复项,而默认值False表示生成一个副本
删除csv文件行与列(使用pandas模块)
原文件内容:
xxxxxxxxxx日期 订单号 产品ID 产品类目 数量(斤) 单价 折扣 销售额0 2020/4/1 2020040101 PID_0019 芒果 3 7.3 0.82 17.921 2020/4/1 2020040101 PID_0011 葡萄 1 8.0 0.64 5.122 2020/4/1 2020040101 PID_0004 香蕉 4 6.9 0.82 22.653 2020/4/1 2020040101 PID_0018 荔枝 1 3.4 0.73 2.474 2020/4/1 2020040102 PID_0019 芒果 2 3.6 0.64 4.605 2020/4/1 2020040102 PID_0001 荔枝 3 4.7 0.62 8.696 2020/4/1 2020040102 PID_0016 葡萄 2 4.6 0.84 7.657 2020/4/1 2020040102 PID_0018 荔枝 2 5.1 0.81 8.298 2020/4/1 2020040103 PID_0012 荔枝 4 11.0 0.92 40.609 2020/4/1 2020040103 PID_0011 葡萄 2 9.1 0.85 15.39
- 删除列
xxxxxxxxxximport pandas as pd
data = pd.read_csv('./example.csv')data_new = data.drop(['日期', '订单号', '产品ID'], axis=1)print(data_new)- 删除行
xxxxxxxxxximport pandas as pd
data = pd.read_csv('./example.csv')data_new = data.drop([0, 1, 2, 3])print(data_new)- 生成的文件写入新文件
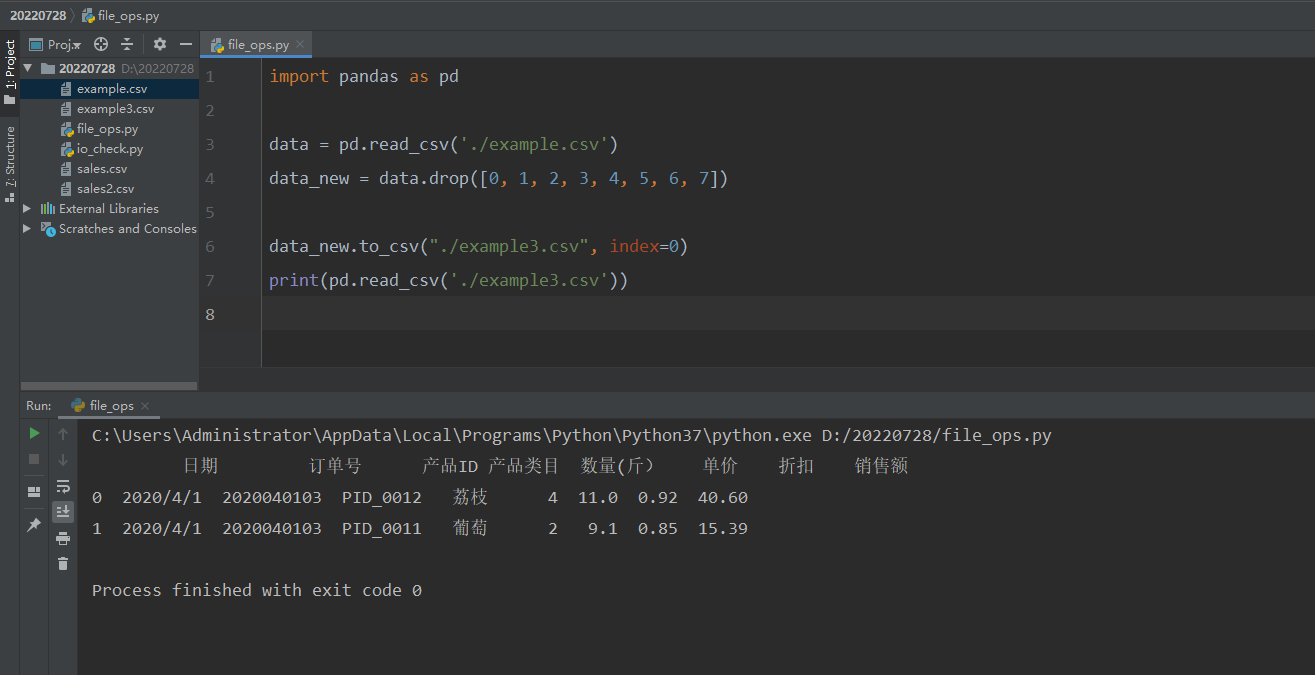
xxxxxxxxxximport pandas as pd
data = pd.read_csv('./example.csv')data_new = data.drop([0, 1, 2, 3, 4, 5, 6, 7])
data_new.to_csv("./example3.csv", index=0)print(pd.read_csv('./example3.csv'))